In den letzten Jahren haben das Transformer-Modell und sein Aufmerksamkeitsmechanismus im Bereich der großen Sprachmodelle (LLM) erhebliche Fortschritte gemacht, das Problem der Anfälligkeit für Störungen durch irrelevante Informationen bestand jedoch schon immer. Der Herausgeber von Downcodes wird für Sie ein aktuelles Papier interpretieren, in dem ein neues Modell namens Differential Transformer (DIFF Transformer) vorgeschlagen wird, das darauf abzielt, das Problem des Aufmerksamkeitsrauschens im Transformer-Modell zu lösen und die Effizienz und Genauigkeit des Modells zu verbessern. Das Modell filtert effektiv irrelevante Informationen durch einen innovativen differenziellen Aufmerksamkeitsmechanismus heraus, wodurch sich das Modell stärker auf Schlüsselinformationen konzentrieren kann, wodurch erhebliche Verbesserungen in mehreren Aspekten erzielt werden, einschließlich Sprachmodellierung, Langtextverarbeitung, Schlüsselinformationsabruf und Reduzierung der Modellillusion usw .
Große Sprachmodelle (LLM) haben sich in letzter Zeit rasant entwickelt, wobei das Transformer-Modell eine wichtige Rolle spielt. Der Kern von Transformer ist der Aufmerksamkeitsmechanismus, der wie ein Informationsfilter wirkt und es dem Modell ermöglicht, sich auf die wichtigsten Teile des Satzes zu konzentrieren. Aber selbst ein leistungsstarker Transformer wird durch irrelevante Informationen gestört, so wie Sie versuchen, ein Buch in der Bibliothek zu finden, aber von einem Stapel irrelevanter Bücher überwältigt werden, und die Effizienz ist natürlich gering.
Die durch diesen Aufmerksamkeitsmechanismus erzeugten irrelevanten Informationen werden in der Arbeit als Aufmerksamkeitsrauschen bezeichnet. Stellen Sie sich vor, Sie möchten eine wichtige Information in einer Datei finden, aber die Aufmerksamkeit des Transformer-Modells ist auf verschiedene irrelevante Stellen gestreut, genau wie eine kurzsichtige Person, die die wichtigsten Punkte nicht erkennen kann.
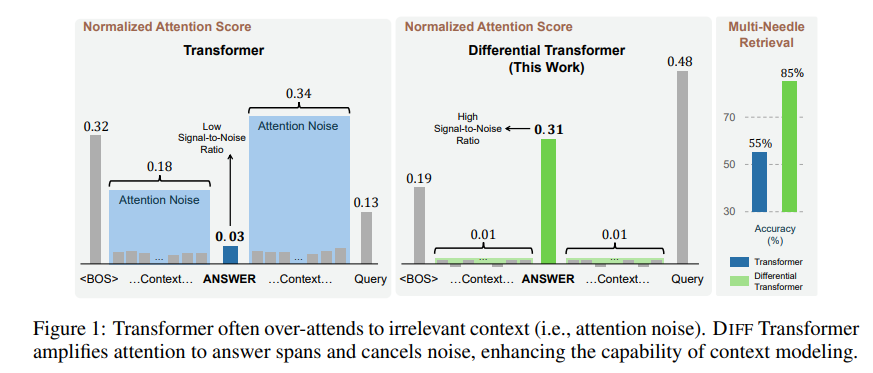
Um dieses Problem zu lösen, schlägt dieser Artikel einen Differentialtransformator (DIFF-Transformator) vor. Der Name ist sehr fortschrittlich, aber das Prinzip ist eigentlich sehr einfach. Genau wie bei Noise-Cancelling-Kopfhörern werden Geräusche durch die Differenz zwischen zwei Signalen eliminiert.
Der Kern von Differential Transformer ist der Mechanismus der differenziellen Aufmerksamkeit. Es unterteilt die Abfrage- und Schlüsselvektoren in zwei Gruppen, berechnet jeweils zwei Aufmerksamkeitskarten und subtrahiert diese beiden Karten dann, um den endgültigen Aufmerksamkeitswert zu erhalten. Dieser Vorgang ähnelt der Aufnahme desselben Objekts mit zwei Kameras und der anschließenden Überlagerung der beiden Fotos, wodurch die Unterschiede hervorgehoben werden.
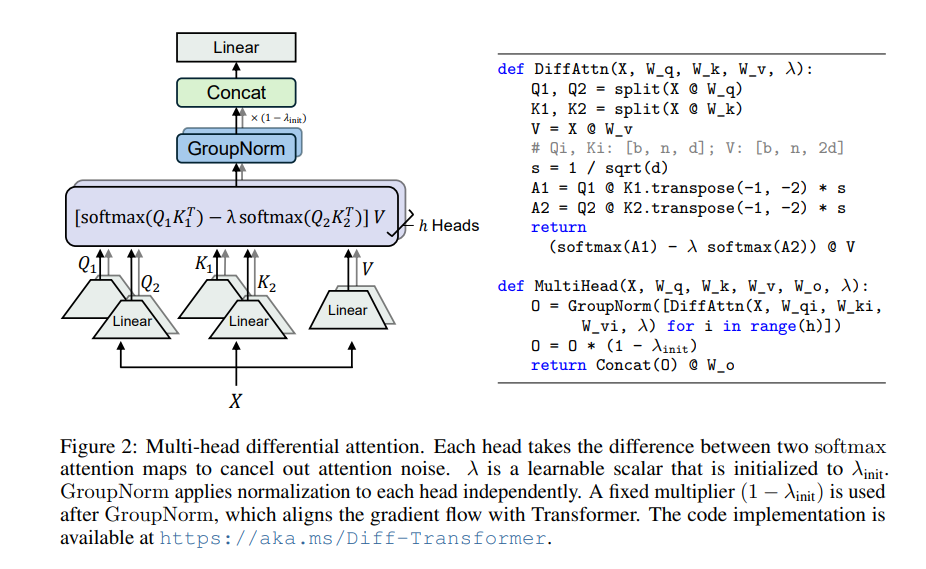
Auf diese Weise kann Differential Transformer das Aufmerksamkeitsrauschen effektiv eliminieren und es dem Modell ermöglichen, sich stärker auf wichtige Informationen zu konzentrieren. Genau wie beim Aufsetzen von Kopfhörern mit Geräuschunterdrückung verschwinden die Umgebungsgeräusche und Sie können den gewünschten Klang klarer hören.
In der Arbeit wurde eine Reihe von Experimenten durchgeführt, um die Überlegenheit des Differentialtransformators zu beweisen. Erstens schneidet es bei der Sprachmodellierung gut ab und erfordert nur 65 % der Modellgröße oder Trainingsdaten von Transformer, um ähnliche Ergebnisse zu erzielen.
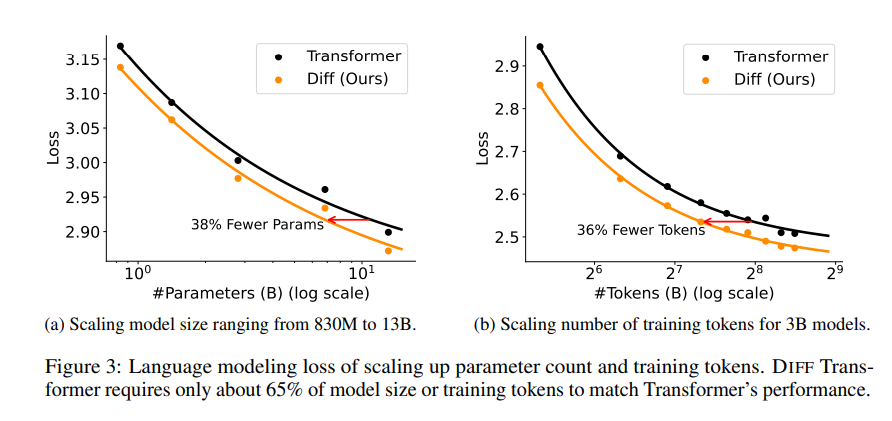
Zweitens eignet sich Differential Transformer auch besser für die Modellierung langer Texte und kann längere Kontextinformationen effektiv nutzen.
Noch wichtiger ist, dass Differential Transformer erhebliche Vorteile beim Abrufen wichtiger Informationen, bei der Reduzierung von Modellillusionen und beim Kontextlernen aufweist.
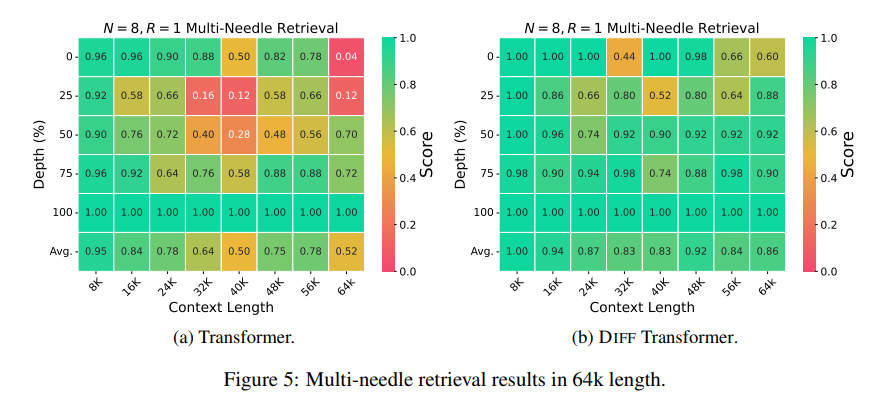
Im Hinblick auf das Abrufen wichtiger Informationen ist Differential Transformer wie eine präzise Suchmaschine, die in riesigen Informationsmengen genau das findet, was Sie suchen. Sie kann auch in Szenarien mit äußerst komplexen Informationen eine hohe Genauigkeit beibehalten.
Im Hinblick auf die Reduzierung von Modellhalluzinationen kann Differential Transformer Modell-„Unsinn“ effektiv vermeiden und genauere und zuverlässigere Textzusammenfassungen sowie Frage- und Antwortergebnisse generieren.
In Bezug auf das Kontextlernen ist Differential Transformer eher ein Meister des Lernens, der aus einer kleinen Anzahl von Beispielen schnell neues Wissen lernen kann, und der Lerneffekt ist stabiler, im Gegensatz zu Transformer, das nicht so leicht durch die Reihenfolge der Beispiele beeinflusst wird .
Darüber hinaus kann Differential Transformer auch Ausreißer in Modellaktivierungswerten effektiv reduzieren, was bedeutet, dass es die Modellquantisierung benutzerfreundlicher macht und eine Quantisierung mit niedrigeren Bits erreichen kann, wodurch die Effizienz des Modells verbessert wird.
Alles in allem löst Differential Transformer das Aufmerksamkeitsrauschproblem des Transformer-Modells durch den Differential-Aufmerksamkeitsmechanismus effektiv und erzielt in mehreren Aspekten erhebliche Verbesserungen. Es liefert neue Ideen für die Entwicklung großer Sprachmodelle und wird in Zukunft in weiteren Bereichen eine wichtige Rolle spielen.
Papieradresse: https://arxiv.org/pdf/2410.05258
Alles in allem bietet Differential Transformer eine effektive Methode zur Lösung des Aufmerksamkeitsrauschproblems des Transformer-Modells. Seine hervorragende Leistung in mehreren Bereichen zeigt seine wichtige Position bei der Entwicklung großer Sprachmodelle in der Zukunft. Der Herausgeber von Downcodes empfiehlt den Lesern, den gesamten Artikel zu lesen, um ein tiefgreifendes Verständnis der technischen Details und Anwendungsaussichten zu erlangen. Wir freuen uns darauf, dass Differential Transformer weitere Durchbrüche auf dem Gebiet der künstlichen Intelligenz bringt!