gen ai document sumarization
1.0.0
本專案探討了開源生成人工智慧模型的潛力,特別是基於 Transformer 架構的模型,用於自動總結文件內容。目標是評估和應用現有的生成式人工智慧模型來分析、理解上下文並產生非結構化文件的摘要。
為了實現這一目標,我對兩個著名的模型進行了微調:t5-small 和 facebook/bart-base,重點是增強它們的摘要效能。
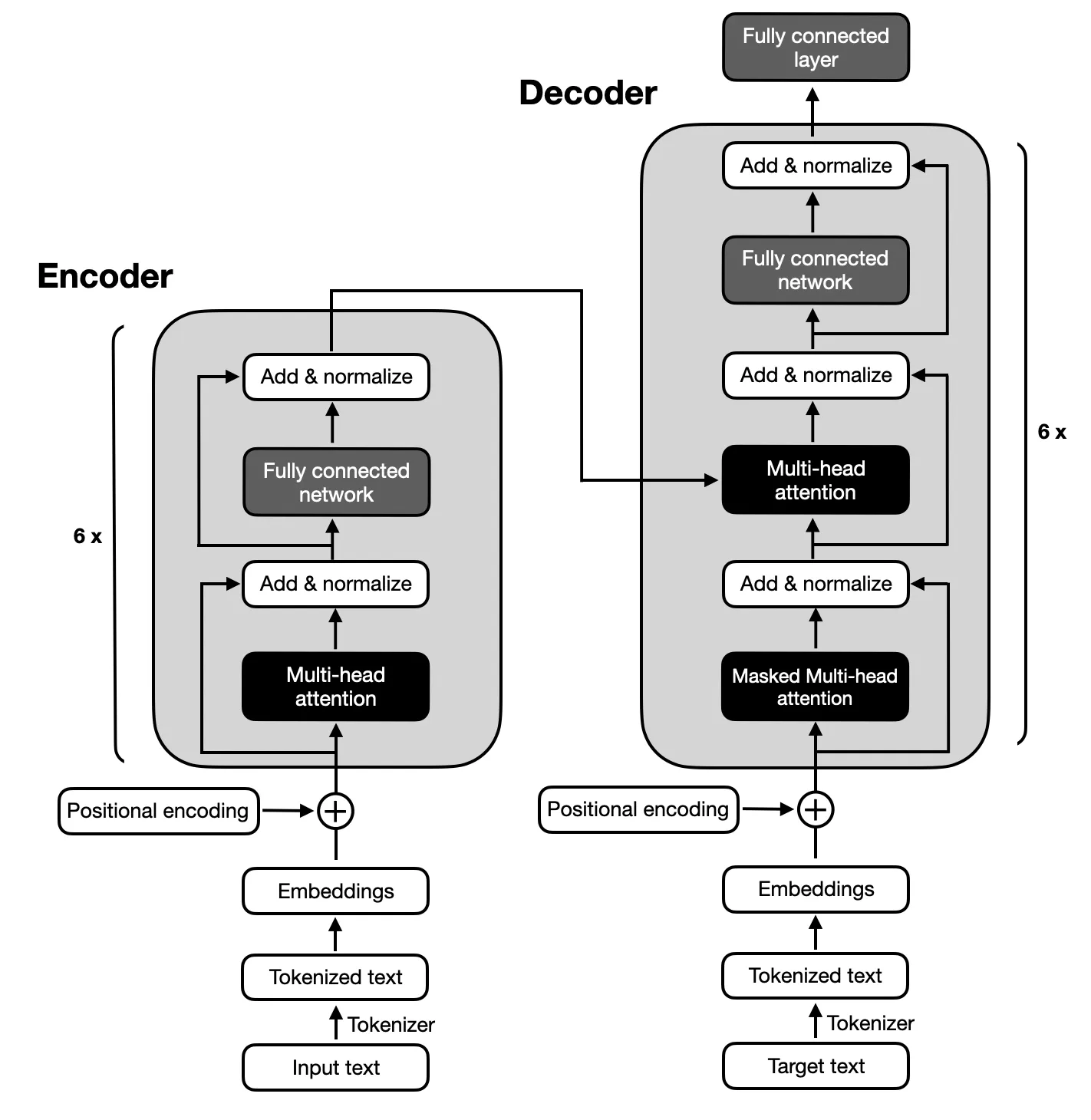
由於文字摘要所需的輸入和輸出序列之間的複雜映射,重點是遵循原始 Transformer 提出的架構的編碼器-解碼器模型。編碼器-解碼器模型擅長捕捉這些序列內的關係,使其適合此任務。
確保您的系統上安裝了 Python 3.x。然後,請按照以下步驟設定您的環境:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.py該項目包括六個主要階段:
用於微調 T5 和 BART 模型的資料集是大專利資料集,該資料集由 130 萬份美國專利文件及其人工撰寫的摘要摘要組成。此資料集中的每個文件均按照合作專利分類 (CPC) 代碼進行分類,涵蓋從人類必需品到實體和電力的廣泛主題。這種多樣性確保模型能夠遇到各種各樣的語言使用和技術術語,這對於開發強大的摘要能力至關重要。
選擇大專利資料集是因為它與總結複雜文件的專案目標相關。專利本質上是詳細和技術性的,這使得它們成為測試模型在保留核心內容和背景的同時壓縮資訊的能力的理想挑戰。此資料集的結構化格式和高品質摘要的存在為訓練和評估模型在產生準確且連貫的摘要方面的表現奠定了堅實的基礎。
使用 ROUGE 指標評估模型的效能,強調它們產生與人類撰寫的摘要密切相關的摘要的能力。 BART和T5模型皆使用專利大數據集進行微調,重點在於實現高品質的摘要摘要。
| 公制 | 價值 |
|---|---|
| 評估損失(Eval Loss) | 1.9244 |
| 胭脂-1 | 0.5007 |
| 胭脂2號 | 0.2704 |
| 胭脂-L | 0.3627 |
| 紅-Lsum | 0.3636 |
| 平均世代長度 (Gen Len) | 122.1489 |
| 運行時間(秒) | 1459.3826 |
| 每秒取樣數 | 1.312 |
| 每秒步數 | 0.164 |
| 公制 | 價值 |
|---|---|
| 評估損失(Eval Loss) | 1.9984 |
| 胭脂-1 | 0.503 |
| 胭脂2號 | 0.286 |
| 胭脂-L | 0.3813 |
| 紅-Lsum | 0.3813 |
| 平均世代長度 (Gen Len) | 151.918 |
| 運行時間(秒) | 714.4344 |
| 每秒取樣數 | 2.679 |
| 每秒步數 | 0.336 |


