latent diffusion segmentation
1.0.0
此儲存庫包含 LDMSeg 的 Pytorch 實作:一種用於全景分割和掩模修復的簡單潛在擴散方法。提供的代碼包括培訓和評估。
用於全景分割和掩模修復的簡單潛在擴散方法
沃特·範·甘斯貝克和伯特·德·布拉班代爾
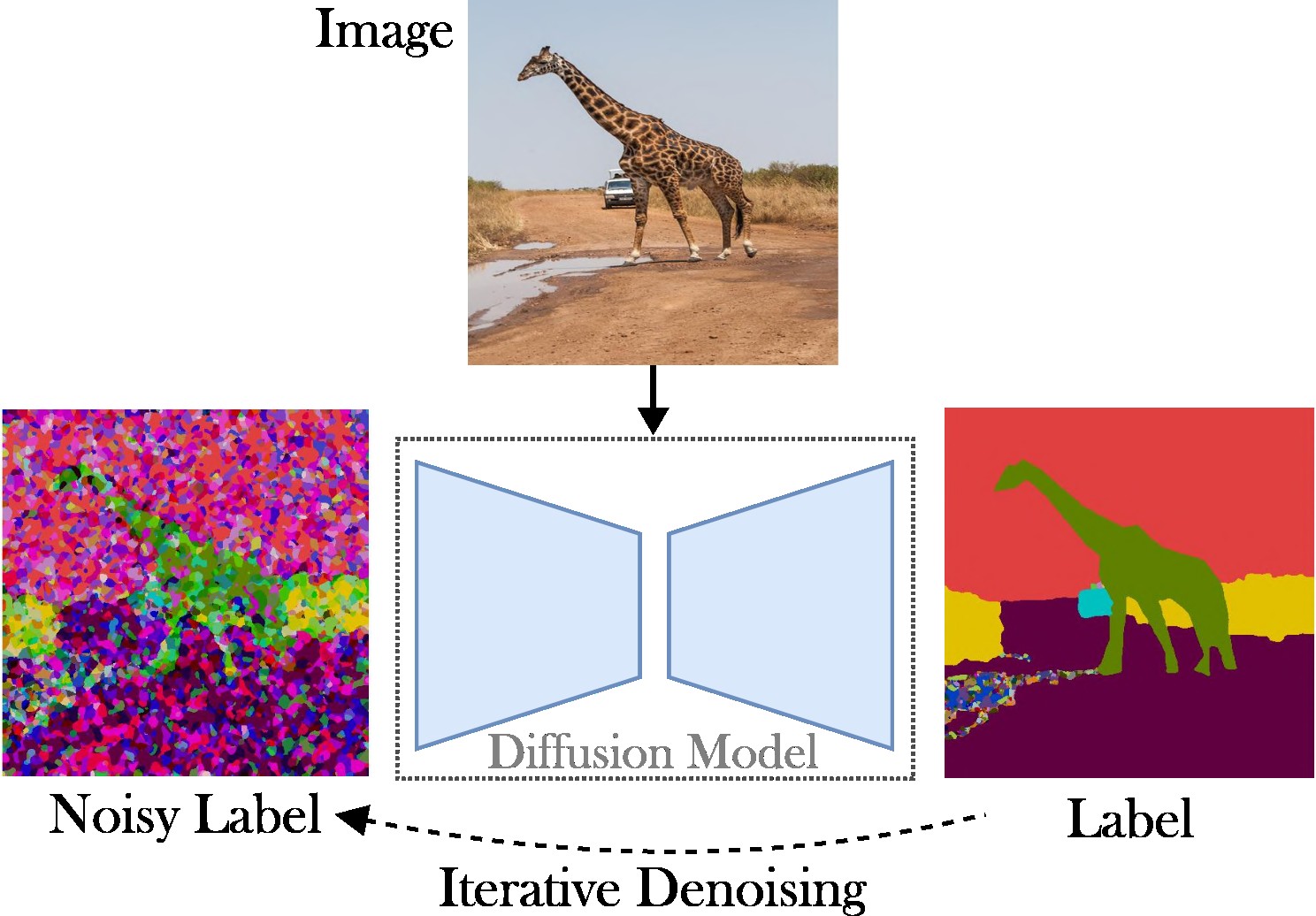
本文提出了一種條件潛在擴散方法來解決全景分割的任務。目的是省略對專門架構(例如,區域提議網路或物件查詢)、複雜損失函數(例如,匈牙利匹配或基於邊界框)以及其他後處理方法(例如,聚類、NMS)的需求。 )。因此,我們依賴穩定擴散,這是一個與任務無關的框架。所提出的方法包括兩個步驟:(1)使用淺層自動編碼器將全景分割遮罩投影到潛在空間; (2) 以 RGB 影像為條件,在潛在空間中訓練擴散模型。
主要貢獻:我們的貢獻有三重:
該程式碼可在最新的 Pytorch 版本上運行,例如 2.0。此外,您可以使用 Anaconda 建立 python 環境:
conda create -n LDMSeg python=3.11
conda activate LDMSeg
我們建議遵循自動安裝(請參閱tools/scripts/install_env.sh )。執行以下命令以可編輯模式安裝項目。請注意,所有依賴項都會自動安裝。由於這可能並不總是有效(例如,由於 CUDA 或 gcc 問題),請查看手動安裝步驟。
python -m pip install -e .
pip install git+https://github.com/facebookresearch/detectron2.git
pip install git+https://github.com/cocodataset/panopticapi.git最重要的軟體包可以使用 pip 快速安裝,如下所示:
pip install torch torchvision einops # Main framework
pip install diffusers transformers xformers accelerate timm # For using pretrained models
pip install scipy opencv-python # For augmentations or loss
pip install pyyaml easydict hydra-core # For using config files
pip install termcolor wandb # For printing and logging請參閱data/environment.yml以取得我的環境的副本。我們也依賴 detectorron2 和 panopticapi 的一些依賴項。請遵循他們的文檔。
我們目前支援 COCO 資料集。請依照文件安裝影像及其對應的全景分割蒙版。另外,請查看ldmseg/data/目錄,以了解 COCO 資料集上的一些範例。順便說一句,所採用的結構應該是相當標準的:
.
└── coco
├── annotations
├── panoptic_semseg_train2017
├── panoptic_semseg_val2017
├── panoptic_train2017 -> annotations/panoptic_train2017
├── panoptic_val2017 -> annotations/panoptic_val2017
├── test2017
├── train2017
└── val2017
最後但並非最不重要的一點是,將configs/env/root_paths.yml中的路徑分別更改為資料集根目錄和所需的輸出目錄。
所提出的方法是雙管齊下的:首先,我們訓練一個自動編碼器來表示較低維度空間(例如,64x64)中的分割圖。接下來,我們從預先訓練的潛在擴散模型(LDM),特別是穩定擴散模型開始,訓練一個可以從 RGB 影像產生全景遮罩的模型。可以透過執行以下命令來訓練模型。預設情況下,我們將使用tools/configs/base/base.yaml中定義的基本設定檔在 COCO 資料集上進行訓練。請注意,由於我們依賴hydra包,因此該檔案將自動加載。
python - W ignore tools / main_ae . py
datasets = coco
base . train_kwargs . fp16 = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05有關傳遞參數的更多詳細資訊可以在tools/scripts/train_ae.sh中找到。例如,我在 23 GB 的單一 GPU 上執行此模型 50k 迭代,總批次大小為 16。
python - W ignore tools / main_ldm . py
datasets = coco
base . train_kwargs . gradient_checkpointing = True
base . train_kwargs . fp16 = True
base . train_kwargs . weight_dtype = float16
base . optimizer_zero_redundancy = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05
base . scheduler_kwargs . weight = 'max_clamp_snr'
base . vae_model_kwargs . pretrained_path = '$AE_MODEL' $AE_MODEL表示上一步所獲得的模型的路徑。有關傳遞參數的更多詳細資訊可以在tools/scripts/train_diffusion.sh中找到。例如,我在 8 個 16 GB 的 GPU 上運行此模型 200k 迭代,總批量大小為 256。
我們計劃發布幾個經過訓練的模型。 (與類別無關的)PQ 指標在 COCO 驗證集上提供。
| 模型 | #參數 | 數據集 | 迭代器 | 質子Q | 平方數 | 需求量 | 下載連結 |
|---|---|---|---|---|---|---|---|
| AE | ~2M | 可可 | 66k | - | - | - | 下載 (23 MB) |
| LDM | ~800M | 可可 | 20萬 | 51.7 | 82.0 | 63.0 | 下載 (3.3 GB) |
注意:功能較弱的 AE(即較少的下採樣或上採樣層)通常有利於修復,因為我們不執行額外的微調。
評估結果應該是這樣的:
python - W ignore tools / main_ldm . py
datasets = coco
base . sampling_kwargs . num_inference_steps = 50
base . eval_only = True
base . load_path = $ PRETRAINED_MODEL_PATH 如果需要,您可以新增參數。較高的閾值(例如--base.eval_kwargs.count_th 700或--base.eval_kwargs.mask_th 0.9可以進一步增加數字。然而,我們使用標準值,閾值設定為 0.5,並刪除面積小於 512 的片段進行評估。
要評估上面的預訓練模型,請執行tools/scripts/eval.sh 。
在這裡,我們將結果視覺化:

如果您發現此儲存庫對您的研究有用,請考慮引用以下論文:
@article { vangansbeke2024ldmseg ,
title = { a simple latent diffusion approach for panoptic segmentation and mask inpainting } ,
author = { Van Gansbeke, Wouter and De Brabandere, Bert } ,
journal = { arxiv preprint arxiv:2401.10227 } ,
year = { 2024 }
}如有任何疑問,請聯絡主要作者。
該軟體根據知識共享許可發布,僅允許個人和研究使用。如需商業許可,請聯絡作者。您可以在此處查看許可證摘要。
我感謝所有公共存儲庫(另請參閱程式碼中的引用),特別是 detectorron2 和擴散器庫。


