llm data annotation
1.0.0
該框架將人類專業知識與 OpenAI 的 GPT-3.5 等大型語言模型 (LLM) 的效率相結合,以簡化資料集註釋和模型改進。迭代方法確保了資料品質的持續改進,從而確保使用這些資料微調模型的效能。這不僅節省了時間,還可以創建客製化的法學碩士,利用人工註釋者和基於法學碩士的精度。
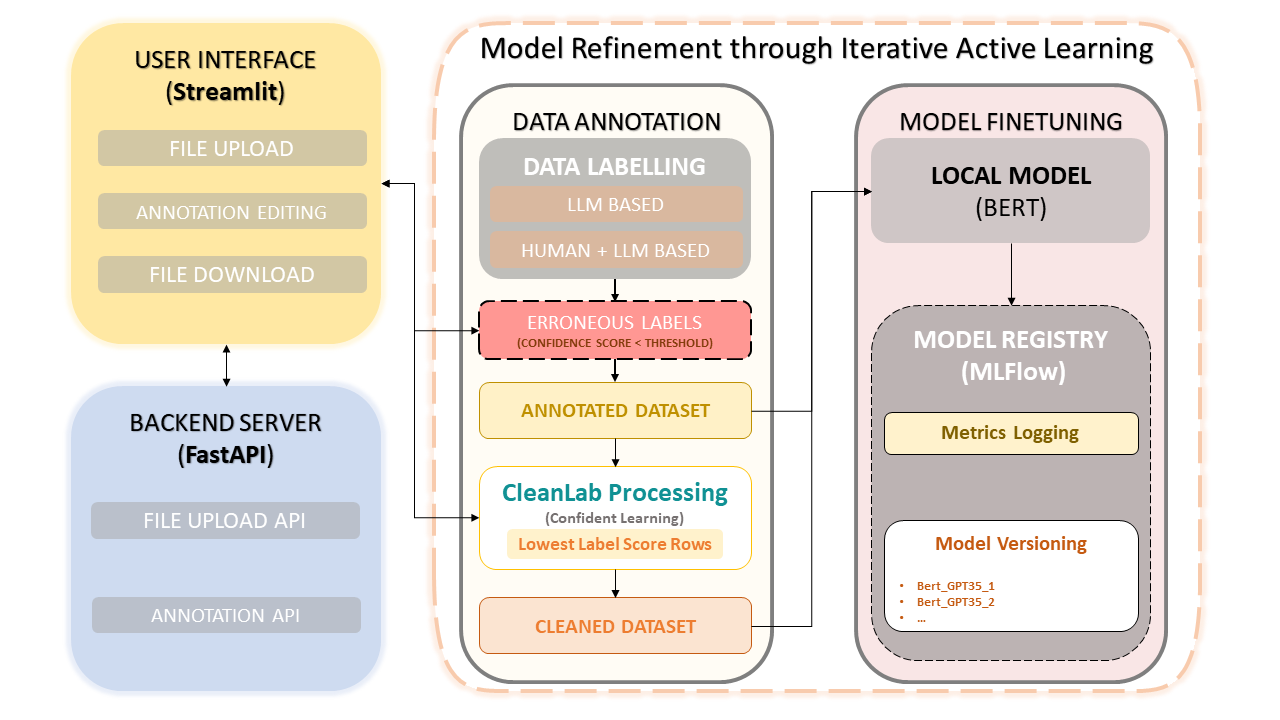
資料集上傳與標註
手動註釋更正
CleanLab:自信的學習方法
資料版本控制和保存
模型訓練
pip install -r requirements.txt啟動 FastAPI 後端:
uvicorn app:app --reload運行 Streamlit 應用程式:
streamlit run frontend.py啟動 MLflow UI :要查看模型、指標和註冊模型,您可以使用以下命令存取 MLflow UI:
mlflow ui在網頁瀏覽器中造訪提供的連結:
http://127.0.0.1:5000 。依照螢幕上的指示上傳、註解、修正和訓練資料集。
置信學習已成為監督學習和弱監督領域的突破性技術。它的目的是表徵標籤噪聲,發現標籤錯誤,並利用噪音標籤進行有效學習。透過修剪雜訊資料並對範例進行排序以自信地進行訓練,該方法可確保資料集乾淨可靠,從而提高整體模型效能。
該專案是根據 MIT 許可證開源的。


