In den letzten Jahren blieben die Trainingskosten für große Sprachmodelle hoch, was zu einem wichtigen Faktor geworden ist, der die Entwicklung von KI einschränkt. Die Frage, wie Schulungskosten gesenkt und die Effizienz gesteigert werden können, ist zum Schwerpunkt der Branche geworden. Der Herausgeber von Downcodes präsentiert Ihnen eine Interpretation des neuesten Artikels von Forschern der Harvard University und der Stanford University. Dieser Artikel schlägt eine „genauigkeitsbewusste“ Skalierungsregel vor, die die Trainingskosten effektiv reduziert, indem sie die Genauigkeit des Modelltrainings sogar in einigen Fällen anpasst In diesem Fall kann es auch die Modellleistung verbessern. Werfen wir einen genaueren Blick auf diese spannende Forschung.
Im Bereich der künstlichen Intelligenz scheint ein größerer Maßstab auch größere Fähigkeiten zu bedeuten. Auf der Suche nach leistungsfähigeren Sprachmodellen stapeln große Technologieunternehmen hektisch Modellparameter und Trainingsdaten und stellen dann fest, dass auch die Kosten steigen. Gibt es nicht eine kostengünstige und effiziente Möglichkeit, Sprachmodelle zu trainieren?
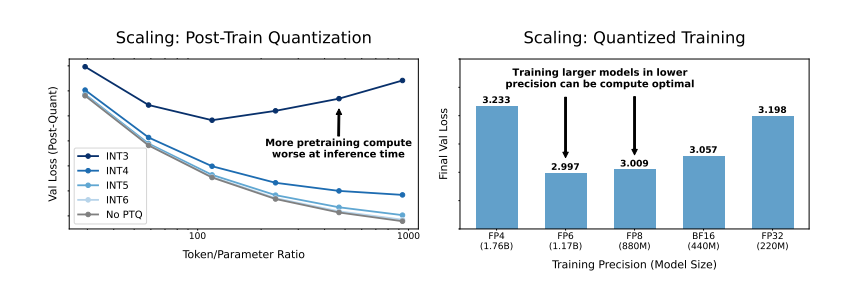
Forscher der Universitäten Harvard und Stanford haben kürzlich einen Artikel veröffentlicht, in dem sie herausfanden, dass die Genauigkeit des Modelltrainings wie ein versteckter Schlüssel ist, der den „Kostencode“ des Sprachmodelltrainings entschlüsseln kann.
Was ist Modellgenauigkeit? Einfach ausgedrückt bezieht sie sich auf die Modellparameter und die Anzahl der im Berechnungsprozess verwendeten Stellen. Herkömmliche Deep-Learning-Modelle verwenden für das Training normalerweise 32-Bit-Gleitkommazahlen (FP32), aber in den letzten Jahren werden mit der Entwicklung der Hardware auch Zahlentypen mit geringerer Präzision verwendet, wie z. B. 16-Bit-Gleitkommazahlen (FP16) oder 8-Bit-Gleitkommazahlen (FP16). Bit-Ganzzahlen (INT8) Training ist bereits möglich.
Welche Auswirkungen wird eine Verringerung der Modellgenauigkeit auf die Modellleistung haben? Genau dieser Frage geht dieser Artikel nach. Durch eine große Anzahl von Experimenten analysierten die Forscher die Kosten- und Leistungsänderungen des Modelltrainings und der Inferenz bei unterschiedlicher Genauigkeit und schlugen einen neuen Satz „genauigkeitsbewusster“ Skalierungsregeln vor.
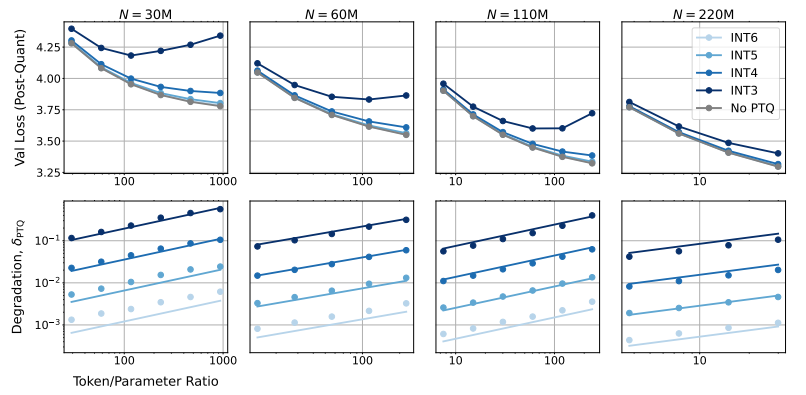
Sie fanden heraus, dass ein Training mit geringerer Präzision die „effektive Anzahl von Parametern“ des Modells effektiv reduziert und dadurch den für das Training erforderlichen Rechenaufwand verringert. Das bedeutet, dass wir mit dem gleichen Rechenbudget größere Modelle trainieren können oder im gleichen Maßstab mit geringerer Genauigkeit viele Rechenressourcen einsparen können.
Noch überraschender ist, dass die Forscher in einigen Fällen sogar die Leistung des Modells durch Training mit geringerer Präzision verbessern können. Wenn das Modell beispielsweise während der Trainingsphase eine „Post-Training-Quantisierung“ erfordert, Das Modell ist robuster gegenüber der Verringerung der Präzision nach der Quantisierung und zeigt somit eine bessere Leistung während der Inferenzphase.
Welche Präzision sollten wir also zum Trainieren des Modells wählen? Durch die Analyse ihrer Skalierungsregeln kamen die Forscher zu einigen interessanten Schlussfolgerungen:
Herkömmliches 16-Bit-Präzisionstraining ist möglicherweise nicht optimal. Ihre Untersuchungen deuten darauf hin, dass eine Genauigkeit von 7–8 Stellen eine kostengünstigere Option sein könnte.
Es ist auch unklug, blind ein Training mit extrem geringer Präzision (z. B. 4 Ziffern) durchzuführen. Denn bei extrem geringer Genauigkeit sinkt die Anzahl der effektiven Parameter des Modells stark. Um die Leistung aufrechtzuerhalten, müssen wir die Modellgröße deutlich erhöhen, was wiederum zu höheren Rechenkosten führt.
Die optimale Trainingsgenauigkeit kann bei Modellen unterschiedlicher Größe variieren. Für Modelle, die viel „Übertraining“ erfordern, wie etwa die Serien Llama-3 und Gemma-2, kann ein Training mit höherer Genauigkeit kosteneffektiver sein.
Diese Forschung bietet eine neue Perspektive zum Verständnis und zur Optimierung des Sprachmodelltrainings. Es zeigt uns, dass die Wahl der Genauigkeit nicht statisch ist, sondern auf der Grundlage der spezifischen Modellgröße, des Trainingsdatenvolumens und der Anwendungsszenarien abgewogen werden muss.
Natürlich unterliegt diese Studie einigen Einschränkungen. Das von ihnen verwendete Modell ist beispielsweise relativ kleinräumig und die experimentellen Ergebnisse sind möglicherweise nicht direkt auf größere Modelle übertragbar. Darüber hinaus konzentrierten sie sich nur auf die Verlustfunktion des Modells und bewerteten nicht die Leistung des Modells bei nachgelagerten Aufgaben.
Dennoch hat diese Forschung immer noch wichtige Implikationen. Es zeigt die komplexe Beziehung zwischen Modellgenauigkeit, Modellleistung und Trainingskosten auf und liefert uns wertvolle Erkenntnisse für die Entwicklung und das Training leistungsfähigerer und wirtschaftlicherer Sprachmodelle in der Zukunft.
Papier: https://arxiv.org/pdf/2411.04330
Alles in allem liefert diese Forschung neue Ideen und Methoden zur Reduzierung der Kosten für das Training umfangreicher Sprachmodelle und liefert wichtige Referenzwerte für die zukünftige KI-Entwicklung. Der Herausgeber von Downcodes freut sich auf weitere Fortschritte in der Modellgenauigkeitsforschung und trägt zum Aufbau kostengünstigerer KI-Modelle bei.