累積表設計是所有資料工程師都應該知道的極為強大的資料工程工具。
此設計產生的表格可以對任意大(最多數千天)的時間範圍進行有效分析
以下是此模式的高級管道設計圖:
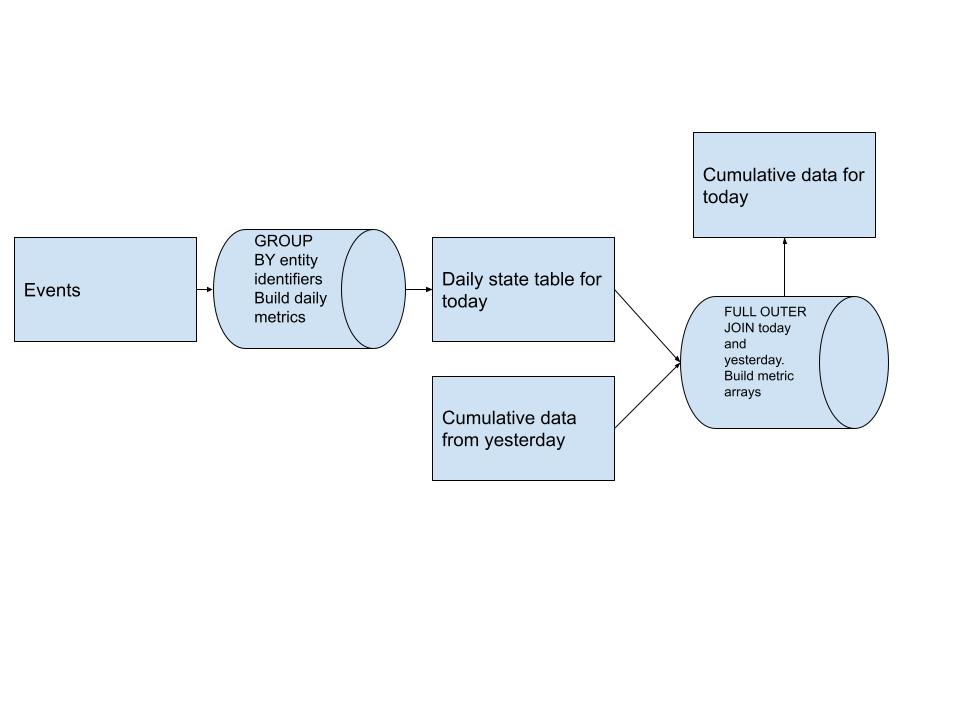
我們最初建立了每日指標表,該表與我們的實體無關。此資料源自於我們上游的任何事件來源。
獲得每日指標後,我們將昨天的累積表與今天的每日數據FULL OUTER JOIN ,並為每個用戶建立指標數組。這使我們能夠引入新的歷史記錄,而無需掃描所有歷史記錄。 (性能大幅提升)
這些指標數組使我們能夠輕鬆回答有關所有使用者歷史記錄的查詢,使用ARRAY_SUM之類的東西來計算我們在數組允許的任何時間範圍內想要的任何指標。
分析的時間範圍越長,這種模式就變得越關鍵!
所有查詢語法均使用 Presto/Trino 語法和函數。此範例需要針對其他 SQL 變體進行修改!
我們將使用日期:
- 2022 年 1 月 1 日至今,用 Airflow 術語來說是
{{ ds }}- 2021 年 12 月 31 日是 Airflow 範本術語中的昨天,這是
{{ yesterday_ds}}
在此範例中,我們將研究如何建立此設計來計算每日、每周和每月的活躍用戶以及用戶的讚、評論和分享。
在本例中,我們的來源表是events 。
event_type , like 、 comment 、 share或view人們很容易認為解決這個問題的方法是運行類似的管道
SELECT
COUNT(DISTINCT user_id) as num_monthly_active_users,
COUNT(CASE WHEN event_type = 'like' THEN 1 END) as num_likes_30d,
COUNT(CASE WHEN event_type = 'comment' THEN 1 END) as num_comments_30d,
COUNT(CASE WHEN event_type = 'share' THEN 1 END) as num_shares_30d,
...
FROM events
WHERE event_date BETWEEN DATE_SUB('2022-01-01', 30), AND '2022-01-01'
問題是我們每天都會掃描 30 天的事件資料來產生這些數字。一個相當浪費但簡單的管道。應該有一種方法,我們只需掃描一次事件數據,並結合過去 29 天的結果,對嗎?我們能否建立一個資料結構,讓資料科學家可以查詢我們的資料並輕鬆了解使用者在過去 N 天內執行的操作數量?
這個設計非常簡單,只有 3 個步驟:
GROUP BY user_id ,然後將其計算為每日活躍(如果有任何事件)COUNT(CASE WHEN event_type = 'like' THEN 1 END)語句來計算每日讚、評論和分享的數量today.user_id = yesterday.user_id上對這兩個資料集FULL OUTER JOINCOALESCE(today.user_id, yesterday.user_id) as user_id來追蹤所有用戶activity_array列。我們只希望activity_array儲存最近30天的數據CARDINALITY(activity_array) < 30來了解我們是否可以將今天的值加到數組的前面,或者我們是否需要在將今天的值添加到前面之前從數組的末尾切掉一個元素COALESCE(t.is_active_today, 0)將零值放入陣列中activity_array非常相似的模式,但也適用於按讚、評論和分享!CASE WHEN ARRAY_SUM(activity_array) > 0 THEN 1 ELSE 0 END為我們提供每月活動,因為我們將陣列大小限制為 30CASE WHEN ARRAY_SUM(SLICE(activity_array, 1, 7)) > 0 THEN 1 ELSE 0 END為我們提供每週活動,因為我們只檢查數組的前 7 個元素(即最後 7 天)ARRAY_SUM(SLICE(like_array, 1, 7)) as num_likes_7d我們提供了該用戶在過去 7 天內點讚的數量ARRAY_SUM(like_array) as num_likes_30d為我們提供了自數組固定為該大小以來該用戶在過去 30 天內點讚的數量depends_on_past: True

