Im KI-Kreis ist der Turing-Award-Gewinner Yann Lecun ein typischer Ausreißer.
Während viele technische Experten fest davon überzeugt sind, dass die Realisierung von AGI auf dem aktuellen technischen Weg nur eine Frage der Zeit ist, hat Yann Lecun wiederholt Einwände erhoben.
In hitzigen Debatten mit seinen Kollegen sagte er mehr als einmal, dass der aktuelle Weg der Mainstream-Technologie uns nicht zu AGI führen könne und selbst das aktuelle Niveau der KI nicht so gut sei wie eine Katze.
Gewinner des Turing-Preises, leitender KI-Wissenschaftler bei Meta, Professor an der New York University usw. Diese schillernden Titel und die große praktische Erfahrung an vorderster Front machen es für jeden von uns unmöglich, die Erkenntnisse dieses KI-Experten zu ignorieren.

Was denkt Yann LeCun also über die Zukunft der KI? In einer kürzlichen öffentlichen Rede erläuterte er noch einmal seinen Standpunkt: KI kann niemals eine annähernd menschliche Intelligenz erreichen, wenn sie sich ausschließlich auf Texttraining verlässt.
Einige Ansichten sind wie folgt:
1. In Zukunft werden Menschen im Allgemeinen intelligente Brillen oder andere Arten von intelligenten Geräten tragen. Diese Geräte werden über integrierte Assistenzsysteme verfügen, um persönliche intelligente virtuelle Teams zu bilden und so die persönliche Kreativität und Effizienz zu verbessern.
2. Der Zweck intelligenter Systeme besteht nicht darin, den Menschen zu ersetzen, sondern darin, die menschliche Intelligenz zu verbessern, damit Menschen effizienter arbeiten können.
3. Sogar eine Hauskatze hat ein Modell in ihrem Gehirn, das komplexer ist, als jedes KI-System erstellen kann.
4. FAIR konzentriert sich grundsätzlich nicht mehr auf Sprachmodelle, sondern bewegt sich auf das langfristige Ziel von KI-Systemen der nächsten Generation zu.
5. KI-Systeme können durch Training allein auf Textdaten keine annähernd menschliche Intelligenz erreichen.
6. Yann Lecun schlug vor, generative Modelle, probabilistische Modelle, kontrastives Lernen und verstärkendes Lernen aufzugeben und stattdessen die JEPA-Architektur und energiebasierte Modelle zu übernehmen, da er davon überzeugt ist, dass diese Methoden die Entwicklung von KI eher fördern werden.
7. Während Maschinen irgendwann die menschliche Intelligenz übertreffen werden, werden sie kontrolliert, weil sie zielorientiert sind.
Interessanterweise gab es vor Beginn der Rede eine Episode.
Als der Moderator LeCun vorstellte, nannte er ihn den leitenden KI-Wissenschaftler des Facebook AI Research Institute (FAIR) .
Diesbezüglich stellte LeCun vor der Rede klar, dass das „F“ in FAIR nicht mehr für Facebook steht, sondern „ Fundamental “ bedeutet.
Der Originaltext der folgenden Rede wurde von APPSO zusammengestellt und bearbeitet. Abschließend ist der Original-Videolink angehängt: https://www.youtube.com/watch?v=4DsCtgtQlZU
KI versteht die Welt nicht so gut wie Ihre Katze
Okay, ich werde über KI auf menschlicher Ebene sprechen und darüber, wie wir dorthin gelangen und warum wir nicht dorthin gelangen.
Erstens brauchen wir wirklich KI auf menschlicher Ebene.
Denn zum einen werden die meisten von uns in Zukunft Datenbrillen oder andere Arten von Geräten tragen. Wir werden mit diesen Geräten sprechen und diese Systeme werden Assistenten beherbergen, vielleicht mehr als einen, vielleicht eine ganze Reihe von Assistenten.
Dies wird dazu führen, dass jeder von uns im Wesentlichen ein intelligentes virtuelles Team hat, das für uns arbeitet.
Daher wird jeder zum „Chef“, aber diese „Mitarbeiter“ sind keine echten Menschen. Wir müssen Systeme wie dieses aufbauen, im Wesentlichen um die menschliche Intelligenz zu steigern und die Menschen kreativer und effizienter zu machen.

Aber dafür brauchen wir Maschinen, die die Welt verstehen, sich an Dinge erinnern können, über Intuition und gesunden Menschenverstand verfügen und auf dem gleichen Niveau wie Menschen denken und planen können.
Obwohl Sie vielleicht von einigen Befürwortern gehört haben, dass aktuelle KI-Systeme nicht über diese Fähigkeiten verfügen. Wir müssen uns also die Zeit nehmen, zu lernen, wie man die Welt modelliert, um mentale Modelle davon zu entwickeln, wie die Welt funktioniert.
Praktisch jedes Tier hat ein solches Modell. Ihre Katze muss über ein komplexeres Modell verfügen, als jedes KI-System erstellen oder entwerfen kann.

Wir brauchen ein System, das über ein persistentes Gedächtnis verfügt, über das aktuelle Sprachmodelle (LLMs) nicht verfügen, ein System, das komplexe Aktionsabläufe planen kann, die heutige Systeme nicht ausführen können, und ein System, das kontrollierbar und sicher ist.
Daher werde ich eine Architektur namens zielgesteuerte KI vorschlagen. Ich habe dazu vor etwa zwei Jahren ein Visionspapier geschrieben und veröffentlicht. Viele Leute bei FAIR arbeiten hart daran, diesen Plan Wirklichkeit werden zu lassen.
FAIR hat in der Vergangenheit an mehr Anwendungsprojekten gearbeitet, aber Meta hat vor anderthalb Jahren eine Produktabteilung namens Generative AI (Gen AI) gegründet, um sich auf KI-Produkte zu konzentrieren.
Sie betreiben angewandte Forschung und Entwicklung, sodass FAIR nun auf das langfristige Ziel von KI-Systemen der nächsten Generation ausgerichtet ist. Wir konzentrieren uns grundsätzlich nicht mehr auf Sprachmodelle.
Der Erfolg der KI, einschließlich großer Sprachmodelle (LLMs) , und insbesondere der Erfolg vieler anderer Systeme in den letzten 5 oder 6 Jahren, beruht auf einer Reihe von Techniken, darunter natürlich auch selbstüberwachtes Lernen.

Der Kern des selbstüberwachten Lernens besteht darin, ein System nicht für eine bestimmte Aufgabe zu trainieren, sondern zu versuchen, die Eingabedaten gut darzustellen. Eine Möglichkeit, dies zu erreichen, ist die Schadens- und Wiederherstellungswiederherstellung.
Sie können also einen Textabschnitt nehmen und ihn verfälschen, indem Sie einige Wörter entfernen oder andere Wörter ändern. Dieser Prozess kann für Text, DNA-Sequenzen, Proteine oder alles andere und in gewissem Umfang sogar für Bilder verwendet werden. Anschließend trainieren Sie ein riesiges neuronales Netzwerk, um die vollständige Eingabe, die unverfälschte Version, zu rekonstruieren.
Dies ist ein generatives Modell, da es versucht, das ursprüngliche Signal zu rekonstruieren.
Das rote Kästchen ist also wie eine Kostenfunktion, oder? Es berechnet den Abstand zwischen der Eingabe Y und der rekonstruierten Ausgabe Y. Dies ist der Parameter, der während des Lernprozesses minimiert werden muss. Dabei lernt das System eine interne Darstellung der Eingabe, die für verschiedene Folgeaufgaben verwendet werden kann.
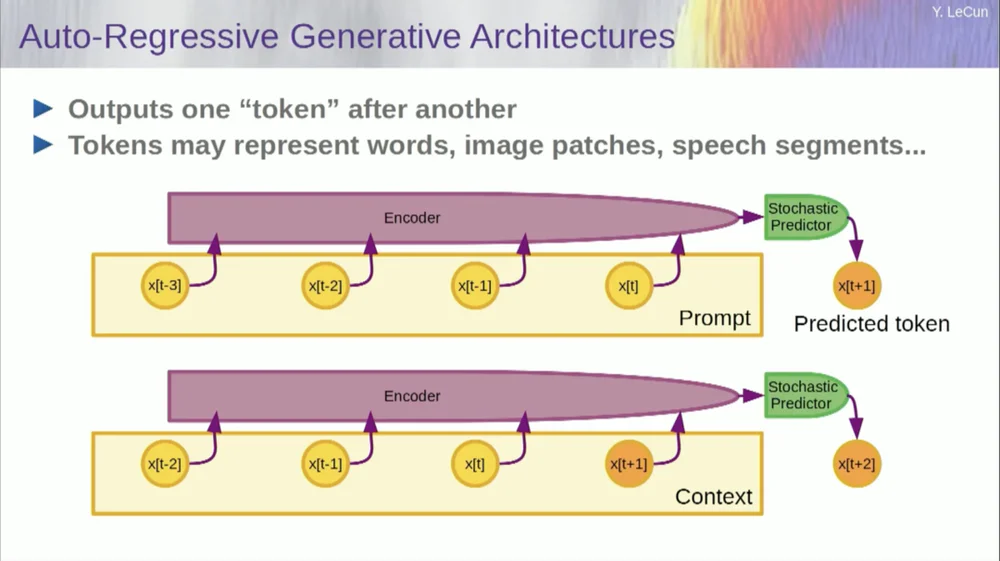
Natürlich kann dies verwendet werden, um Wörter in Texten vorherzusagen, was bei der autoregressiven Vorhersage der Fall ist.
Ein Sonderfall hiervon sind Sprachmodelle, bei denen die Architektur so konzipiert ist, dass sie bei der Vorhersage eines Elements, eines Tokens oder eines Wortes nur auf die anderen Token links davon achten kann.
Es kann nicht in die Zukunft blicken. Wenn Sie ein System richtig trainieren, ihm Text zeigen und es bitten, das nächste Wort oder den nächsten Token im Text vorherzusagen, können Sie das System verwenden, um das nächste Wort vorherzusagen. Dann fügen Sie das nächste Wort zur Eingabe hinzu, sagen das zweite Wort voraus und fügen dieses zur Eingabe hinzu, um das dritte Wort vorherzusagen.
Dies ist eine autoregressive Vorhersage .
Das ist es, was LLMs tun, es ist kein neues Konzept, es gibt es schon seit Shannons Zeiten, also bis in die 50er Jahre, was lange her ist, aber die Veränderung besteht darin, dass wir jetzt diese massiven neuronalen Netzwerkarchitekturen haben, die man trainieren kann Es scheint, als würden daraus große Datenmengen und Funktionen entstehen.
Diese Art der autoregressiven Vorhersage weist jedoch einige wesentliche Einschränkungen auf, und es gibt hier keine wirkliche Begründung im üblichen Sinne.
Eine weitere Einschränkung besteht darin, dass dies nur für Daten in Form von diskreten Objekten, Symbolen, Tokens, Wörtern usw. funktioniert, also im Grunde Dinge, die diskretisiert werden können.
Wir vermissen immer noch etwas Wichtiges, wenn es darum geht, Intelligenz auf menschlicher Ebene zu erreichen.
Ich spreche hier nicht unbedingt von Intelligenz auf menschlicher Ebene, aber selbst Ihre Katze oder Ihr Hund können einige erstaunliche Leistungen vollbringen, die außerhalb der Reichweite aktueller KI-Systeme liegen.

Jeder 10-Jährige kann lernen, in einem Zug den Tisch abzuräumen und die Spülmaschine zu füllen, oder? Es ist kein Üben oder ähnliches nötig, oder?
Ein 17-Jähriger benötigt etwa 20 Übungsstunden, um das Autofahren zu erlernen.
Wir haben immer noch keine selbstfahrenden Autos der Stufe 5 und schon gar keine Heimroboter, die in der Lage sind, Tische abzuräumen und Geschirrspüler zu füllen.
Durch das Training allein auf Textbasis wird die KI niemals annähernd die menschliche Intelligenz erreichen
Es fehlt uns also wirklich etwas Wichtiges, das wir sonst mit KI-Systemen erreichen könnten.
Wir stoßen immer wieder auf etwas, das Moravecs Paradoxon genannt wird , nämlich dass Dinge, die uns trivial erscheinen und nicht einmal als intelligent gelten, mit Maschinen tatsächlich sehr schwer zu bewerkstelligen sind, und Dinge wie Manipulation komplexer abstrakter Denkweisen auf hoher Ebene wie die Sprache scheinen es zu sein sehr einfach für Maschinen, und das Gleiche gilt auch für Dinge wie Schach und Go.
Vielleicht ist einer der Gründe dieser.
Ein großes Sprachmodell (LLM) wird typischerweise auf 20 Billionen Token trainiert.
Ein Token besteht im Wesentlichen aus drei Vierteln eines Wortes. Daher gibt es insgesamt 1,5×10^13 Wörter. Jeder Token ist etwa 3B groß, normalerweise sind dafür 6×1013 Bytes erforderlich.
Es würde etwa ein paar hunderttausend Jahre dauern, bis einer von uns das liest, oder? Dabei handelt es sich im Grunde um alle öffentlichen Texte im Internet zusammen.

Aber denken Sie an ein Kind, das insgesamt 16.000 Stunden wach war. Wir haben 2 Millionen Sehnervenfasern, die in unser Gehirn gelangen. Jede Nervenfaser überträgt Daten mit etwa 1 B pro Sekunde, vielleicht einem halben Byte pro Sekunde. Einige Schätzungen gehen davon aus, dass dies 3 Milliarden pro Sekunde sein könnten.
Es spielt keine Rolle, es ist sowieso eine Größenordnung.
Diese Datenmenge beträgt ungefähr 10 hoch 14 Bytes, was fast der gleichen Größenordnung wie LLM entspricht. Ein Vierjähriger hat also in vier Jahren so viele visuelle Daten gesehen wie die größten Sprachmodelle, die mit öffentlich zugänglichen Texten im gesamten Internet trainiert wurden.
Wenn wir die Daten als Ausgangspunkt nehmen, verrät uns dies mehrere Dinge.
Erstens zeigt uns dies, dass wir niemals auch nur annähernd die menschliche Intelligenz erreichen werden, indem wir einfach nur am Text trainieren. Das wird einfach nicht passieren.
Zweitens sind visuelle Informationen sehr redundant. Jede Sehnervenfaser überträgt 1B an Informationen pro Sekunde, was im Vergleich zu den Photorezeptoren in Ihrer Netzhaut bereits um 100 zu 1 komprimiert ist.
In unserer Netzhaut befinden sich etwa 60 bis 100 Millionen Fotorezeptoren. Diese Photorezeptoren werden von Neuronen an der Vorderseite der Netzhaut zu 1 Million Nervenfasern komprimiert. Es liegt also bereits eine Komprimierung von 100 zu 1 vor. Bis sie dann das Gehirn erreichen, werden die Informationen etwa um das 50-fache erweitert.
Was ich also messe, sind komprimierte Informationen, die aber immer noch sehr redundant sind. Und Redundanz ist tatsächlich das, was selbstüberwachtes Lernen erfordert. Selbstüberwachtes Lernen lernt nur nützliche Dinge aus redundanten Daten. Wenn die Daten stark komprimiert sind, was bedeutet, dass die Daten zu zufälligem Rauschen werden, können Sie nichts lernen.
Sie brauchen Redundanz, um etwas zu lernen. Sie müssen die zugrunde liegende Struktur der Daten erlernen. Deshalb müssen wir das System trainieren, um gesunden Menschenverstand und Physik zu lernen, indem wir Videos ansehen oder in der realen Welt leben.
Die Reihenfolge meiner Worte mag etwas verwirrend sein. Ich möchte Ihnen hauptsächlich sagen, was diese zielgerichtete Architektur der künstlichen Intelligenz ist. Der Unterschied zu LLMs oder Feedforward-Neuronen besteht darin, dass der Inferenzprozess nicht nur eine Reihe von Schichten eines neuronalen Netzwerks durchläuft, sondern tatsächlich einen Optimierungsalgorithmus ausführt.
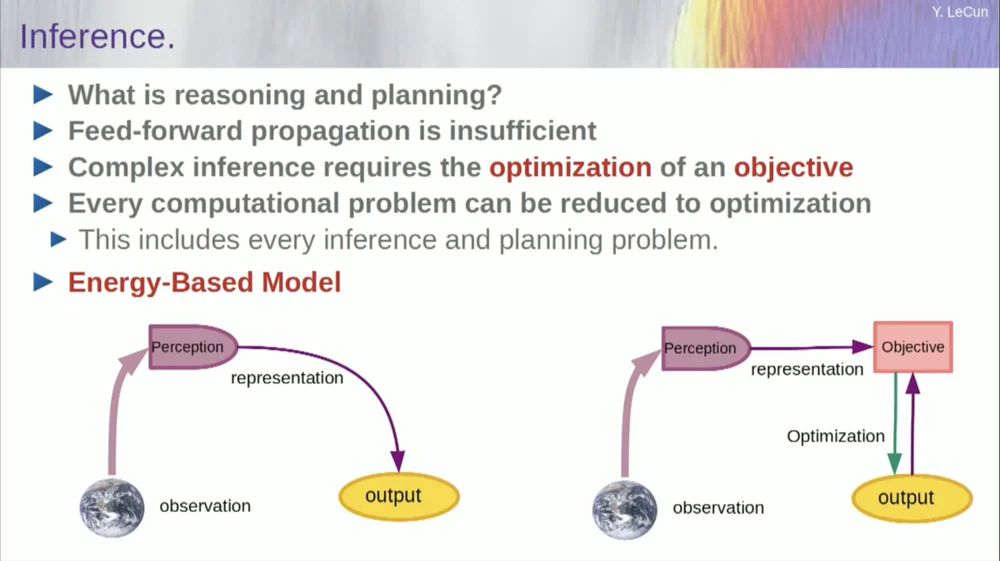
Konzeptionell sieht es so aus.
Ein Feedforward-Prozess ist ein Prozess, bei dem Beobachtungen ein Wahrnehmungssystem durchlaufen. Wenn Sie beispielsweise über eine Reihe neuronaler Netzwerkschichten verfügen und eine Ausgabe erzeugen, können Sie für jede einzelne Eingabe nur eine Ausgabe haben, aber in vielen Fällen kann es für eine Wahrnehmung mehrere mögliche Ausgabeinterpretationen geben. Sie benötigen einen Mapping-Prozess, der nicht nur die Funktionalität berechnet, sondern mehrere Ausgaben für eine einzelne Eingabe bereitstellt. Dies kann nur durch implizite Funktionen erreicht werden.
Im Grunde stellt das rote Kästchen auf der rechten Seite dieses Zielrahmens eine Funktion dar, die grundsätzlich die Kompatibilität zwischen einer Eingabe und ihrer vorgeschlagenen Ausgabe misst und dann die Ausgabe berechnet, indem sie den Ausgabewert ermittelt, der am besten mit der Eingabe kompatibel ist. Sie können sich vorstellen, dass dieses Ziel eine Art Energiefunktion ist und Sie diese Energie mit der Ausgabe als Variable minimieren.
Möglicherweise haben Sie mehrere Lösungen und Sie haben möglicherweise eine Möglichkeit, mit diesen mehreren Lösungen umzugehen. Dies gilt für das menschliche Wahrnehmungssystem. Wenn Sie mehrere Interpretationen einer bestimmten Wahrnehmung haben, wechselt Ihr Gehirn automatisch zwischen diesen Interpretationen. Es gibt also Hinweise darauf, dass so etwas tatsächlich passiert.
Aber lassen Sie mich auf die Architektur zurückkommen. Machen Sie sich also dieses Prinzip des Denkens durch Optimierung zunutze. Hier sind, wenn Sie so wollen, die Annahmen über die Funktionsweise des menschlichen Geistes. Sie machen Beobachtungen in der Welt. Das Wahrnehmungssystem gibt Ihnen eine Vorstellung vom aktuellen Zustand der Welt. Aber es vermittelt einem natürlich nur eine Vorstellung vom Zustand der Welt, den man aktuell wahrnehmen kann.
Möglicherweise erinnern Sie sich an einige Vorstellungen über den Zustand des Rests der Welt. Dies kann mit den Inhalten des Gedächtnisses kombiniert und in ein Weltmodell eingespeist werden.
Was ist ein Modell? Ein Weltmodell ist ein mentales Modell Ihres Verhaltens in der Welt. Sie können sich also eine Abfolge von Aktionen vorstellen, die Sie ergreifen könnten, und Ihr Weltmodell ermöglicht es Ihnen, die Auswirkungen dieser Aktionsabfolgen auf die Welt vorherzusagen.
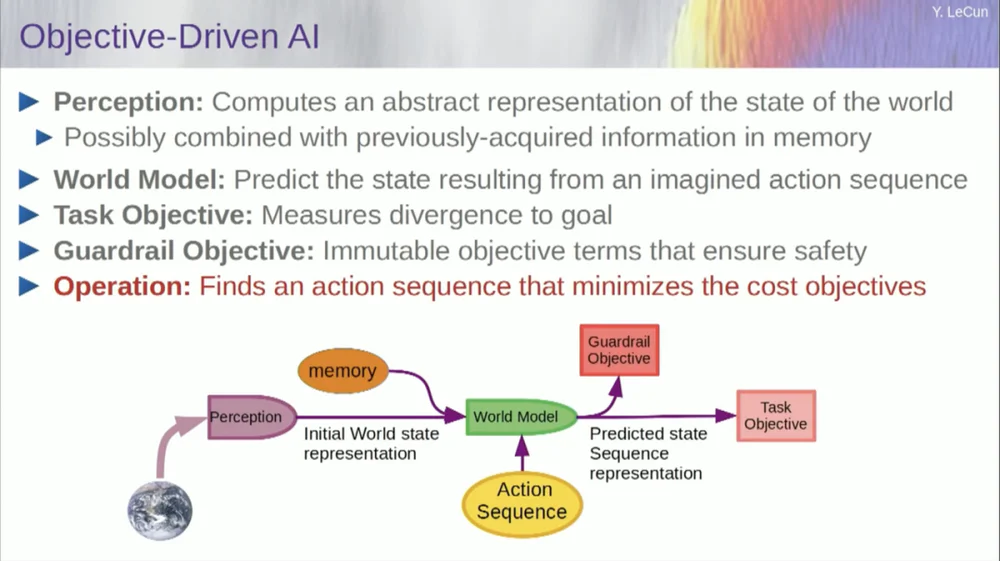
Das grüne Kästchen stellt also das Weltmodell dar, in das Sie eine hypothetische Abfolge von Aktionen einspeisen, die den Endzustand der Welt oder die gesamte von Ihnen vorhergesagte Flugbahn in der Welt vorhersagen.
Sie kombinieren das mit einer Reihe von Zielfunktionen. Ein Ziel besteht darin, zu messen, wie gut das Ziel erreicht wird, ob die Aufgabe abgeschlossen ist, und möglicherweise eine Reihe anderer Ziele, die als Sicherheitsmargen dienen. Im Wesentlichen wird gemessen, inwieweit die verfolgte Flugbahn oder die ergriffenen Maßnahmen keine Gefahr für den Roboter darstellen oder Leute um die Maschine herum usw. warten.
Der Prozess des Denkens (ich habe noch nicht über Lernen gesprochen) ist also nur noch Denken und besteht darin, Handlungssequenzen zu finden, die diese Ziele minimieren, und Handlungssequenzen zu finden, die diese Ziele minimieren. Dies ist der Argumentationsprozess.
Es handelt sich also nicht nur um einen Feedforward-Prozess. Sie könnten dies tun, indem Sie nach diskreten Optionen suchen, aber das ist nicht effizient. Ein besserer Ansatz besteht darin, sicherzustellen, dass alle diese Boxen differenzierbar sind. Sie können den Gradienten durch sie hindurch zurückpropagieren und dann die Abfolge der Aktionen über den Gradientenabstieg aktualisieren.

Nun ist diese Idee eigentlich nicht neu und gibt es schon seit über 60 Jahren, vielleicht sogar noch länger. Lassen Sie mich zunächst über die Vorteile sprechen, die sich aus der Verwendung eines Weltmodells für diese Art von Argumentation ergeben. Der Vorteil besteht darin, dass Sie neue Aufgaben ohne Lernaufwand erledigen können.
Wir machen das von Zeit zu Zeit. Wenn wir mit einer neuen Situation konfrontiert werden, denken wir darüber nach, stellen uns die Konsequenzen unseres Handelns vor und ergreifen dann eine Reihe von Maßnahmen, die unser Ziel (was auch immer es ist) erreichen. Wir müssen nicht lernen, diese Aufgabe zu erfüllen , wir können planen. Das ist also im Grunde Planung.
Sie können die meisten Argumentationsformen auf die Optimierung reduzieren. Daher ist der Prozess der Inferenz durch Optimierung von Natur aus leistungsfähiger, als einfach mehrere Schichten eines neuronalen Netzwerks zu durchlaufen. Wie gesagt, diese Idee des Denkens durch Optimierung gibt es schon seit über 60 Jahren.
Im Bereich der Theorie der optimalen Regelung spricht man von modellprädiktiver Regelung.
Sie haben ein Modell eines Systems, das Sie steuern möchten, beispielsweise eine Rakete, ein Flugzeug oder einen Roboter. Sie können sich vorstellen, Ihr Weltmodell zu verwenden, um die Auswirkungen einer Reihe von Steuerbefehlen zu berechnen.
Anschließend optimieren Sie diesen Ablauf so, dass die Bewegung Ihre gewünschten Ergebnisse erzielt. Die gesamte Bewegungsplanung in der klassischen Robotik erfolgt auf diese Weise und ist nichts Neues. Das Neue dabei ist, dass wir ein Modell der Welt lernen und das Wahrnehmungssystem eine geeignete abstrakte Darstellung extrahieren wird.
Bevor ich nun auf ein Beispiel für den Betrieb dieses Systems eingehe, können Sie ein Gesamt-KI-System mit all diesen Komponenten aufbauen: einem Weltmodell, einer Kostenfunktion, die für die jeweilige Aufgabe konfiguriert werden kann, einem Optimierungsmodul (d. h. wirklich optimieren, das gegebene Modul finden, das die optimale Abfolge von Aktionen für das Weltmodell bestimmt) , Kurzzeitgedächtnis, Wahrnehmungssystem usw.
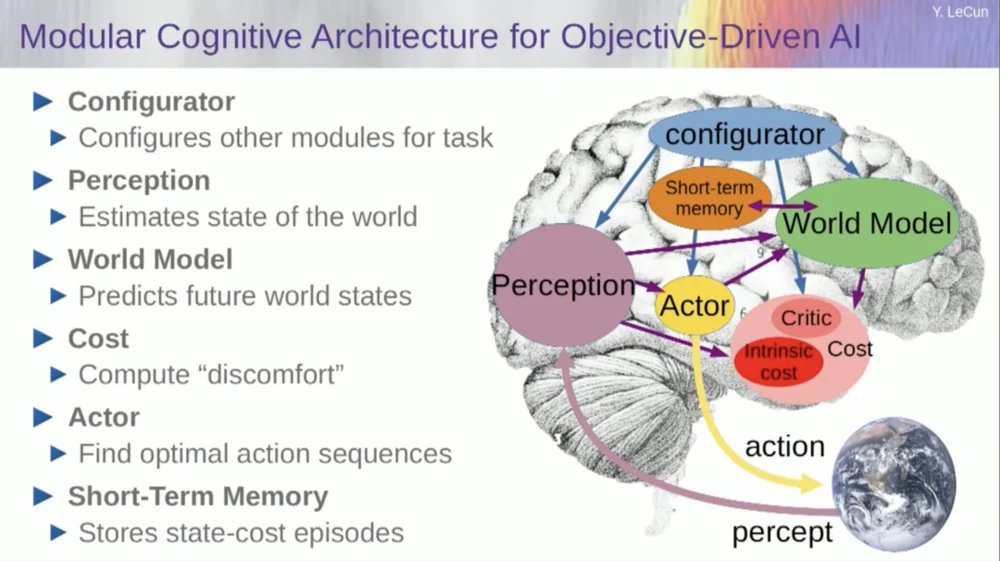
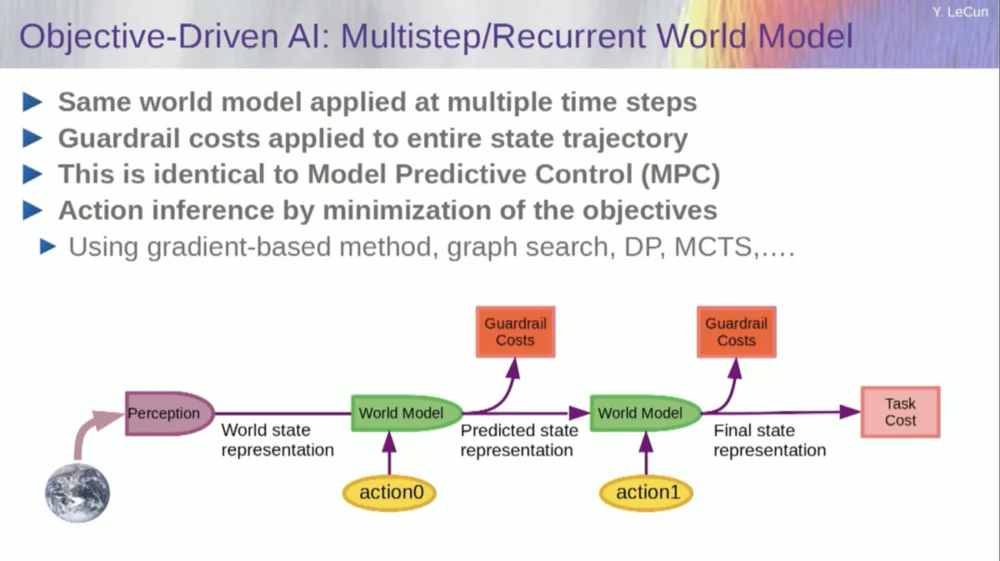
Wie funktioniert das? Wenn es sich bei Ihrer Aktion nicht um eine einzelne Aktion, sondern um eine Abfolge von Aktionen handelt und Ihr Weltmodell tatsächlich ein System ist, das Ihnen sagt, dass Sie anhand des Weltzustands zum Zeitpunkt T und möglicher Aktionen den Weltzustand zum Zeitpunkt T+1 vorhersagen können.
Sie möchten vorhersagen, welche Auswirkung eine Abfolge von zwei Aktionen in dieser Situation haben wird. Um dies zu erreichen, können Sie Ihr Weltmodell mehrmals ausführen.
Erhalten Sie die anfängliche Weltzustandsdarstellung, geben Sie die Annahme Null für die Aktion ein, verwenden Sie das Modell, um den nächsten Zustand vorherzusagen, führen Sie dann Aktion eins aus, berechnen Sie den nächsten Zustand, berechnen Sie die Kosten und verwenden Sie dann Backpropagation- und Gradienten-basierte Optimierungsmethoden, um Finden Sie heraus, was die Kosten zweier Aktionen minimiert. Dies ist eine modellprädiktive Steuerung.
Da die Welt nicht vollständig deterministisch ist, müssen Sie latente Variablen verwenden, um Ihr Weltmodell anzupassen. Latente Variablen sind grundsätzlich Variablen, die innerhalb eines Datensatzes umgeschaltet oder aus einer Verteilung entnommen werden können. Sie stellen den Wechsel eines Weltmodells zwischen mehreren Vorhersagen dar, die mit Beobachtungen kompatibel sind.
Noch interessanter ist, dass intelligente Systeme derzeit nicht in der Lage sind, etwas zu tun, was Menschen und sogar Tiere tun können, nämlich hierarchische Planung.
Wenn Sie beispielsweise eine Reise von New York nach Paris planen, könnten Sie Ihr Verständnis der Welt, Ihren Körper und vielleicht Ihre Vorstellung von der gesamten Konfiguration der Anreise von hier nach Paris nutzen, um Ihre gesamte Reise mit Ihnen zu planen geringe Muskelkontrolle.
Rechts? Wenn man die Anzahl der Muskelkontrollschritte pro zehn Millisekunden all der Dinge zusammenzählt, die man vor der Reise nach Paris erledigen muss, ist das eine riesige Zahl. Was Sie also tun, ist eine hierarchische Planung, bei der Sie auf einer sehr hohen Ebene beginnen und sagen: Okay, um nach Paris zu kommen, muss ich zuerst zum Flughafen und in ein Flugzeug steigen.
Wie komme ich zum Flughafen? Nehmen wir an, ich bin in New York City und muss nach unten gehen und ein Taxi nehmen. Wie komme ich nach unten? Ich muss vom Stuhl aufstehen, die Tür öffnen, zum Aufzug gehen, den Knopf drücken usw. Wie stehe ich von einem Stuhl auf?
Irgendwann muss man Dinge als untergeordnete Muskelkontrollaktionen ausdrücken, aber wir planen das Ganze nicht auf untergeordneter Ebene, sondern führen eine hierarchische Planung durch.

Wie dies mithilfe von KI-Systemen bewerkstelligt werden kann, ist noch völlig ungelöst und wir haben keine Ahnung.
Dies scheint eine wichtige Voraussetzung für intelligentes Verhalten zu sein.
Wie lernen wir also Weltmodelle, die zu hierarchischer Planung fähig sind und auf verschiedenen Abstraktionsebenen arbeiten können? Niemand hat etwas Ähnliches gezeigt. Das ist eine große Herausforderung. Das Bild zeigt das gerade erwähnte Beispiel.
Wie trainieren wir nun dieses Weltmodell? Denn das ist in der Tat ein großes Problem.
Ich versuche herauszufinden, in welchem Alter Babys grundlegende Konzepte über die Welt lernen. Wie lernen sie intuitive Physik, körperliche Intuition und all das Zeug? Dies geschieht lange bevor sie anfangen, Dinge wie Sprache und Interaktion zu lernen.
Funktionen wie die Gesichtsverfolgung kommen also tatsächlich sehr früh zum Einsatz. Auch die biologische Bewegung, die Unterscheidung zwischen belebten und unbelebten Objekten, taucht schon früh auf. Dasselbe gilt für die Objektkonstanz, die sich auf die Tatsache bezieht, dass ein Objekt bestehen bleibt, wenn es von einem anderen Objekt verdeckt wird.
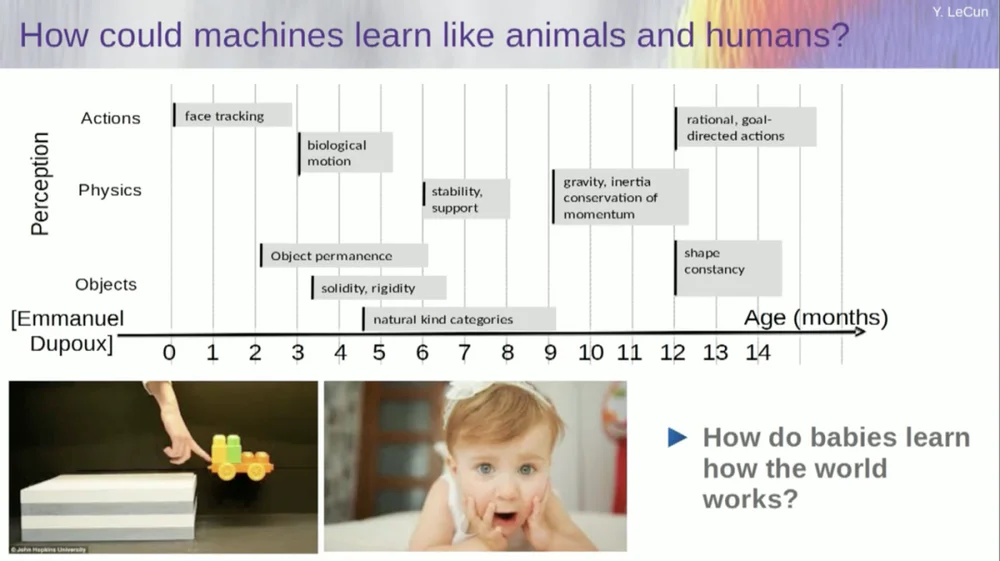
Und Babys lernen auf natürliche Weise, man muss ihnen keine Namen für Dinge geben. Sie werden wissen, dass Stühle, Tische und Katzen unterschiedlich sind. Konzepte wie Stabilität und Halt, also Schwerkraft, Trägheit, Erhaltung und Impuls, tauchen tatsächlich erst im Alter von etwa neun Monaten auf.
Das dauert lange. Wenn Sie also einem sechs Monate alten Baby das Szenario links zeigen, in dem der Wagen auf einer Plattform steht und Sie ihn von der Plattform stoßen, scheint er in der Luft zu schweben. Ein sechs Monate altes Baby wird dies bemerken, während ein zehn Monate altes Baby das Gefühl hat, dass dies nicht passieren sollte und dass der Gegenstand fallen sollte.
Wenn etwas Unerwartetes passiert, bedeutet das, dass Ihr „Modell der Welt“ falsch ist. Passen Sie also auf, denn es könnte Sie töten.
Die Art des Lernens, die hier stattfinden muss, ist also der Art des Lernens, die wir zuvor besprochen haben, sehr ähnlich.
Nehmen Sie die Eingabe, verfälschen Sie sie auf irgendeine Weise und trainieren Sie ein großes neuronales Netzwerk, um die fehlenden Teile vorherzusagen. Wenn Sie einem System beibringen, vorherzusagen, was in einem Video passieren wird, so wie wir neuronale Netze trainieren, vorherzusagen, was in einem Text passieren wird, können diese Systeme vielleicht den gesunden Menschenverstand lernen.
Leider haben wir das zehn Jahre lang versucht und es war ein völliger Fehlschlag. Wir sind noch nie an ein System herangekommen, das tatsächlich Allgemeinwissen erlernen kann, indem es einfach versucht, Pixel in einem Video vorherzusagen.
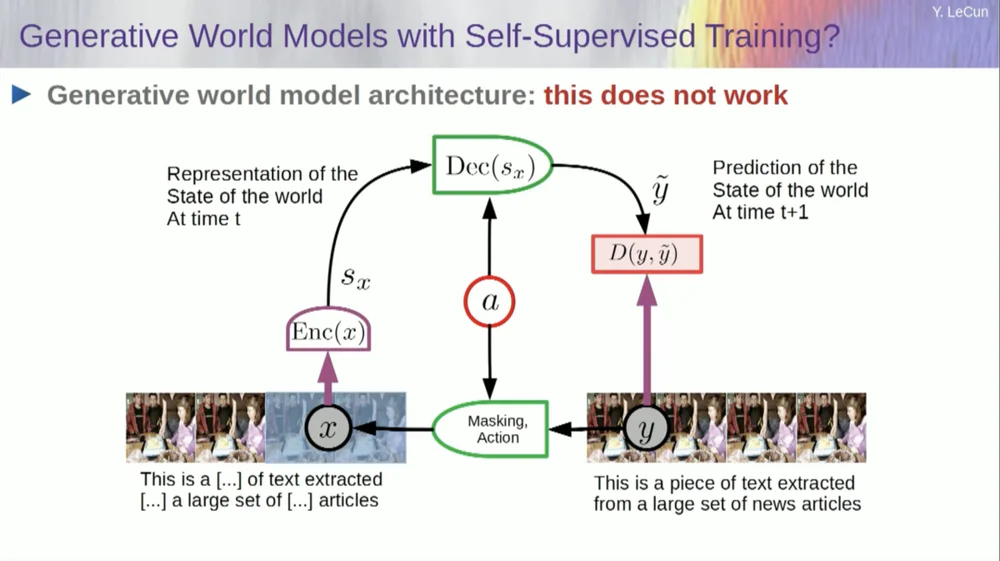
Sie können einem System beibringen, Videos vorherzusagen, die gut aussehen. Es gibt viele Beispiele für Videoerzeugungssysteme, aber intern sind sie keine guten Modelle der physischen Welt. Wir können das nicht mit ihnen machen.
Okay, die Idee, dass wir generative Modelle verwenden, um vorherzusagen, was mit Individuen passieren wird, und dass das System auf magische Weise die Struktur der Welt verstehen wird, ist ein völliger Fehlschlag.
Im letzten Jahrzehnt haben wir viele Ansätze ausprobiert.
Es scheitert, weil es viele mögliche Zukünfte gibt. In einem diskreten Raum wie Text, in dem Sie vorhersagen können, welches Wort auf eine Wortfolge folgt, können Sie eine Wahrscheinlichkeitsverteilung über die möglichen Wörter in einem Wörterbuch erstellen. Aber wenn es um Videobilder geht, haben wir keine gute Möglichkeit, die Wahrscheinlichkeitsverteilung von Videobildern darzustellen. Tatsächlich ist diese Aufgabe völlig unmöglich.

Ich habe doch ein Video von diesem Raum gemacht, oder? Ich nahm die Kamera, filmte diesen Teil und stoppte dann das Video. Ich habe das System gefragt, was als nächstes passieren würde. Es könnte die verbleibenden Räume vorhersagen. Es wird eine Wand geben, darauf werden Menschen sitzen, und die Dichte wird wahrscheinlich der auf der linken Seite ähneln, aber es ist absolut unmöglich, auf Pixelebene alle Details genau vorherzusagen, wie jeder von Ihnen aussehen wird , die Beschaffenheit der Welt und die genaue Größe des Raumes.
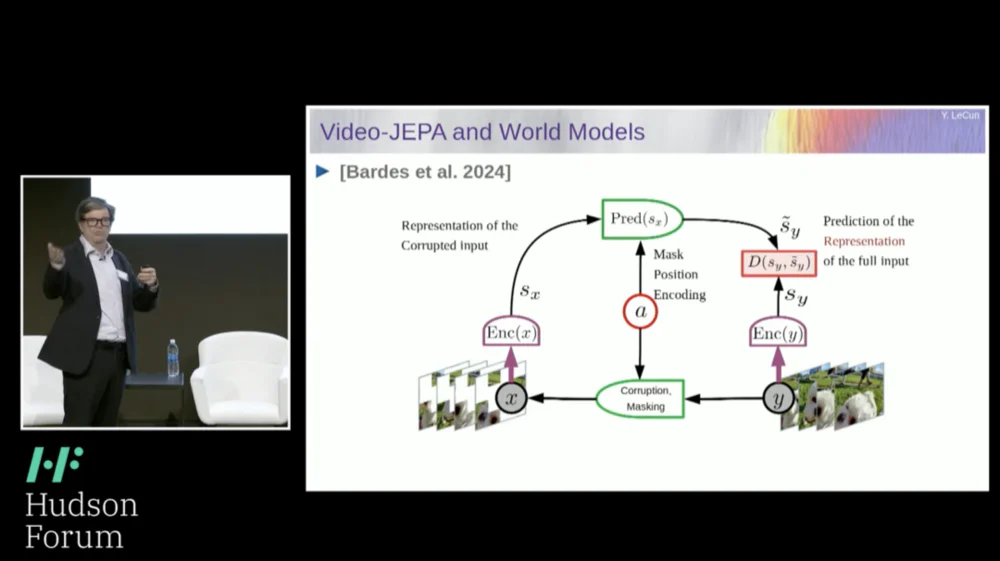
Daher ist mein Lösungsvorschlag die Joint Embedding Prediction Architecture (JEPA) .
Die Idee besteht darin, die Vorhersage von Pixeln aufzugeben und stattdessen eine abstrakte Darstellung der Funktionsweise der Welt zu lernen und dann innerhalb dieses Darstellungsraums Vorhersagen zu treffen. Das ist die Architektur, die gemeinsame Einbettungsvorhersagearchitektur. Diese beiden Einbettungen nehmen X (die beschädigte Version) bzw. Y an, werden vom Encoder verarbeitet und dann wird das System darauf trainiert, die Darstellung von Y basierend auf der Darstellung von X vorherzusagen.
Das Problem besteht nun darin, dass ein solches System zusammenbricht, wenn man es nur mit Gradientenabstieg und Backpropagation trainiert, um den Vorhersagefehler zu minimieren. Es könnte eine konstante Darstellung erlernen, sodass Vorhersagen sehr einfach, aber wenig aussagekräftig werden.
Ich möchte Sie also daran erinnern, dass es einen Unterschied zwischen Autoencodern, generativen Architekturen, maskierten Autoencodern usw. gibt, die versuchen, Vorhersagen zu rekonstruieren, und gemeinsamen Einbettungsarchitekturen, die Vorhersagen im Darstellungsraum treffen.
Ich denke, die Zukunft liegt in diesen gemeinsamen Einbettungsarchitekturen, und wir haben viele empirische Beweise dafür, dass der beste Weg, gute Bilddarstellungen zu erlernen, darin besteht, gemeinsame Bearbeitungsarchitekturen zu verwenden.
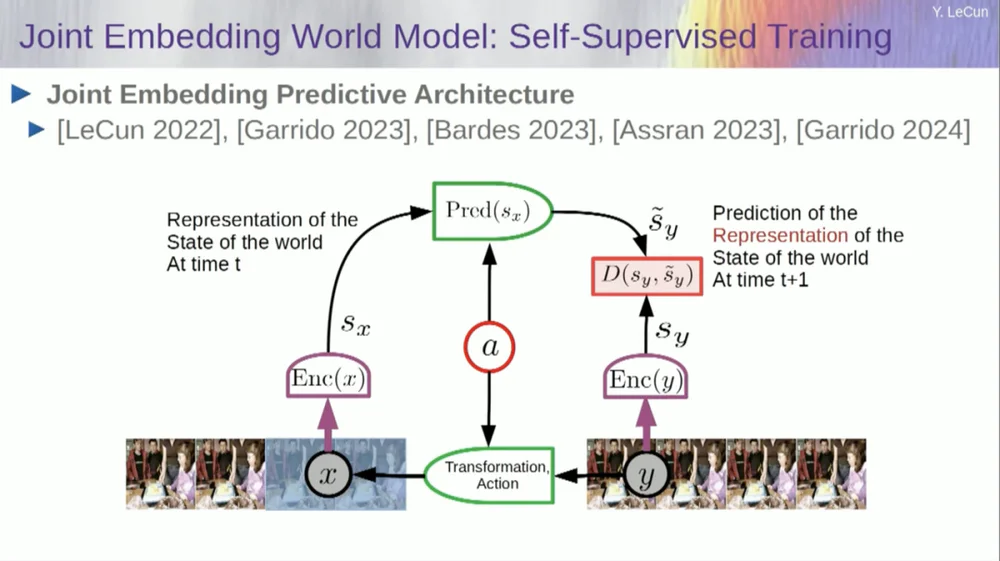
Alle Versuche, Bilddarstellungen durch Rekonstruktion zu lernen, waren schlecht und funktionieren nicht gut, und obwohl es viele große Projekte gibt, die behaupten, dass sie funktionieren, ist dies nicht der Fall, und die beste Leistung wird mit der Architektur auf der rechten Seite erzielt.
Wenn Sie darüber nachdenken, dann geht es bei unserer Intelligenz wirklich darum: Eine gute Darstellung eines Phänomens zu finden, damit wir Vorhersagen treffen können, darum geht es in der Wissenschaft wirklich.
real. Denken Sie darüber nach: Wenn Sie die Flugbahn eines Planeten vorhersagen möchten, ist ein Planet ein sehr komplexes Objekt, er ist riesig und weist alle möglichen Eigenschaften wie Wetter, Temperatur und Dichte auf.
Obwohl es sich um ein komplexes Objekt handelt, müssen Sie zur Vorhersage der Flugbahn eines Planeten nur 6 Zahlen kennen: 3 Positionskoordinaten und 3 Geschwindigkeitsvektoren, das war's, Sie müssen nichts weiter tun. Dies ist ein sehr wichtiges Beispiel, das wirklich zeigt, dass das Wesen der Vorhersagekraft darin liegt, eine gute Darstellung der Dinge zu finden, die wir beobachten.

Wie trainieren wir also ein solches System?
Sie möchten also verhindern, dass das System abstürzt. Eine Möglichkeit, dies zu erreichen, besteht darin, eine Art Kostenfunktion zu verwenden, die den Informationsgehalt der vom Encoder ausgegebenen Darstellung misst und versucht, den Informationsgehalt zu maximieren und negative Informationen zu minimieren. Ihr Trainingssystem sollte gleichzeitig so viele Informationen wie möglich aus der Eingabe extrahieren und gleichzeitig den Vorhersagefehler in diesem Darstellungsraum minimieren.
Das System findet einen Kompromiss zwischen der Extraktion möglichst vieler Informationen und der Vermeidung der Extraktion unvorhersehbarer Informationen. Sie erhalten einen guten Darstellungsraum, in dem Vorhersagen getroffen werden können.
Wie misst man nun Informationen? Hier wird es etwas seltsam. Ich werde das überspringen.
Maschinen werden die menschliche Intelligenz übertreffen und sicher und kontrollierbar sein
Es gibt tatsächlich eine Möglichkeit, dies mathematisch durch Training, energiebasierte Modelle und Energiefunktionen zu verstehen, aber ich habe keine Zeit, darauf einzugehen.
Im Grunde erzähle ich Ihnen hier ein paar verschiedene Dinge: Verzichte auf generative Modelle zugunsten dieser JEPA-Architekturen, verzichte auf probabilistische Modelle zugunsten dieser energiebasierten Modelle, verzichte auf kontrastive Lernmethoden und verstärktes Lernen. Das sage ich schon seit 10 Jahren.
Und das sind heute die vier beliebtesten Säulen des maschinellen Lernens. Daher bin ich im Moment wahrscheinlich nicht sehr beliebt.
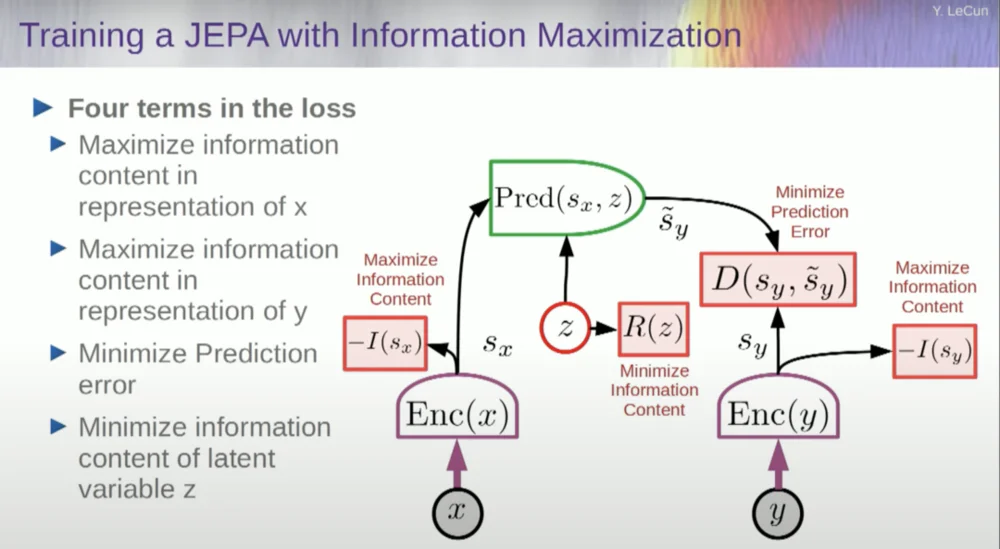
Ein Ansatz besteht darin, den Informationsgehalt zu schätzen, indem der vom Encoder kommende Informationsgehalt gemessen wird.
Derzeit gibt es sechs verschiedene Möglichkeiten, dies zu erreichen. Tatsächlich gibt es hier eine Methode namens MCR von meinen Kollegen an der NYU, die verhindern soll, dass das System abstürzt und Konstanten erzeugt.
Nehmen Sie die Variablen vom Encoder und stellen Sie sicher, dass diese Variablen eine Standardabweichung ungleich Null aufweisen. Sie könnten dies in eine Kostenfunktion einfügen und sicherstellen, dass die Gewichte durchsucht werden und die Variablen nicht zusammenbrechen und zu Konstanten werden. Das ist relativ einfach.
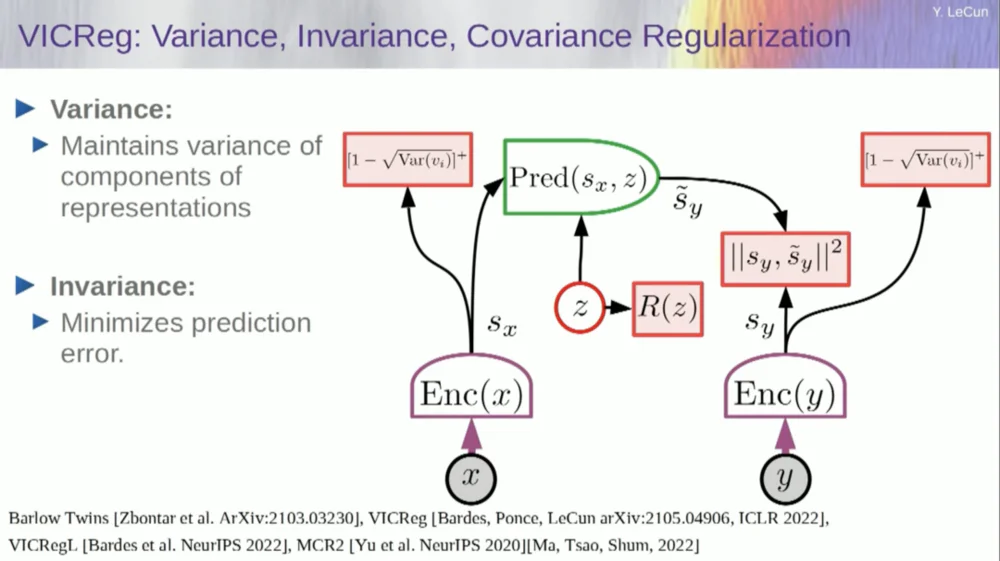
Das Problem besteht nun darin, dass das System „schummeln“ und alle Variablen gleich oder stark korrelieren lassen kann. Daher müssen Sie einen weiteren Term hinzufügen, den Off-Diagonal-Term, der zur Minimierung der Kovarianzmatrix dieser Variablen erforderlich ist, um sicherzustellen, dass sie miteinander in Beziehung stehen.
Dies reicht natürlich nicht aus, da die Variablen möglicherweise immer noch abhängig, aber nicht miteinander verbunden sind. Daher wenden wir eine andere Methode an, um die Dimensionen von SX auf einen höherdimensionalen Raum VX zu erweitern und in diesem Raum eine Varianz-Kovarianz-Regularisierung anzuwenden, um sicherzustellen, dass die Anforderungen erfüllt werden.
Hier gibt es noch einen weiteren Trick, denn was ich maximiere, ist die Obergrenze des Informationsgehalts. Ich möchte, dass der tatsächliche Informationsgehalt meiner Maximierung der Obergrenze folgt. Was ich brauche, ist eine Untergrenze, damit die Untergrenze verschoben wird und die Informationen zunehmen. Leider haben wir keine Informationen über Untergrenzen oder wissen zumindest nicht, wie man sie berechnet.
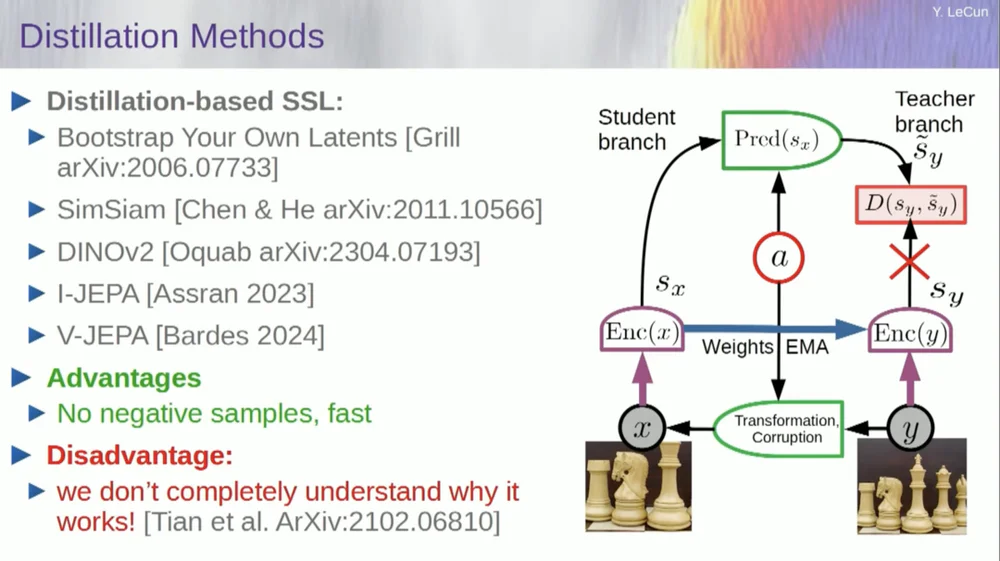
Es gibt eine zweite Reihe von Methoden, die als „Methode im Destillationsstil“ bezeichnet werden.
Diese Methode funktioniert auf mysteriöse Weise. Wenn Sie genau wissen möchten, wer was macht, fragen Sie den Mann, der hier am Grill sitzt.
Er hat dazu einen persönlichen Aufsatz, der es sehr gut definiert. Seine Kernidee besteht darin, nur einen Teil des Modells zu aktualisieren, ohne Gradienten im anderen Teil zurückzupropagieren, und die Gewichte auf interessante Weise zu teilen. Auch zu diesem Aspekt gibt es viele Veröffentlichungen.
Dieser Ansatz funktioniert gut, wenn Sie ein vollständig selbstüberwachtes System trainieren möchten, um gute Bilddarstellungen zu generieren. Die Zerstörung von Bildern erfolgt durch Maskierung, und einige neuere Arbeiten, die wir für Videos durchgeführt haben, ermöglichen es uns, ein System zu trainieren, um gute Videodarstellungen für die Verwendung in nachgelagerten Aufgaben wie Aktionserkennungsvideos usw. zu extrahieren. Sie können sehen, dass das Ausblenden eines großen Teils eines Videos und das Treffen von Vorhersagen durch diesen Prozess diesen Destillationstrick im Darstellungsraum nutzt, um einen Kollaps zu verhindern. Das funktioniert großartig.
Wenn wir also bei diesem Projekt Erfolg haben und am Ende Systeme haben, die die physische Welt begründen, planen und verstehen können, werden alle unsere Interaktionen in der Zukunft so aussehen.
Es wird Jahre, vielleicht sogar ein Jahrzehnt dauern, bis alles richtig funktioniert. Mark Zuckerberg fragt mich immer wieder, wie lange es dauern wird. Wenn uns das gelingt, werden wir über Systeme verfügen, die alle unsere Interaktionen mit der digitalen Welt vermitteln. Sie werden alle unsere Fragen beantworten.
Sie werden noch lange bei uns bleiben und im Wesentlichen einen Speicher für das gesamte menschliche Wissen bilden. Das fühlt sich an wie eine Infrastruktursache, wie das Internet. Dabei handelt es sich weniger um ein Produkt als vielmehr um eine Infrastruktur.
Diese KI-Plattformen müssen Open Source sein. IBM und Meta beteiligen sich an einer Gruppe namens Artificial Intelligence Alliance, die Open-Source-Plattformen für künstliche Intelligenz fördert. Wir brauchen, dass diese Plattformen Open Source sind, weil wir Vielfalt in diesen KI-Systemen brauchen.

Wir brauchen sie, um alle Sprachen, alle Kulturen, alle Wertesysteme der Welt zu verstehen, und das können Sie nicht mit nur einem einzigen System erreichen, das von einem Unternehmen an der West- oder Ostküste der Vereinigten Staaten entwickelt wurde Staaten. Dies muss ein Beitrag aus der ganzen Welt sein.
Natürlich ist die Schulung von Finanzmodellen sehr teuer, daher sind nur wenige Unternehmen dazu in der Lage. Wenn Unternehmen wie Meta das zugrunde liegende Modell als Open Source bereitstellen können, kann die Welt es für ihre eigenen Zwecke optimieren. Dies ist die Philosophie, die von Meta und IBM übernommen wird.

Open-Source-KI ist also nicht nur eine gute Idee, sie ist auch notwendig für die kulturelle Vielfalt und vielleicht sogar für den Erhalt der Demokratie.
Schulung und Feinabstimmung erfolgen durch Crowdsourcing oder durch ein Ökosystem aus Startups und anderen Unternehmen.
Eines der Dinge, die das Wachstum des KI-Startup-Ökosystems vorantreiben, ist die Verfügbarkeit dieser Open-Source-KI-Modelle. Wie lange wird es dauern, bis wir eine allgemeine künstliche Intelligenz erreichen? Ich weiß es nicht, es könnte Jahre bis Jahrzehnte dauern.

Im Laufe der Zeit hat es viele Veränderungen gegeben, und es gibt immer noch viele Probleme, die gelöst werden müssen. Das wird mit ziemlicher Sicherheit schwieriger sein, als wir denken. Dies geschieht nicht an einem Tag, sondern ist eine schrittweise, schrittweise Entwicklung.
Es ist also nicht so, dass wir eines Tages das Geheimnis der allgemeinen künstlichen Intelligenz entdecken, die Maschine einschalten und sofort über Superintelligenz verfügen und wir alle von der Superintelligenz ausgelöscht werden, nein, das ist nicht der Fall.
Maschinen werden die menschliche Intelligenz übertreffen, aber sie werden unter Kontrolle sein, weil sie zielorientiert sind. Wir setzen ihnen Ziele und sie erreichen diese. Wie viele von uns hier sind wir Führungspersönlichkeiten in der Industrie oder im akademischen Bereich.
Wir arbeiten mit Menschen zusammen, die schlauer sind als wir, und das tue ich ganz bestimmt auch. Nur weil es viele Leute gibt, die schlauer sind als ich, heißt das nicht, dass sie dominieren oder übernehmen wollen, das ist einfach die Wahrheit. Natürlich stecken Risiken dahinter, aber das überlasse ich später der Diskussion, vielen Dank.