./imagesDockerfile以包含您的二進位文件f()中進行編碼、解碼和計算度量TUPLE_CODECS
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
執行針對某些指標值的編碼並將結果儲存在對應的資料庫檔案中,例如:
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txt中compression_results_worker_[PID]_[TIMESTAMP].txt 在sqlite3資料庫檔案中,例如encoding_results_vmaf.db和encoding_results_ssim.db 。
BD 百分比可以使用名為compute_BD_rates.py的腳本來計算。此腳本採用一個參數:
python3 compute_BD_rates.py [db file name]
並列印每個來源影像的BD Rate VMAF 、 BD Rate SSIM 、 BDRate MS_SSIM 、 BDRate VIF 、 BDRate PSNR_Y和BDRate PSNR_AVG的值以及來源資料集的平均值。 420和444子採樣都會列印 BD 速率。 PSNR_AVG源自MSE_AVG ,MSE_AVG 是所有顏色分量的加權 MSE,根據各個顏色分量中的樣本數量進行加權。
還包括一個名為analyze_encoding_results.py的腳本,該腳本
此腳本有兩個參數:
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
應該注意的是,BD 速率提供了整個目標品質範圍內的一個聚合數字。只考慮 BD 速率,可能會錯過某些見解,例如,具體來說 VMAF=95 工作點的壓縮效率如何比較?
另一個例子是,假設 BD 比率為零。完全有可能速率-質量曲線交叉,且一種編解碼器在 VMAF=95 操作點明顯優於另一種編解碼器,而在較低位元率區域則較差。
理想情況下,當對影像資源進行編碼以便在 UI 中使用時,人們希望具有明確定義的操作質量,例如 VMAF=95。可以說,低品質區域的結果可能並不重要。因此,(b) 中描述的見解增強了 BD 速率提供的「整體」見解。
並發工作進程的數量可以在
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
考慮到您正在運行的系統,合理的並發性可能會受到處理器核心數量或可用 RAM 數量與正在測試的編解碼器集合中最苛刻的編碼器進程消耗的內存的限制。例如,如果編碼器_A 實例通常消耗5GB RAM,而您的總RAM 為32GB,那麼即使您有24 個(或大於6 個)處理器核心,合理的並發性也可能會限制為6 (32 / 5)。
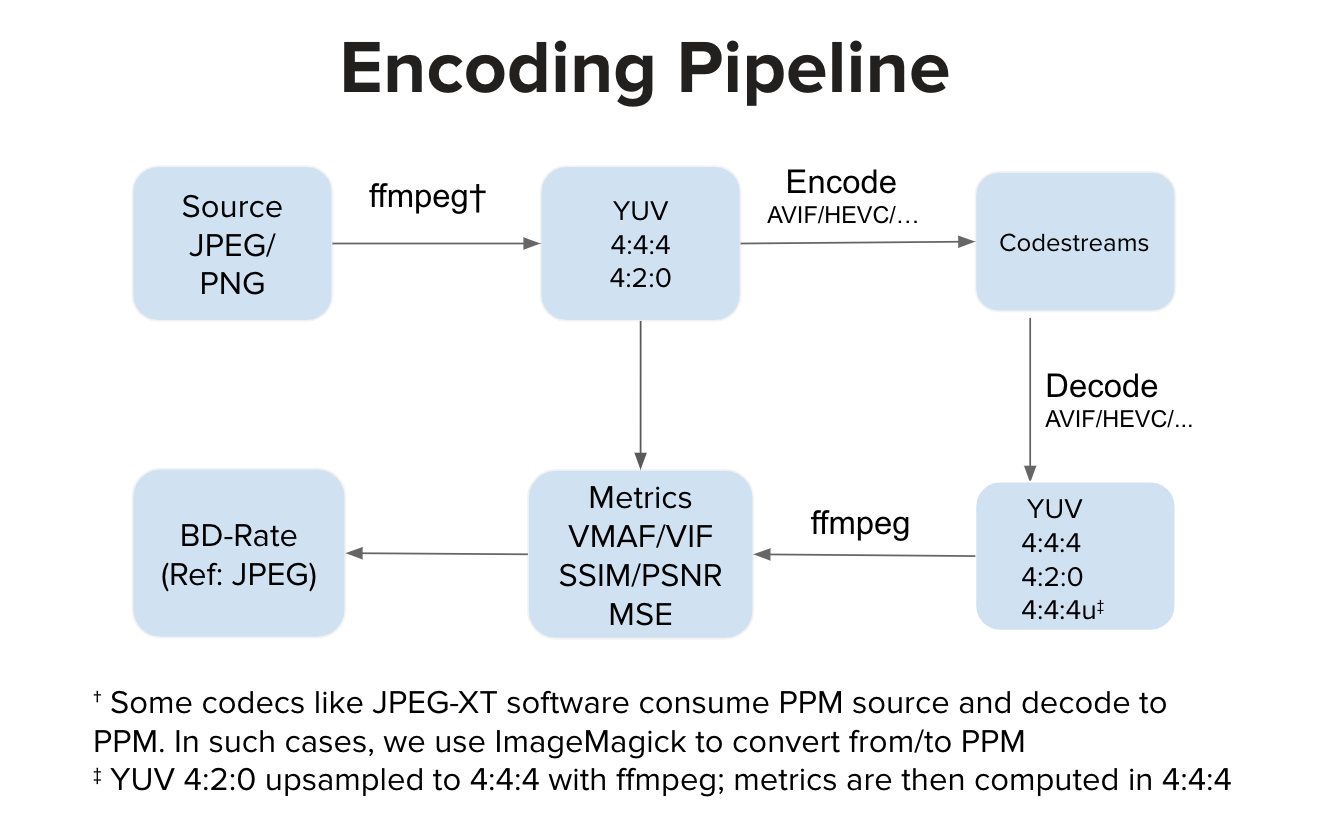
理想情況下,編碼器實作消耗 YUV 輸入並產生碼流。理想情況下,解碼器實作會消耗碼流並解碼為 YUV 輸出。然後我們計算 YUV 空間中的度量。然而,有些實作(例如 JPEG-XT 軟體)會消耗 PPM 輸入並產生 PPM 輸出。在這種情況下,在 YUV 空間中的質量計算之前可能存在源 PPM 到 YUV 的轉換以及解碼的 PPM 到 YUV 的轉換。與常規管道相比,額外的轉換步驟可能會引入輕微的失真,但在我們的實驗中,這些步驟不會對 VMAF 分數產生任何明顯的影響。