Im Bereich der Generierung und des Verständnisses von KI-Bildern stehen bestehende Modelle häufig vor der Herausforderung, Verständnis und Generierungsfähigkeiten in Einklang zu bringen. Sie sind ineffizient und basieren auf einer großen Anzahl vorab trainierter Komponenten. Das von DeepSeek AI eingeführte JanusFlow-Framework bietet eine neue Idee zur Lösung dieses Problems. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefes Verständnis dafür, wie JanusFlow durch innovatives Architekturdesign die Vereinheitlichung von Bildverständnis und -generierung erreicht und bemerkenswerte Ergebnisse erzielt.
Trotz der schnellen Fortschritte im Bereich der KI-gesteuerten Bildgenerierung und -erkennung bleiben erhebliche Herausforderungen bestehen, die die Entwicklung eines nahtlosen, einheitlichen Ansatzes behindern.
Derzeit sind Modelle, die sich auf das Bildverständnis konzentrieren, bei der Generierung qualitativ hochwertiger Bilder tendenziell leistungsschwach und umgekehrt. Diese aufgabengetrennte Architektur erhöht nicht nur die Komplexität, sondern schränkt auch die Effizienz ein, wodurch die Bearbeitung von Aufgaben, die sowohl Verständnis als auch Generierung erfordern, umständlich wird. Darüber hinaus sind viele bestehende Modelle zu stark auf Architekturänderungen oder vorab trainierte Komponenten angewiesen, um eine Funktion effektiv auszuführen, was zu Leistungseinbußen und Integrationsproblemen führt.
Um diese Probleme zu lösen, hat DeepSeek AI JanusFlow auf den Markt gebracht, ein leistungsstarkes KI-Framework, das das Verständnis und die Generierung von Bildern vereinheitlichen soll. JanusFlow löst die zuvor genannten Ineffizienzen, indem es Bildverständnis und -generierung in eine einheitliche Architektur integriert. Dieses neuartige Framework zeichnet sich durch ein minimalistisches Design aus, das autoregressive Sprachmodelle mit Rectified Flow, einem hochmodernen generativen Modellierungsansatz, kombiniert.
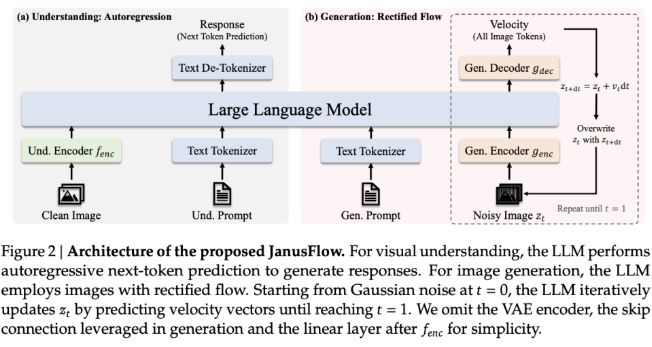
Durch den Wegfall separater LLM- und Generierungskomponenten ermöglicht JanusFlow eine engere funktionale Integration bei gleichzeitiger Reduzierung der Architekturkomplexität. Es führt eine duale Encoder-Decoder-Struktur ein, entkoppelt Verständnis- und Generierungsaufgaben und sorgt durch die Ausrichtung von Darstellungen für Leistungskonsistenz in einem einheitlichen Trainingsschema.
Was die technischen Details betrifft, integriert JanusFlow Korrekturflüsse und große Sprachmodelle auf einfache und effiziente Weise. Die Architektur umfasst unabhängige visuelle Encoder für Verständnis- und Generierungsaufgaben. Während des Trainings werden diese Encoder aufeinander abgestimmt, um die semantische Konsistenz zu verbessern, sodass das System bei Bilderzeugungs- und visuellen Verständnisaufgaben gute Leistungen erbringen kann.
Diese Entkopplung der Encoder verhindert Interferenzen zwischen Aufgaben und verbessert dadurch die Fähigkeiten jedes Moduls. Das Modell verwendet außerdem klassifikatorfreie Führung (CFG), um die Ausrichtung zwischen generierten Bildern und Textbedingungen zu steuern und so die Bildqualität zu verbessern. Im Vergleich zu herkömmlichen einheitlichen Systemen, die Diffusionsmodelle als externe Tools verwenden, bietet JanusFlow einen einfacheren und direkteren Generierungsprozess mit weniger Einschränkungen. Die Wirksamkeit dieser Architektur wird durch ihre Fähigkeit demonstriert, die Leistung vieler aufgabenspezifischer Modelle bei mehreren Benchmarks zu erreichen oder zu übertreffen.
Die Bedeutung von JanusFlow liegt in seiner Effizienz und Vielseitigkeit und schließt eine kritische Lücke in der multimodalen Modellentwicklung. Durch den Wegfall der Notwendigkeit unabhängiger Generierungs- und Verständnismodule ermöglicht JanusFlow Forschern und Entwicklern, ein einziges Framework für mehrere Aufgaben zu nutzen und so die Komplexität und den Ressourcenverbrauch erheblich zu reduzieren.
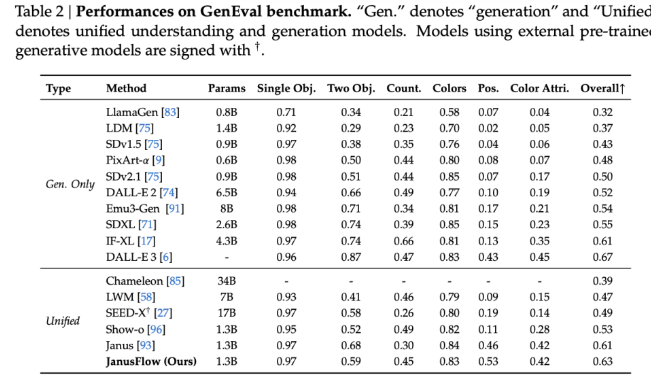
Benchmark-Ergebnisse zeigen, dass JanusFlow viele bestehende einheitliche Modelle mit Werten von 74,9, 70,5 und 60,3 bei MMBench, SeedBench und GQA übertrifft. In Bezug auf die Bilderzeugung übertraf JanusFlow SDv1.5 und SDXL mit einem Wert von 9,51 für MJHQ FID-30k und einem Wert von 0,63 für GenEval. Diese Metriken belegen seine hervorragende Fähigkeit, qualitativ hochwertige Bilder zu erzeugen und komplexe multimodale Aufgaben mit nur 1,3 Milliarden Parametern zu bewältigen.
Zusammenfassend lässt sich sagen, dass JanusFlow einen wichtigen Schritt in Richtung Entwicklung eines einheitlichen KI-Modells getan hat, das gleichzeitig Bildverständnis und -generierung ermöglicht. Sein minimalistischer Ansatz, der sich auf die Integration autoregressiver Fähigkeiten mit korrigierenden Abläufen konzentriert, verbessert nicht nur die Leistung, sondern vereinfacht auch die Modellarchitektur, wodurch sie effizienter und zugänglicher wird.
Durch die Entkopplung des visuellen Encoders und die Ausrichtung der Darstellungen während des Trainings gelingt es JanusFlow, Bildverständnis und -generierung erfolgreich zu verbinden. Da die KI-Forschung weiterhin die Grenzen der Modellfähigkeiten verschiebt, stellt JanusFlow einen wichtigen Meilenstein auf dem Weg zur Schaffung vielseitigerer und vielseitigerer multimodaler KI-Systeme dar.
Modell: https://huggingface.co/deepseek-ai/JanusFlow-1.3B
Papier: https://arxiv.org/abs/2411.07975
Insgesamt hat JanusFlow mit seiner effizienten Architektur und hervorragenden Leistung großes Potenzial im Bereich der multimodalen KI gezeigt und eine neue Richtung für die Entwicklung zukünftiger KI-Modelle aufgezeigt. Wir freuen uns darauf, dass JanusFlow in weiteren Anwendungsszenarien eine Rolle spielt!