Mit der rasanten Entwicklung der KI-Technologie wächst die Nachfrage nach visuellen Sprachmodellen von Tag zu Tag, doch der hohe Bedarf an Rechenressourcen schränkt ihre Anwendung auf gewöhnlichen Geräten ein. Der Herausgeber von Downcodes stellt Ihnen heute ein leichtes visuelles Sprachmodell namens SmolVLM vor, das effizient auf Geräten mit begrenzten Ressourcen wie Laptops und GPUs für Endverbraucher ausgeführt werden kann. Das Aufkommen von SmolVLM hat mehr Benutzern die Möglichkeit gegeben, fortschrittliche KI-Technologie kennenzulernen, die Einsatzschwelle gesenkt und Entwicklern auch praktischere Recherchetools zur Verfügung gestellt.
In den letzten Jahren gab es eine zunehmende Nachfrage nach der Anwendung von Modellen des maschinellen Lernens bei Seh- und Sprachaufgaben, aber die meisten Modelle erfordern enorme Rechenressourcen und können auf persönlichen Geräten nicht effizient ausgeführt werden. Besonders kleine Geräte wie Laptops, Consumer-GPUs und mobile Geräte stehen bei der Verarbeitung visueller Sprachaufgaben vor großen Herausforderungen.
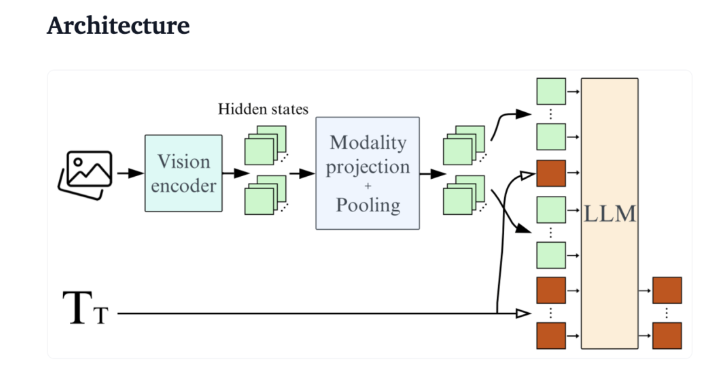
Am Beispiel von Qwen2-VL weist es zwar eine hervorragende Leistung auf, stellt jedoch hohe Hardwareanforderungen, was seine Verwendbarkeit in Echtzeitanwendungen einschränkt. Daher ist die Entwicklung leichter Modelle, die mit geringeren Ressourcen betrieben werden können, zu einem wichtigen Bedarf geworden.
Hugging Face hat kürzlich SmolVLM veröffentlicht, ein visuelles Sprachmodell mit 2B-Parametern, das speziell für das geräteseitige Denken entwickelt wurde. SmolVLM übertrifft andere ähnliche Modelle hinsichtlich der GPU-Speichernutzung und der Geschwindigkeit der Token-Generierung. Sein Hauptmerkmal ist die Fähigkeit, effizient auf kleineren Geräten wie Laptops oder Consumer-GPUs zu laufen, ohne dass die Leistung darunter leidet. SmolVLM findet ein ideales Gleichgewicht zwischen Leistung und Effizienz und löst Probleme, die bei früheren ähnlichen Modellen schwer zu überwinden waren.
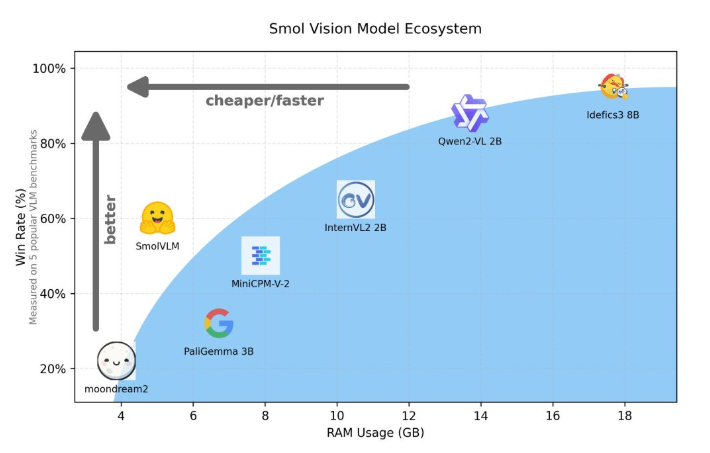
Im Vergleich zu Qwen2-VL2B generiert SmolVLM dank seiner optimierten Architektur, die eine leichte Inferenz ermöglicht, Token 7,5 bis 16 Mal schneller. Diese Effizienz bringt nicht nur praktische Vorteile für Endbenutzer, sondern verbessert auch das Benutzererlebnis erheblich.
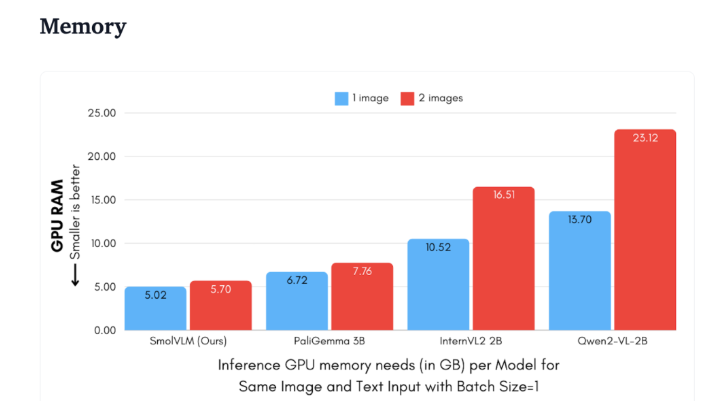
Aus technischer Sicht verfügt SmolVLM über eine optimierte Architektur, die effiziente geräteseitige Inferenz unterstützt. Benutzer können in Google Colab sogar ganz einfach Feinabstimmungen vornehmen, wodurch die Hemmschwelle für Experimente und Entwicklung erheblich gesenkt wird.
Aufgrund seines geringen Speicherbedarfs kann SmolVLM problemlos auf Geräten ausgeführt werden, die bisher nicht in der Lage waren, ähnliche Modelle zu hosten. Beim Testen eines YouTube-Videos mit 50 Bildern schnitt SmolVLM mit 27,14 % gut ab und übertraf die beiden ressourcenintensiveren Modelle hinsichtlich des Ressourcenverbrauchs, was seine starke Anpassungsfähigkeit und Flexibilität unter Beweis stellte.
SmolVLM ist ein wichtiger Meilenstein auf dem Gebiet der visuellen Sprachmodelle. Seine Einführung ermöglicht die Ausführung komplexer visueller Sprachaufgaben auf alltäglichen Geräten und schließt damit eine wichtige Lücke in aktuellen KI-Tools.
SmolVLM zeichnet sich nicht nur durch Geschwindigkeit und Effizienz aus, sondern bietet Entwicklern und Forschern auch ein leistungsstarkes Tool zur Erleichterung der visuellen Sprachverarbeitung ohne teure Hardwarekosten. Da die KI-Technologie immer beliebter wird, werden Modelle wie SmolVLM den Zugang zu leistungsstarken maschinellen Lernfunktionen erleichtern.
Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
Alles in allem hat SmolVLM einen neuen Maßstab für leichte visuelle Sprachmodelle gesetzt. Seine effiziente Leistung und bequeme Nutzung werden die Popularisierung und Entwicklung der KI-Technologie erheblich vorantreiben. Wir freuen uns auf weitere ähnliche Innovationen in der Zukunft, die es der KI-Technologie ermöglichen, mehr Menschen zu nutzen.