metal flash attention
v1.0.1
該儲存庫將 FlashAttention 的官方實作移植到 Apple 晶片上。它是一個最小的、可維護的來源檔案集,可重現 FlashAttention 演算法。
僅單頭注意力,關注不同註意力演算法的核心瓶頸(暫存器壓力、平行性)。正確完成基本演算法後,添加區塊稀疏性等自訂內容應該相對簡單。
一切都是在運行時編譯的。這與先前的實作形成鮮明對比,後者依賴 Xcode 14.2 中嵌入的可執行檔。
向後傳遞比 Dao-AILab/flash-attention 使用更少的記憶體。官方實現為原子和部分和分配臨時空間。 Apple 硬體缺乏原生 FP32 原子(模擬metal::atomic<float> )。在試圖規避硬體支援不足的同時,FlashAttention-2 後向核心中的頻寬和並行化瓶頸也暴露出來。另一種向後傳遞的設計具有更高的計算成本(7 個 GEMM,而不是 5 個 GEMM)。它在註意力矩陣的行和列維度上實現了 100% 的平行化效率。最重要的是,它更容易編碼和維護。
為了克服暫存器壓力瓶頸,我們做了很多瘋狂的事情。當頭部尺寸較大時(例如 256),沒有任何矩陣區塊可以裝入暫存器。連累加器也不能。因此,有意進行暫存器溢出,但以更優化的方式進行。注意力演算法中加入了第三個區塊維度,該維度沿著D進行區塊化。注意力矩陣區塊的縱橫比被嚴重扭曲,以最大限度地減少暫存器溢出的頻寬成本。例如,沿並行化維度為 16-32,沿遍歷維度為 80-128。有一個很大的參數文件,它採用D維度,並決定哪些操作數可以放入暫存器。然後,它分配一個區塊大小來平衡許多競爭瓶頸。
最終結果是在 M1 Max 上每秒穩定執行 4400 條千兆指令(ALU 利用率為 83%),且序列長度和頭部尺寸無限。假設 BF16 模擬用於混合精度(Metal 的bfloat具有符合 IEEE 規範的捨入,這是沒有硬體 BF16 的舊晶片的主要開銷)。
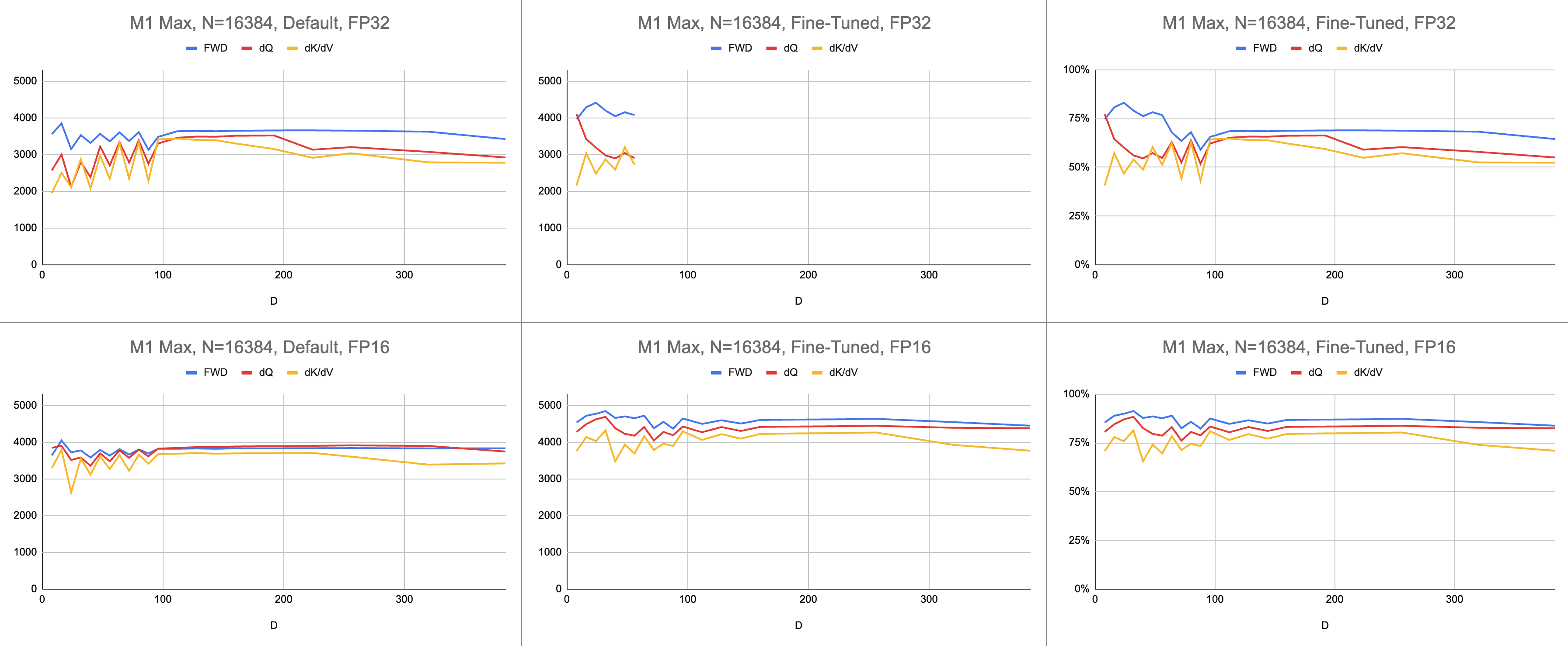
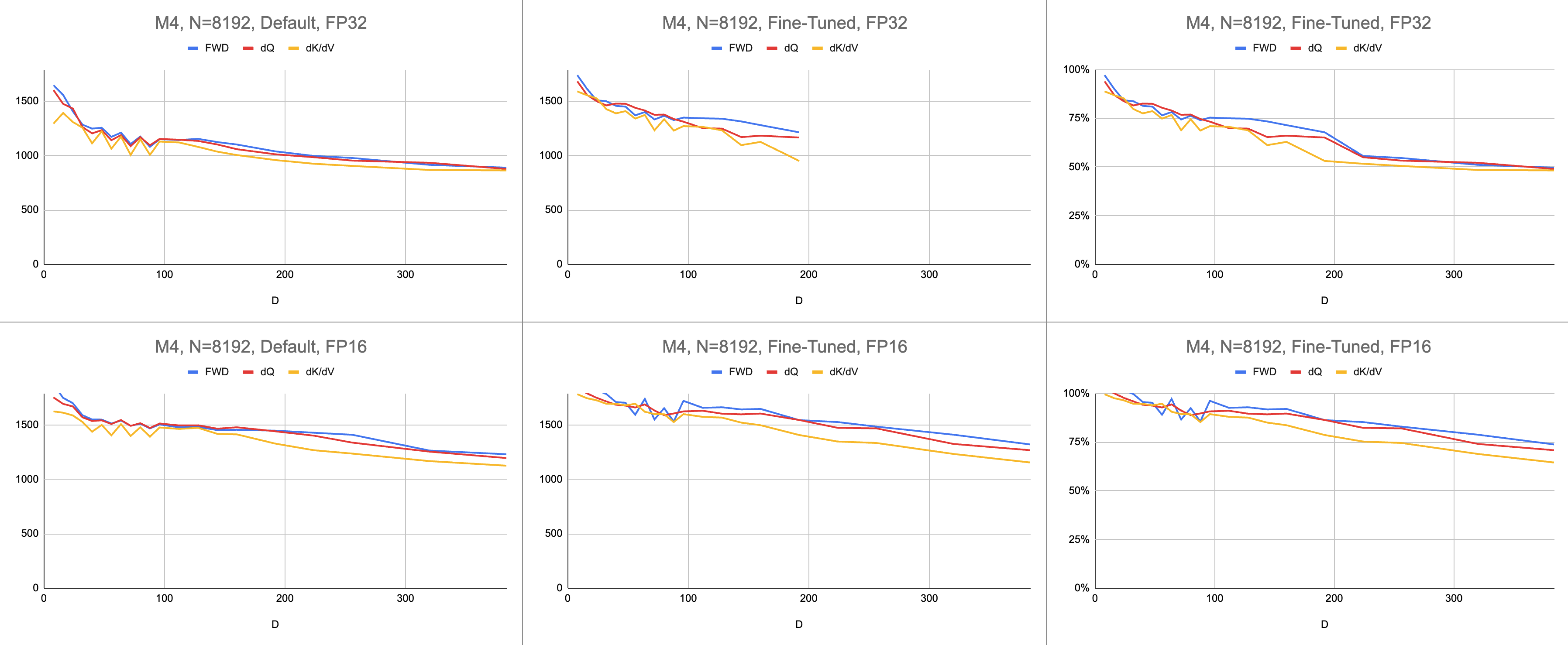
原始資料:https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
在人工智慧領域,效能最常以每秒千兆浮點運算(GFLOPS)來報告。此指標反映了簡化的效能模型,即每個指令都發生在 GEMM 中。隨著硬體從早期的 FPU 發展到現代向量處理器,最常見的浮點運算被整合到單一指令中。融合乘加 (FMA)。當兩個 100x100 矩陣相乘時,會發出 100 萬個 FMA 指令。為什麼我們必須將這個 FMA 視為兩個單獨的指令?
這個問題與注意力相關,其中並非所有浮點運算都是相同的。假定大多數其他指令都進入 FMA 單元,softmax 期間的求冪發生在單一時鐘週期內。 softmax 期間的一些乘法和加法不能與附近的加法或乘法融合。我們是否應該將它們視為 FMA,並假裝硬體執行 FMA 的速度減慢兩倍?目前尚不清楚 GEMM 效能模型如何解釋我的著色器是否有效地使用 ALU 硬體。
我使用千兆指令來了解著色器的效能,而不是千兆浮點運算。它更直接地映射到演算法。例如,一個GEMM是N^3 FMA指令。前向注意力執行兩個矩陣乘法,或2 * D * N^2 FMA 指令。後向注意力(由 Dao-AILab/flash-attention 實作)是5 * D * N^2 FMA 指令。嘗試將此表與 Flash1、Flash2 或 Flash3 論文中的屋頂線模型進行比較。
| 手術 | 工作 |
|---|---|
| 方形GEMM | N^3 |
| 前向關注 | (2D + 5) * N^2 |
| 落後的天真注意力 | 4D * N^2 |
| 向後閃光注意 | (5D + 5) * N^2 |
| 前輪驅動 + 後輪驅動組合 | (7D + 10) * N^2 |
由於 FP32 原子的複雜性,MFA 使用了不同的方法進行後向傳遞。這具有較高的計算成本。它將向後傳遞分成兩個單獨的核心: dQ和dK/dV 。下拉清單顯示偽代碼。將此與 Flash1、Flash2 或 Flash3 論文中的演算法之一進行比較。
| 手術 | 工作 |
|---|---|
| 向前 | (2D + 5) * N^2 |
| 後向dQ | (3D + 5) * N^2 |
| 後向dK/dV | (4D + 5) * N^2 |
| 前輪驅動 + 後輪驅動組合 | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }性能是透過計算計算工作量然後除以秒來衡量的。最終結果是「每秒千兆指令」。接下來,我們需要一個屋頂線模型。下表顯示了 GINSTRS 的屋頂線,以 GFLOPS 的一半計算。 ALU 使用率為(每秒實際千兆指令)/(每秒預期千兆指令)。例如,M1 Max 通常可實現 80% 的 ALU 利用率和混合精度。
該模型存在局限性。它在 M3 世代中因頭部尺寸較小而崩潰。不同的計算單元可以同時使用,使表觀利用率超過100%。在大多數情況下,基準測試提供了一個準確的模型,顯示還剩下多少效能。
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| 硬體 | 浮點運算次數 | 金斯瑞 |
|---|---|---|
| M1最大 | 10616 | 5308 |
| M4 | 3580 | 1790 |
Metal 連接埠與官方 FlashAttention 儲存庫相比效果如何?想像一下,我採用「原子 dQ」演算法並實現了 100% 的性能。然後,切換到實際的 MFA 儲存庫,發現模型訓練速度慢了 4 倍。這將佔官方儲存庫屋頂線的 25%。要獲得此百分比,請將所有三個核心的平均 ALU 使用率乘以7 / 9 。蘋果硬體的統計數據使用了一個更細緻的模型,但這就是它的要點。
為了計算 Nvidia 硬體的使用率,我使用 FP16/BF16 ALU 的 GFLOPS。我將論文中每張圖中的最高 GFLOPS 除以 312000 (A100 SXM)、989000 (H100 SXM)。請注意,對於較大的頭部尺寸和暫存器密集型內核(向後傳遞),沒有報告基準。我確認他們沒有解決無限頭部尺寸的套準壓力問題。例如,累加器始終保存在暫存器中。在撰寫本文時,我還沒有看到 D=256 反向梯度執行並獲得正確結果的具體證據。
| A100、Flash2、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 192000 | 223000 | 0 |
| 落後 | 170000 | 196000 | 0 |
| 前進+後退 | 176000 | 203000 | 0 |
| H100、Flash3、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 497000 | 648000 | 756000 |
| 落後 | 474000 | 561000 | 0 |
| 前進+後退 | 480000 | 585000 | 0 |
| H100、Flash3、FP8 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 613000 | 1008000 | 1171000 |
| 落後 | 0 | 0 | 0 |
| 前進+後退 | 0 | 0 | 0 |
| A100、Flash2、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 62% | 71% | 0% |
| 前進+後退 | 56% | 65% | 0% |
| H100、Flash3、FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 50% | 66% | 76% |
| 前進+後退 | 48% | 59% | 0% |
| M1架構,FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 86% | 85% | 86% |
| 前進+後退 | 62% | 63% | 64% |
| M3架構,FP16 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| 向前 | 94% | 91% | 82% |
| 前進+後退 | 71% | 69% | 61% |
| 2020年生產的硬件 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| M1—M2架構 | 62% | 63% | 64% |
| 2023 年生產的硬件 | d = 64 | d = 128 | d = 256 |
|---|---|---|---|
| H100(使用 FP8 GFLOPS) | 24% | 30% | 0% |
| H100(使用 FP16 GFLOPS) | 48% | 59% | 0% |
| M3—M4架構 | 71% | 69% | 61% |
儘管進行了更多的計算,Apple 硬體訓練 Transformer 的速度比執行相同工作的 Nvidia 硬體更快。針對不同 GPU 之間的大小差異進行標準化。只要專注於 GPU 的利用效率即可。
也許主儲存庫應該嘗試避免 FP32 原子的演算法,並在暫存器無法容納 GPU 核心時故意溢位暫存器。這似乎不太可能,因為它們對可能問題大小的一小部分提供了硬編碼支援。 The motivation seems to be supporting the most common models, where D is a power of 2, and less than 128. For anything else, users need to rely on alternative fallback implementations (eg the MFA repository), which might use a completely different underlying演算法.
在 macOS 上,下載 Swift 套件並使用-Xswiftc -Ounchecked進行編譯。對效能敏感的 CPU 程式碼需要此編譯器選項。不能使用發布模式,因為它會強制每次發生單一變更時從頭開始重新編譯整個程式碼庫。在 Finder 中導覽至 Git 儲存庫,然後雙擊Package.swift 。應該會彈出一個 Xcode 視窗。左邊應該有一個文件層次結構。如果你無法解開層次結構,那就表示出了問題。
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
或者,使用 SwiftUI 範本建立一個新的 Xcode 專案。覆蓋"Hello, world!" string 並呼叫傳回String的函數。此函數將執行您選擇的腳本,然後呼叫exit(0) ,因此應用程式在將任何內容渲染到螢幕之前崩潰。您將使用 Xcode 控制台中的輸出作為有關程式碼的回饋。此工作流程與 macOS 和 iOS 相容。
透過Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level新增-Xswiftc -Ounchecked選項。表格的第二列列出了您的項目名稱。按一下下拉清單中的「其他」 ,然後在出現的面板中鍵入-Ounchecked 。接下來,將此儲存庫新增為 Swift 套件相依性。查看Tests/FlashAttention下的一些測試。將這些測試之一的原始原始程式碼複製到您的專案中。從上一段的函數呼叫測試。檢查控制台上顯示的內容。
若要修改 Metal 程式碼產生(例如新增多頭或遮罩支援),請將原始 Swift 程式碼複製到您的 Xcode 專案中。可以在單獨的資料夾中使用git clone ,也可以在 GitHub 上以 ZIP 形式下載原始檔案。還有一種方法可以連結到您的metal-flash-attention分支並將您的變更自動儲存到雲端,但這更難以設定。刪除上一段中的 Swift 套件相依性。重新執行您選擇的測試。它會編譯並在控制台中顯示某些內容嗎?
在以下任一資料夾中找到多行字串文字之一:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
將隨機文字添加到其中之一。再次編譯並執行該專案。應該出了嚴重的問題。例如,Metal 編譯器可能會拋出錯誤。如果這種情況沒有發生,請嘗試在其他地方弄亂另一行程式碼。如果測試仍然通過,則 Xcode 不會註冊您的變更。
繼續對區塊稀疏性或其他內容進行編碼。取得程式碼是否完全有效、是否快速運作、是否在每個問題大小上都快速運作的回饋。將原始原始碼整合到您的應用程式中,或將其翻譯為另一種程式語言。


