Die rasante Entwicklung großer Sprachmodelle (LLM) ist beeindruckend, aber die bloße Erweiterung des Modellmaßstabs reicht nicht aus, um echte KI-Intelligenz zu erreichen. Der Herausgeber von Downcodes glaubt, dass es für die zukünftige Entwicklung der KI von entscheidender Bedeutung ist, dem Modell die Fähigkeit zu geben, sich selbst weiterzuentwickeln, damit es während der Inferenzphase weiter lernen und sich verbessern kann. In diesem Artikel wird der Schlüsselfaktor für die Selbstentwicklung der KI untersucht – das Langzeitgedächtnis (LTM) – und wie durch LTM kontinuierliche Fortschritte in der KI erzielt werden können.
Große Sprachmodelle (LLM), wie die GPT-Reihe, haben mit ihren riesigen Datensätzen erstaunliche Fähigkeiten im Sprachverständnis, Argumentation und Planung gezeigt und bei verschiedenen anspruchsvollen Aufgaben ein Niveau erreicht, das mit dem Menschen vergleichbar ist. Die meisten Forschungsarbeiten haben sich auf die weitere Verbesserung dieser Modelle konzentriert, indem sie auf größeren Datensätzen trainiert wurden, mit dem Ziel, leistungsfähigere Basismodelle zu entwickeln.
Obwohl das Training eines leistungsfähigeren Basismodells von entscheidender Bedeutung ist, glauben Forscher, dass es auch für die Entwicklung der KI von entscheidender Bedeutung ist, dem Modell die Fähigkeit zu geben, sich während der Inferenzphase, also der Selbstentwicklung der KI, weiterzuentwickeln. Im Vergleich zur Verwendung großer Datenmengen zum Trainieren eines Modells sind für die Selbstentwicklung möglicherweise nur begrenzte Daten oder Interaktionen erforderlich.
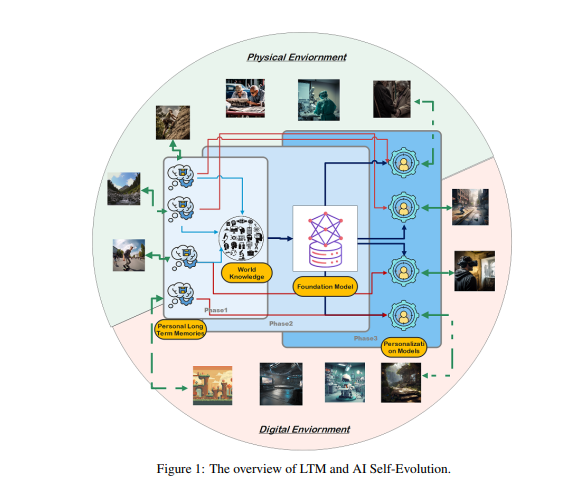
Inspiriert durch die Säulenstruktur der menschlichen Großhirnrinde stellten die Forscher die Hypothese auf, dass KI-Modelle durch iterative Interaktionen mit ihrer Umgebung neue kognitive Fähigkeiten entwickeln und interne Repräsentationsmodelle aufbauen können.
Um dieses Ziel zu erreichen, schlugen die Forscher vor, dass das Modell über ein Langzeitgedächtnis (LTM) zum Speichern und Verwalten verarbeiteter Interaktionsdaten aus der realen Welt verfügen muss. LTM ist nicht nur in der Lage, individuelle Long-Tail-Daten in statistischen Modellen darzustellen, sondern fördert auch die Selbstentwicklung, indem es vielfältige Erfahrungen in verschiedenen Umgebungen und Agenten unterstützt.
LTM ist der Schlüssel zur Verwirklichung der Selbstentwicklung der KI. Ähnlich wie Menschen durch persönliche Erfahrung und Interaktion mit der Umwelt kontinuierlich lernen und sich verbessern, basiert auch die Selbstentwicklung von KI-Modellen auf LTM-Daten, die während Interaktionen gesammelt werden. Im Gegensatz zur menschlichen Evolution ist die LTM-gesteuerte Modellentwicklung nicht auf Interaktionen in der realen Welt beschränkt. Modelle können wie Menschen mit der physischen Umgebung interagieren und direktes Feedback erhalten, das zur Verbesserung ihrer Fähigkeiten verarbeitet wird. Dies ist auch ein zentrales Forschungsgebiet der verkörperten KI.
Andererseits können Modelle auch in virtuellen Umgebungen interagieren und LTM-Daten sammeln, was kostengünstiger und effizienter ist als die Interaktion in der realen Welt und dadurch die Fähigkeiten effektiver verbessert.
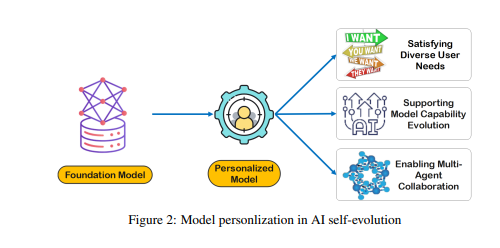
Der Aufbau von LTM erfordert die Verfeinerung und Strukturierung von Rohdaten. Unter Rohdaten versteht man die Sammlung aller unverarbeiteten Daten, die das Modell durch Interaktion mit der externen Umgebung oder während des Trainingsprozesses erhält. Diese Daten enthalten eine Vielzahl von Beobachtungen und Aufzeichnungen, die wertvolle Muster und große Mengen redundanter oder irrelevanter Informationen enthalten können.
Während Rohdaten die Grundlage des Modellgedächtnisses und der Modellerkennung bilden, müssen sie weiterverarbeitet werden, bevor sie effektiv zur Personalisierung oder effizienten Aufgabenausführung verwendet werden können. LTM verfeinert und strukturiert diese Rohdaten, damit das Modell sie nutzen kann. Dieser Prozess verbessert die Fähigkeit des Modells, personalisierte Antworten und Empfehlungen bereitzustellen.
Der Aufbau von LTM steht vor Herausforderungen wie Datenknappheit und Benutzervielfalt. In kontinuierlich aktualisierten LTM-Systemen ist die Datenknappheit ein häufiges Problem, insbesondere für Benutzer mit begrenztem Interaktionsverlauf oder verstreuten Aktivitäten, was das Modelltraining erschwert. Darüber hinaus erhöht die Benutzervielfalt auch die Komplexität und erfordert, dass sich Modelle sowohl an individuelle Muster anpassen als auch effektiv über verschiedene Benutzergruppen hinweg verallgemeinern.
Die Forscher entwickelten ein Multi-Agenten-Kollaborations-Framework namens Omne, das die KI-Selbstentwicklung auf Basis von LTM implementiert. In diesem Rahmen verfügt jeder Agent über eine unabhängige Systemstruktur und kann autonom ein vollständiges Umgebungsmodell erlernen und speichern, um ein unabhängiges Verständnis der Umgebung aufzubauen. Durch diese kollaborative Entwicklung auf Basis von LTM kann sich das KI-System in Echtzeit an Veränderungen im individuellen Verhalten anpassen, die Aufgabenplanung und -ausführung optimieren und die personalisierte und effiziente KI-Selbstentwicklung weiter fördern.
Das Omne-Framework erreichte im GAIA-Benchmark-Test den ersten Platz und bewies damit das enorme Potenzial der Nutzung von LTM für die Selbstentwicklung von KI und die Lösung realer Probleme. Die Forscher glauben, dass die Weiterentwicklung der LTM-Forschung von entscheidender Bedeutung für die weitere Entwicklung und praktische Anwendung der KI-Technologie ist, insbesondere im Hinblick auf die Selbstentwicklung.
Alles in allem ist das Langzeitgedächtnis der Schlüssel zur Selbstentwicklung der KI und ermöglicht es KI-Modellen, genau wie Menschen aus Erfahrungen zu lernen und sich zu verbessern. Der Aufbau und die Nutzung von LTM erfordert die Bewältigung von Herausforderungen wie Datenknappheit und Benutzervielfalt. Das Omne-Framework bietet eine praktikable Lösung für die LTM-basierte KI-Selbstentwicklung, und sein Erfolg im GAIA-Benchmark-Test zeigt das enorme Potenzial in diesem Bereich.
Papier: https://arxiv.org/pdf/2410.15665
Durch die Erforschung des Langzeitgedächtnisses (LTM) ist die Selbstentwicklung der KI kein ferner Traum mehr. Es wird erwartet, dass LTM-basierte KI-Modelle in Zukunft leistungsfähigere Fähigkeiten in einem breiteren Spektrum von Bereichen demonstrieren und der menschlichen Gesellschaft größere Vorteile bringen. Wir freuen uns auf weitere innovative Ergebnisse!