Das KI-Forschungsteam von Apple hat eine neue Generation der multimodalen großen Sprachmodellfamilie MM1.5 veröffentlicht, die mehrere Datentypen wie Text und Bilder integrieren kann und eine leistungsstarke Leistung bei Aufgaben wie der visuellen Beantwortung von Fragen, der Bildgenerierung und Multi- Fähigkeit zur modalen Dateninterpretation. MM1.5 überwindet die Schwierigkeiten früherer multimodaler Modelle bei der Verarbeitung von textreichen Bildern und feinkörnigen visuellen Aufgaben. Durch einen innovativen datenzentrierten Ansatz werden hochauflösende OCR-Daten und synthetische Bildbeschreibungen verwendet, um die Leistung des Modells erheblich zu verbessern . Verständnis. Der Herausgeber von Downcodes vermittelt Ihnen einen detaillierten Einblick in die Innovationen von MM1.5 und seine hervorragende Leistung in mehreren Benchmark-Tests.
Kürzlich hat das KI-Forschungsteam von Apple seine neue Generation der Familie multimodaler großer Sprachmodelle (MLLMs) auf den Markt gebracht – MM1.5. Diese Modellreihe kann mehrere Datentypen wie Text und Bilder kombinieren und zeigt uns die neue Fähigkeit der KI, komplexe Aufgaben zu verstehen. Aufgaben wie visuelle Beantwortung von Fragen, Bildgenerierung und multimodale Dateninterpretation können mit Hilfe dieser Modelle besser gelöst werden.
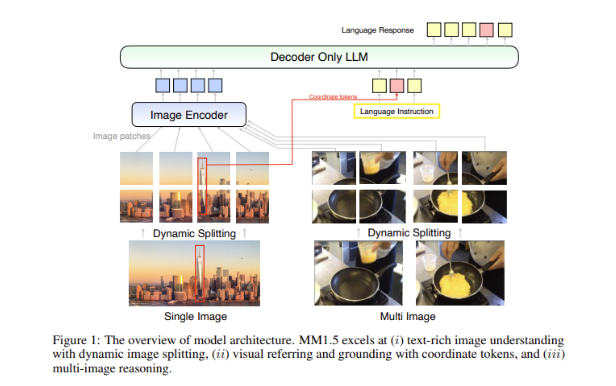
Eine große Herausforderung bei multimodalen Modellen besteht darin, eine effektive Interaktion zwischen verschiedenen Datentypen zu erreichen. Frühere Modelle hatten oft Probleme mit Bildern mit vielen Texten oder feinkörnigen Sehaufgaben. Daher führte das Forschungsteam von Apple eine innovative datenzentrierte Methode in das MM1.5-Modell ein, die hochauflösende OCR-Daten und synthetische Bildbeschreibungen nutzt, um die Verständnisfähigkeiten des Modells zu stärken.
Diese Methode ermöglicht es MM1.5 nicht nur, frühere Modelle bei visuellen Verständnis- und Positionierungsaufgaben zu übertreffen, sondern bringt auch zwei spezielle Versionen des Modells auf den Markt: MM1.5-Video und MM1.5-UI, die jeweils für das Videoverständnis und die Positionierung verwendet werden . Mobile Schnittstellenanalyse.
Das Training des MM1.5-Modells ist in drei Hauptphasen unterteilt.
Die erste Stufe ist ein groß angelegtes Vortraining, bei dem 2 Milliarden Paare von Bild- und Textdaten, 600 Millionen verschachtelte Bild-Text-Dokumente und 2 Billionen Nur-Text-Tokens verwendet werden.
Die zweite Stufe besteht darin, die Leistung textangereicherter Bildaufgaben durch kontinuierliches Vortraining von 45 Millionen hochwertigen OCR-Daten und 7 Millionen synthetischen Beschreibungen weiter zu verbessern.
Schließlich wird das Modell in der überwachten Feinabstimmungsphase mithilfe sorgfältig ausgewählter Einzelbild-, Mehrbild- und Nur-Text-Daten optimiert, um eine bessere detaillierte visuelle Referenz und Mehrbildbegründung zu ermöglichen.
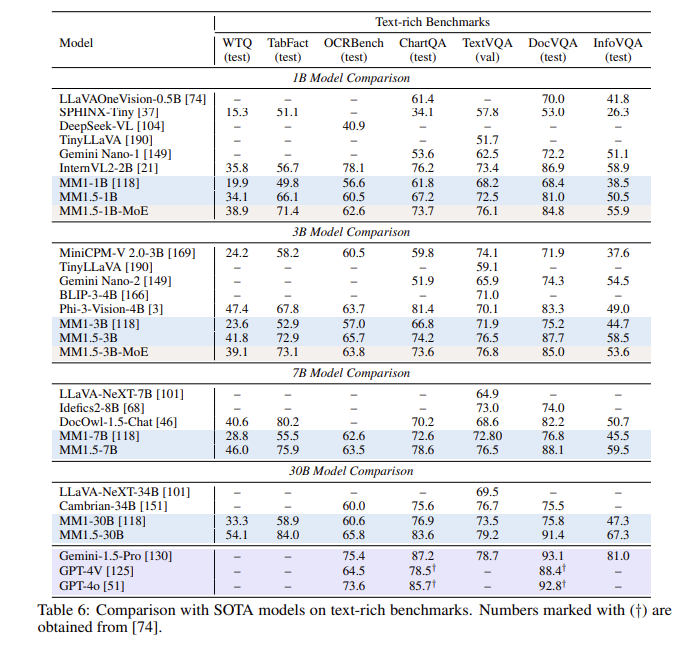
Nach einer Reihe von Evaluierungen schnitt das MM1.5-Modell in mehreren Benchmark-Tests gut ab, insbesondere beim Verständnis von textreichen Bildern, mit einer Verbesserung um 1,4 Punkte gegenüber dem Vorgängermodell. Darüber hinaus hat sogar MM1.5-Video, das speziell für das Videoverstehen entwickelt wurde, mit seinen leistungsstarken multimodalen Fähigkeiten das Spitzenniveau bei verwandten Aufgaben erreicht.
Die MM1.5-Modellfamilie setzt nicht nur neue Maßstäbe für multimodale große Sprachmodelle, sondern demonstriert auch ihr Potenzial in einer Vielzahl von Anwendungen, vom allgemeinen Bildtextverständnis bis hin zur Video- und Benutzeroberflächenanalyse, alle mit herausragender Leistung.
Highlight:
**Modellvarianten**: Umfasst dichte Modelle und MoE-Modelle mit Parametern von 1 Milliarde bis 30 Milliarden und gewährleistet so Skalierbarkeit und flexible Bereitstellung.
? **Trainingsdaten**: Verwendung von 2 Milliarden Bild-Text-Paaren, 600 Millionen verschachtelten Bild-Text-Dokumenten und 2 Billionen Nur-Text-Tokens.
**Leistungsverbesserung**: In einem Benchmark-Test, der sich auf das Verständnis textreicher Bilder konzentrierte, wurde eine Verbesserung um 1,4 Punkte im Vergleich zum Vorgängermodell erzielt.
Alles in allem hat die MM1.5-Modellfamilie von Apple erhebliche Fortschritte im Bereich multimodaler großer Sprachmodelle gemacht und ihre innovativen Methoden und hervorragenden Leistungen geben eine neue Richtung für die zukünftige KI-Entwicklung vor. Wir freuen uns darauf, dass MM1.5 sein Potenzial in weiteren Anwendungsszenarien zeigt.