由於與 Stability AI 和 Runway 的合作,穩定擴散得以實現,並建立在我們先前的工作基礎上:
使用潛在擴散模型的高解析度影像合成
羅賓·隆巴赫*、安德烈亞斯·布拉特曼*、多米尼克·洛倫茨、帕特里克·埃瑟、比約恩·奧默
CVPR '22 口語 | GitHub | arXiv |專案頁面
 穩定擴散是一種潛在的文本到圖像擴散模型。感謝 Stability AI 的慷慨計算捐贈和 LAION 的支持,我們能夠在 LAION-5B 資料庫子集的 512x512 影像上訓練潛在擴散模型。與 Google 的 Imagen 類似,該模型使用凍結的 CLIP ViT-L/14 文字編碼器來根據文字提示調節模型。該型號具有 860M UNet 和 123M 文字編碼器,相對輕量級,並且在至少具有 10GB VRAM 的 GPU 上運行。請參閱下面的本節和型號卡。
穩定擴散是一種潛在的文本到圖像擴散模型。感謝 Stability AI 的慷慨計算捐贈和 LAION 的支持,我們能夠在 LAION-5B 資料庫子集的 512x512 影像上訓練潛在擴散模型。與 Google 的 Imagen 類似,該模型使用凍結的 CLIP ViT-L/14 文字編碼器來根據文字提示調節模型。該型號具有 860M UNet 和 123M 文字編碼器,相對輕量級,並且在至少具有 10GB VRAM 的 GPU 上運行。請參閱下面的本節和型號卡。
可以使用以下命令建立並啟動名為ldm的合適 conda 環境:
conda env create -f environment.yaml
conda activate ldm
您也可以透過運行來更新現有的潛在擴散環境
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 是指模型架構的特定配置,它使用下採樣因子 8 自動編碼器以及 860M UNet 和 CLIP ViT-L/14 文字編碼器來進行擴散模型。該模型在 256x256 影像上進行預訓練,然後在 512x512 影像上進行微調。
注意:穩定擴散 v1 是通用的文字到影像擴散模型,因此反映了其訓練資料中存在的偏差和(錯誤)概念。有關訓練過程和數據以及模型預期用途的詳細資訊可以在相應的模型卡中找到。
這些權重可透過 Hugging Face 的 CompVis 組織獲得,並獲得許可證,該許可證包含特定的基於使用的限制,以防止模型卡告知的誤用和傷害,但在其他方面仍然是允許的。雖然授權條款允許商業使用,但我們不建議在沒有額外安全機制和考慮的情況下將提供的權重用於服務或產品,因為權重存在已知的限制和偏差,並且對安全和道德部署進行研究通用文字到圖像模型是一項持續的工作。權重是研究成果,應如此處理。
CreativeML OpenRAIL M 許可證是 Open RAIL M 許可證,改編自 BigScience 和 RAIL Initiative 在負責任的 AI 授權領域共同進行的工作。另請參閱有關我們的許可證所基於的 BLOOM Open RAIL 許可證的文章。
我們目前提供以下檢查點:
sd-v1-1.ckpt :laion2B-en 上解析度256x256時有 237k 步。在 laion 高解析度上,在解析度512x512下有 194k 個步驟(來自 LAION-5B 的 170M 範例,解析度>= 1024x1024 )。sd-v1-2.ckpt :從sd-v1-1.ckpt恢復。 laion-aesthetics v2 5+ 上解析度512x512的 515k 步(laion2B-en 的子集,估計美學分數> 5.0 ,另外過濾到原始尺寸>= 512x512的圖像,估計水印機率< 0.5 。水印機率估計來自LAION-5Bx512的圖像,估計水印機率< 0.5 。水印機率估計來自LAION-5Bx512的圖像,估計水印機率< 0.5 。水印概率來自LAION-5Bx512元數據,美學分數是使用LAION-Aesthetics Predictor V2 估計的。sd-v1-3.ckpt :從sd-v1-2.ckpt恢復。在「laion-aesthetics v2 5+」上以512x512分辨率執行 195k 步,並丟棄 10% 的文字調節以改進無分類器引導採樣。sd-v1-4.ckpt :從sd-v1-2.ckpt恢復。在「laion-aesthetics v2 5+」上以512x512解析度執行 225k 步,並刪除 10% 的文字調節以改善無分類器引導取樣。使用不同的無分類器指導尺度(1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)和 50 個 PLMS 採樣步驟進行的評估顯示了檢查點的相對改進: 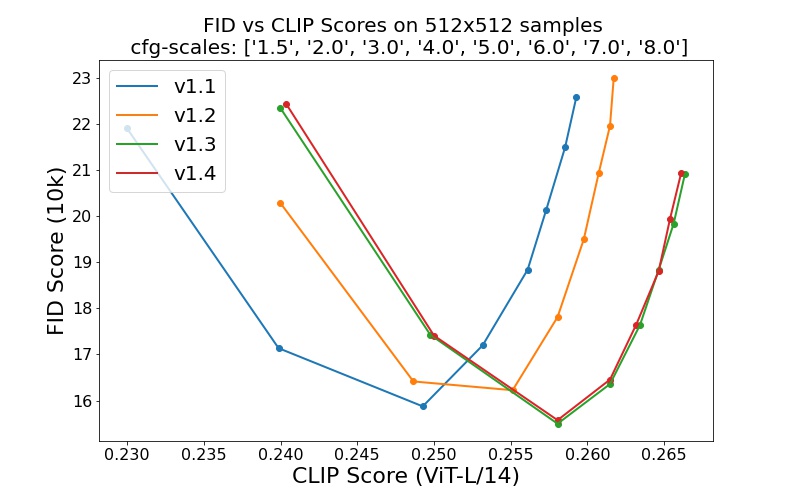


穩定擴散是一種以 CLIP ViT-L/14 文字編碼器的(非池化)文字嵌入為條件的潛在擴散模型。我們提供了用於採樣的參考腳本,但也存在擴散器集成,我們期望看到更活躍的社區開發。
我們提供了一個參考採樣腳本,其中包含
獲得stable-diffusion-v1-*-original權重後,將它們連結起來
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
並採樣
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
預設情況下,它使用指導比例--scale 7.5 ,即 Katherine Crowson 的 PLMS 採樣器實現,並以 50 個步驟渲染大小為 512x512 的圖像(經過訓練)。下面列出了所有支援的參數(輸入python scripts/txt2img.py --help )。
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
注意:所有 v1 版本的推理配置均設計為與僅 EMA 檢查點一起使用。因此,在組態中設定了use_ema=False ,否則程式碼將嘗試從非 EMA 權重切換到 EMA 權重。如果您想檢查 EMA 與無 EMA 的效果,我們提供包含兩種類型權重的「完整」檢查點。對於這些, use_ema=False將載入並使用非 EMA 權重。
下載和採樣穩定擴散的一個簡單方法是使用擴散器庫:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )透過使用 SDEdit 首次提出的擴散去噪機制,該模型可用於不同的任務,例如文字引導的影像到影像的轉換和升級。與 txt2img 採樣腳本類似,我們提供了一個使用穩定擴散進行影像修改的腳本。
下面描述了一個將 Pinta 中的粗略草圖轉換為詳細藝術品的範例。
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
此處,強度是 0.0 到 1.0 之間的值,用於控制添加到輸入影像的雜訊量。接近 1.0 的值允許存在大量變化,但也會產生在語義上與輸入不一致的圖像。請參閱以下範例。
輸入

輸出


例如,此流程也可用於從基本模型升級樣本。
我們的擴散模型程式碼庫很大程度上建立在 OpenAI 的 ADM 程式碼庫和 https://github.com/lucidrains/denoising-diffusion-pytorch 之上。感謝開源!
Transformer 編碼器的實作來自 lucidrains 的 x-transformers。
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


