Downcodes-Redakteur berichtet: In den letzten Jahren hat sich die audiogesteuerte Bildanimationstechnologie rasant weiterentwickelt, bestehende Modelle weisen jedoch immer noch Engpässe hinsichtlich Effizienz und Dauer auf. Um dieses Problem zu lösen, haben Forscher eine neue Technologie namens JoyVASA entwickelt, die durch ein ausgeklügeltes zweistufiges Design die Qualität und Effizienz audiogesteuerter Bildanimationen deutlich verbessert. JoyVASA ist nicht nur in der Lage, längere animierte Videos zu erstellen, sondern unterstützt auch Tiergesichtsanimationen und weist eine gute Mehrsprachenkompatibilität auf, was neue Möglichkeiten für den Bereich der Animationsproduktion eröffnet.
Kürzlich haben Forscher eine neue Technologie namens JoyVASA vorgeschlagen, die darauf abzielt, audiogesteuerte Bildanimationseffekte zu verbessern. Durch die kontinuierliche Weiterentwicklung von Deep-Learning- und Diffusionsmodellen hat die audiogesteuerte Porträtanimation erhebliche Fortschritte bei der Videoqualität und der Genauigkeit der Lippensynchronisation gemacht. Allerdings erhöht die Komplexität vorhandener Modelle die Effizienz von Training und Inferenz, begrenzt aber auch die Dauer und die Kontinuität zwischen Bildern von Videos.
JoyVASA verwendet ein zweistufiges Design. Die erste Stufe führt ein entkoppeltes Gesichtsdarstellungsgerüst ein, um dynamische Gesichtsausdrücke von statischen dreidimensionalen Gesichtsdarstellungen zu trennen.
Durch diese Trennung kann das System jedes statische 3D-Gesichtsmodell mit dynamischen Aktionssequenzen kombinieren, um längere animierte Videos zu erstellen. In der zweiten Phase trainierte das Forschungsteam einen Diffusionstransformator, der Aktionssequenzen direkt aus Audio-Hinweisen generieren kann, ein Prozess, der unabhängig von der Charakteridentität ist. Schließlich verwendet der auf dem Training der ersten Stufe basierende Generator die 3D-Gesichtsdarstellung und die generierte Aktionssequenz als Eingabe, um hochwertige Animationseffekte zu rendern.
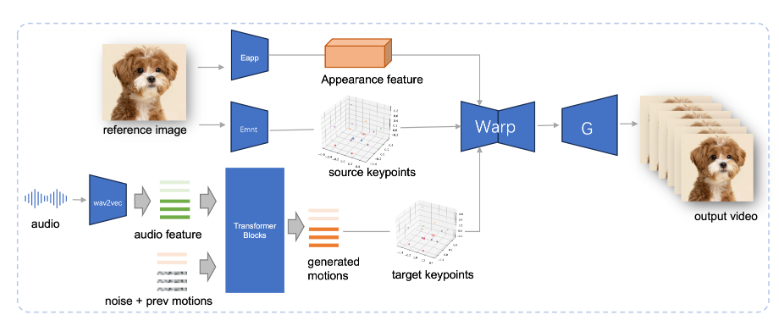
Insbesondere ist JoyVASA nicht auf die Animation menschlicher Porträts beschränkt, sondern kann auch Tiergesichter nahtlos animieren. Dieses Modell wird anhand eines gemischten Datensatzes trainiert, der private chinesische Daten und öffentliche englische Daten kombiniert und gute Funktionen zur Unterstützung mehrerer Sprachen aufweist. Die experimentellen Ergebnisse belegen die Wirksamkeit dieser Methode. Zukünftige Forschung wird sich auf die Verbesserung der Echtzeitleistung und die Verfeinerung der Ausdruckskontrolle konzentrieren, um die Anwendung dieses Frameworks in der Bildanimation weiter zu erweitern.
Die Entstehung von JoyVASA markiert einen wichtigen Durchbruch in der audiogesteuerten Animationstechnologie und eröffnet neue Möglichkeiten im Bereich Animation.
Projekteingang: https://jdh-algo.github.io/JoyVASA/
Die Innovation der JoyVASA-Technologie liegt in ihrem effizienten zweistufigen Design und den leistungsstarken Funktionen zur Unterstützung mehrerer Sprachen, die eine bequemere und effizientere Lösung für die Animationsproduktion bieten. Mit der weiteren Verbesserung der Technologie wird erwartet, dass JoyVASA in Zukunft in mehr Bereichen weit verbreitet sein wird und uns realistischere und aufregendere Animationsarbeiten bescheren wird. Wir freuen uns auf weitere technologische Durchbrüche und darauf, ein neues Kapitel in der Entwicklung der Animationsbranche aufzuschlagen!