open_llama
1.0.0
TL;DR :我們正在發布 OpenLLaMA 的公開預覽版,這是 Meta AI 的 LLaMA 的授權開源複製品。我們正在發布一系列針對不同資料混合進行訓練的 3B、7B 和 13B 模型。我們的模型權重可以作為現有實作中 LLaMA 的替代品。
在此儲存庫中,我們展示了 Meta AI 的 LLaMA 大語言模型的授權開源複製品。我們正在發布一系列在 1T 代幣上訓練的 3B、7B 和 13B 模型。我們提供預先訓練 OpenLLaMA 模型的 PyTorch 和 JAX 權重,以及評估結果以及與原始 LLaMA 模型的比較。 v2 模型比在不同資料混合上訓練的舊 v1 模型更好。
我們正在發布 OpenLLaMA 3Bv3 模型,這是一個 3B 模型,在與 7Bv2 模型相同的資料集混合上訓練 1T 令牌。
我們很高興發布 OpenLLaMA 7Bv2 模型,該模型是在 Falcon 精細化 Web 資料集、starcoder 資料集以及 wikipedia、arxiv 以及來自 RedPajama 的 books 和 stackexchange 上進行訓練的。
我們很高興發布 OpenLLaMA 13B 的最終 1T 代幣版本。我們已經更新了評估結果。對於目前版本的 OpenLLaMA 模型,我們的分詞器經過訓練,可以在分詞之前將多個空白空間合併為一個,類似於 T5 分詞器。因此,我們的分詞器將無法處理程式碼產生任務(例如 HumanEval),因為程式碼涉及許多空白區域。對於與程式碼相關的任務,請使用 v2 模型。
我們很高興發布 OpenLLaMA 3B 和 7B 的最終 1T 代幣版本。我們已經更新了評估結果。我們也很高興發布 13B 模型的 600B 代幣預覽版,該模型是與 Stability AI 合作訓練的。
我們很高興為 OpenLLaMA 7B 模型發布 700B 代幣檢查點,為 3B 模型發布 600B 代幣檢查點。我們也更新了評估結果。我們預計完整的 1T 代幣訓練將於本週末完成。
在收到社群的回饋後,我們發現先前的檢查點版本的分詞器配置不正確,導致新行未被保留。為了解決這個問題,我們重新訓練了分詞器並重新開始了模型訓練。我們也觀察到使用這個新的分詞器可以降低訓練損失。
我們以兩種格式發布權重:一種是與我們的 EasyLM 框架一起使用的 EasyLM 格式,另一種是與 Hugging Face 轉換器庫一起使用的 PyTorch 格式。我們的訓練框架 EasyLM 和檢查點權重均獲得 Apache 2.0 許可證的許可。
預覽檢查點可以直接從 Hugging Face Hub 載入。請注意,建議暫時避免使用 Hugging Face 快速標記產生器,因為我們觀察到自動轉換的快速標記產生器有時會給予不正確的標記化。這可以透過直接使用LlamaTokenizer類別或為AutoTokenizer類別傳入use_fast=False選項來實現。使用方法請參考以下範例。
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))如需更進階的使用,請遵循 Transformers LLaMA 文件。
可以使用 lm-eval-harness 評估模型。然而,由於上述分詞器問題,我們需要避免使用快速分詞器來獲得正確的結果。這可以透過將use_fast=False傳遞到 lm-eval-harness 的這一部分來實現,如下例所示:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)有關在 EasyLM 框架中使用權重的信息,請參閱 EasyLM 的 LLaMA 文件。請注意,與原始 LLaMA 模型不同,我們的 OpenLLaMA 分詞器和權重完全從頭開始訓練,因此不再需要取得原始 LLaMA 分詞器和權重。
v1 模型在 RedPajama 資料集上進行訓練。 v2 模型在 Falcon Fine-Web 資料集、StarCoder 資料集以及 RedPajama 資料集的 wikipedia、arxiv、book 和 stackexchange 部分的混合上進行訓練。我們遵循與原始 LLaMA 論文完全相同的預處理步驟和訓練超參數,包括模型架構、上下文長度、訓練步驟、學習率規劃和優化器。我們的設定與原始設定之間的唯一區別是使用的資料集:OpenLLaMA 使用開放資料集,而不是原始 LLaMA 使用的資料集。
我們使用 EasyLM 在雲端 TPU-v4 上訓練模型,EasyLM 是我們為訓練和微調大型語言模型而開發的基於 JAX 的訓練管道。我們採用普通資料並行性和完全分片資料並行性(也稱為 ZeRO 第 3 階段)的組合來平衡訓練吞吐量和記憶體使用量。總體而言,我們的 7B 模型的 TPU-v4 晶片的吞吐量達到了超過 2200 個令牌/秒。訓練損失如下圖所示。
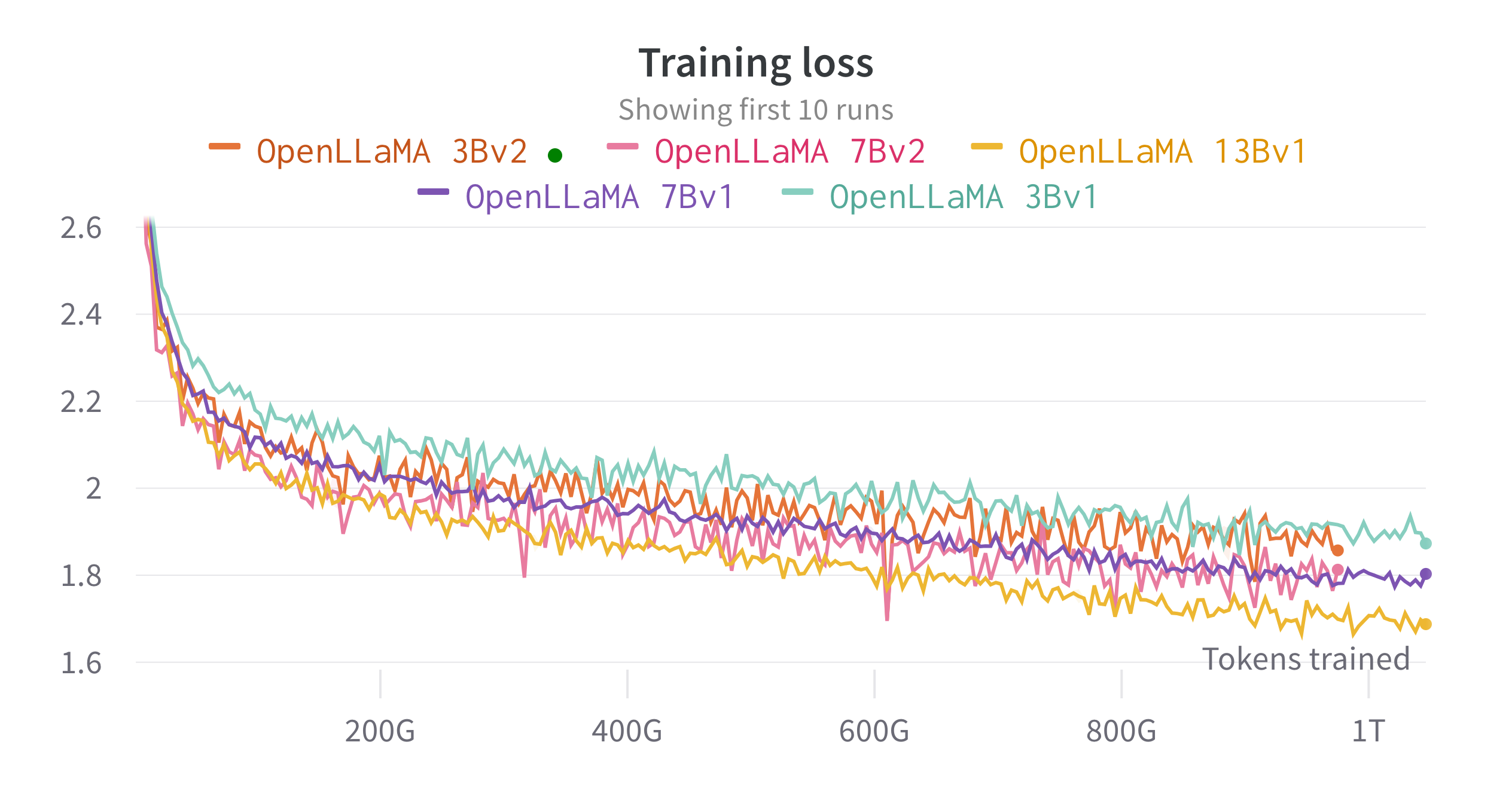
我們使用 lm-evaluation-harness 在廣泛的任務上評估了 OpenLLaMA。 LLaMA 結果是透過在相同的評估指標上運行原始 LLaMA 模型來產生的。我們注意到,我們的 LLaMA 模型結果與原始 LLaMA 論文略有不同,我們認為這是不同評估協議的結果。本期 lm-evaluation-harness 也報告了類似的差異。此外,我們也展示了 GPT-J 的結果,這是由 EleutherAI 在 Pile 資料集上訓練的 6B 參數模型。
最初的 LLaMA 模型針對 1 兆個代幣進行了訓練,而 GPT-J 則針對 5000 億個代幣進行了訓練。我們將結果呈現在下表中。 OpenLLaMA 在大多數任務中表現出與原始 LLaMA 和 GPT-J 相當的性能,並且在某些任務中優於它們。
| 任務/指標 | GPT-J 6B | 美洲駝7B | 美洲駝13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLAMA 3B | OpenLLAMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/acc | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/acc | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| arc_challenge/acc | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| arc_easy/acc | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| 布爾克/acc | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| 海拉斯瓦格/acc | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| hellaswag/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| 開卷品質保證/ACC | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 | 0.27 | 0.30 | 0.31 |
| openbookqa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| 皮卡/ACC | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| piqa/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| 記錄/em | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| 記錄/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| 實時通訊/加速器 | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| truefulqa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| truefulqa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| wic/acc | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| 維諾格蘭德/ACC | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| 平均的 | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
我們從基準測試中刪除了任務 CB 和 WSC,因為我們的模型在這兩個任務上的表現令人懷疑。我們假設訓練集中可能存在基準資料污染。
我們很樂意獲得社群的回饋。如果您有任何疑問,請提出問題或聯絡我們。
OpenLLaMA 由來自 Berkeley AI Research 的 Xinyang Geng* 和 Hao Liu* 開發。 *平等貢獻
我們感謝 Google TPU Research Cloud 計畫提供部分運算資源。我們要特別感謝 TPU Research Cloud 的 Jonathan Caton 幫助我們組織運算資源、Google Cloud 團隊的 Rafi Witten 和 Google JAX 團隊的 James Bradbury 幫助我們優化訓練吞吐量。我們也要感謝 Charlie Snell、Gautier Izacard、Eric Wallace、Lianmin Cheng 以及我們的使用者社群的討論和回饋。
OpenLLaMA 13B v1 模型是與 Stability AI 合作訓練的,我們感謝 Stability AI 提供的運算資源。我們要特別感謝 David Ha 和 Shivanshu Purohit 協調後勤工作並提供工程支援。
如果您發現 OpenLLaMA 對您的研究或應用程式有用,請使用以下 BibTeX 進行引用:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


