Der Herausgeber von Downcodes erfuhr, dass Ai2, eine gemeinnützige KI-Forschungseinrichtung, kürzlich seine neue OLMo2-Reihe von Sprachmodellen veröffentlicht hat, die die zweite Generation seiner „Open Language Model“ (OLMo)-Reihe darstellt. OLMo2 folgt dem Konzept des vollständig offenen Quellcodes und seine Trainingsdaten, Tools und Codes sind vollständig offen. Dies ist im heutigen KI-Bereich besonders wichtig und stellt einen neuen Höhepunkt in der Entwicklung der Open-Source-KI dar. Im Gegensatz zu anderen Modellen, die behaupten, „offen“ zu sein, folgt OLMo2 strikt der Definition der Open-Source-Initiative, erfüllt die strengen Standards der Open-Source-KI und bietet der KI-Community starken technischen Support und wertvolle Lernressourcen.
Ai2, eine gemeinnützige KI-Forschungsorganisation, hat kürzlich ihre neue OLMo2-Serie veröffentlicht, bei der es sich um das Modell der zweiten Generation der von der Organisation eingeführten „Open Language Model“ (OLMo)-Reihe handelt. Die Veröffentlichung von OLMo2 bietet nicht nur starke technische Unterstützung für die KI-Community, sondern stellt mit seinem vollständig offenen Quellcode auch die neueste Entwicklung der Open-Source-KI dar.
Im Gegensatz zu anderen derzeit auf dem Markt erhältlichen „offenen“ Sprachmodellen wie der Llama-Reihe von Meta erfüllt OLMo2 die strenge Definition der Open Source Initiative, was bedeutet, dass die für seine Entwicklung verwendeten Trainingsdaten, Tools und Codes öffentlich und für jedermann zugänglich sind verwenden. Gemäß der Definition der Open Source Initiative erfüllt OLMo2 die Anforderungen der Organisation an einen „Open Source AI“-Standard, der im Oktober dieses Jahres fertiggestellt wurde.
Ai2 erwähnte in seinem Blog, dass während des Entwicklungsprozesses von OLMo2 alle Trainingsdaten, Codes, Trainingspläne, Bewertungsmethoden und Zwischenkontrollpunkte vollständig offen waren, mit dem Ziel, Innovation und Entdeckung in der Open-Source-Community durch gemeinsame Ressourcen zu fördern. „Durch die offene Weitergabe unserer Daten, Lösungen und Erkenntnisse hoffen wir, der Open-Source-Community die Ressourcen zur Verfügung zu stellen, um neue Methoden und innovative Technologien zu entdecken.“
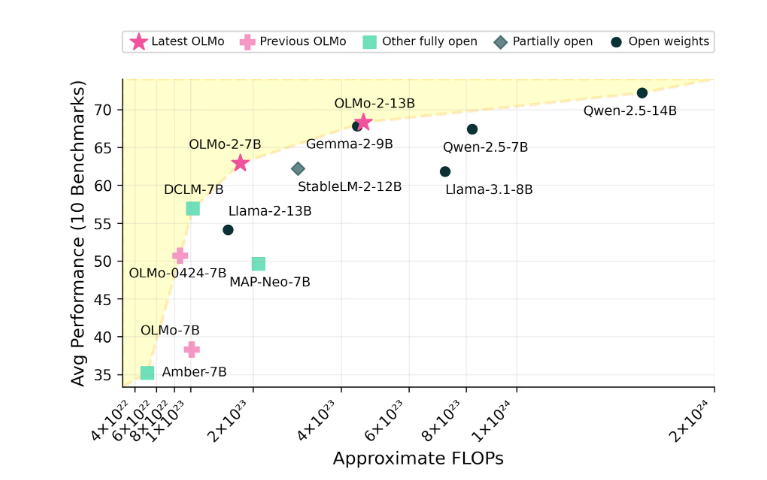
Die OLMo2-Serie umfasst zwei Versionen: eine ist OLMo7B mit 7 Milliarden Parametern und die andere ist OLMo13B mit 13 Milliarden Parametern. Die Anzahl der Parameter wirkt sich direkt auf die Leistung des Modells aus, und Versionen mit mehr Parametern können in der Regel komplexere Aufgaben bewältigen. OLMo2 schnitt bei allgemeinen Textaufgaben gut ab und konnte Aufgaben wie das Beantworten von Fragen, das Zusammenfassen von Dokumenten und das Schreiben von Code erledigen.

Hinweis zur Bildquelle: Das Bild wird von KI generiert und vom Dienstanbieter Midjourney autorisiert
Um OLMo2 zu trainieren, verwendete Ai2 einen Datensatz mit fünf Billionen Token. Token ist die kleinste Einheit im Sprachmodell. 1 Million Token entsprechen ungefähr 750.000 Wörtern. Die Trainingsdaten umfassen Inhalte von hochwertigen Websites, wissenschaftlichen Arbeiten, Frage-und-Antwort-Diskussionsforen und Arbeitsbüchern zur synthetischen Mathematik und werden sorgfältig ausgewählt, um die Effizienz und Genauigkeit des Modells sicherzustellen.
Ai2 ist von der Leistung von OLMo2 überzeugt und behauptet, dass es hinsichtlich der Leistung mit Open-Source-Modellen wie Metas Llama3.1 konkurriert. Ai2 wies darauf hin, dass die Leistung von OLMo27B sogar Llama3.18B übertraf und zu einem der derzeit stärksten vollständig offenen Sprachmodelle wurde. Alle OLMo2-Modelle und ihre Komponenten können kostenlos über die offizielle Ai2-Website heruntergeladen werden und folgen der Apache2.0-Lizenz, was bedeutet, dass diese Modelle nicht nur für Forschungszwecke, sondern auch für kommerzielle Anwendungen verwendet werden können.
Der Open-Source-Charakter von OLMo2 wird die offene Zusammenarbeit und Innovation im Bereich der KI erheblich fördern und Forschern und Entwicklern einen größeren Raum für Entwicklung bieten. Wir freuen uns darauf, dass OLMo2 in Zukunft weitere Durchbrüche und Anwendungen bringen wird.