Apple hat ein großes Upgrade seines multimodalen künstlichen Intelligenzmodells MM1 – MM1.5 veröffentlicht. Bei diesem Upgrade handelt es sich nicht um eine einfache Versionsiteration, sondern um eine umfassende Verbesserung der Fähigkeiten des Modells, wodurch seine Leistung beim Bildverständnis, der Texterkennung und der visuellen Befehlsausführung erheblich verbessert wird. Der Herausgeber von Downcodes wird die Verbesserungen von MM1.5 und seine Bedeutung im Bereich der multimodalen künstlichen Intelligenz ausführlich erläutern.
Apple hat kürzlich ein umfangreiches Update seines multimodalen künstlichen Intelligenzmodells MM1 veröffentlicht und es auf die Version MM1.5 aktualisiert. Bei diesem Upgrade handelt es sich nicht nur um eine einfache Änderung der Versionsnummer, sondern um eine umfassende Funktionsverbesserung, die es dem Modell ermöglicht, in verschiedenen Bereichen eine stärkere Leistung zu erzielen.
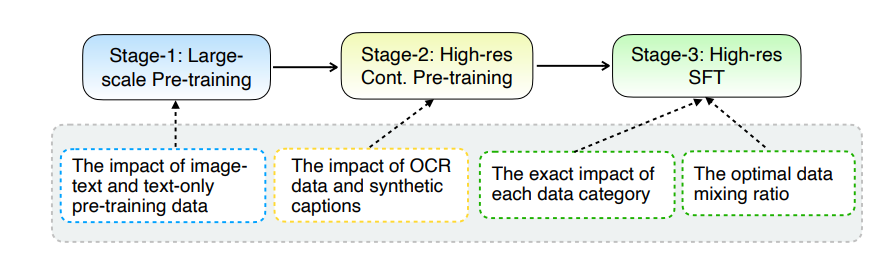
Das Kern-Upgrade von MM1.5 liegt in seiner innovativen Datenverarbeitungsmethode. Das Modell verfolgt einen datenzentrierten Trainingsansatz und der Trainingsdatensatz wird sorgfältig überprüft und optimiert. Konkret nutzt MM1.5 hochauflösende OCR-Daten und synthetische Bildbeschreibungen sowie optimierte visuelle Anweisungen zur Feinabstimmung des Datenmixes. Die Einführung dieser Daten hat die Leistung des Modells bei der Texterkennung, dem Bildverständnis und der Ausführung visueller Anweisungen erheblich verbessert.

In Bezug auf die Modellgröße deckt MM1.5 mehrere Versionen von 1 Milliarde bis 30 Milliarden Parametern ab, einschließlich Intensiv- und Mix-of-Experts-Varianten (MoE). Es ist erwähnenswert, dass selbst kleinere Modelle mit 1 Milliarde und 3 Milliarden Parametern mit sorgfältig entworfenen Daten und Trainingsstrategien beeindruckende Leistungsniveaus erreichen können.
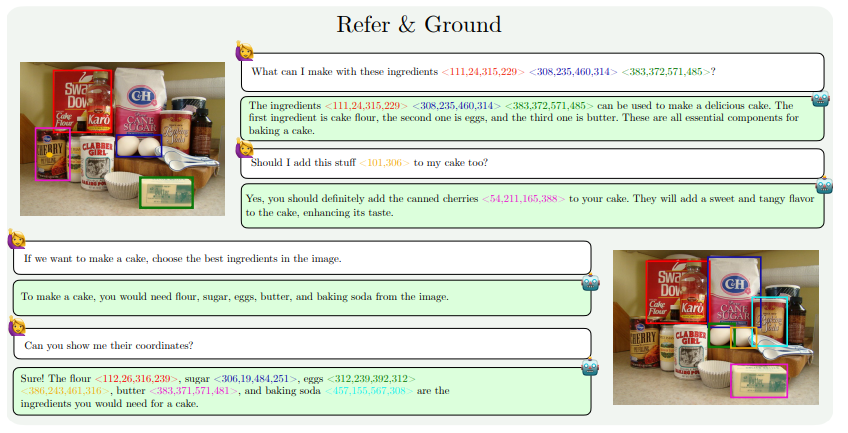
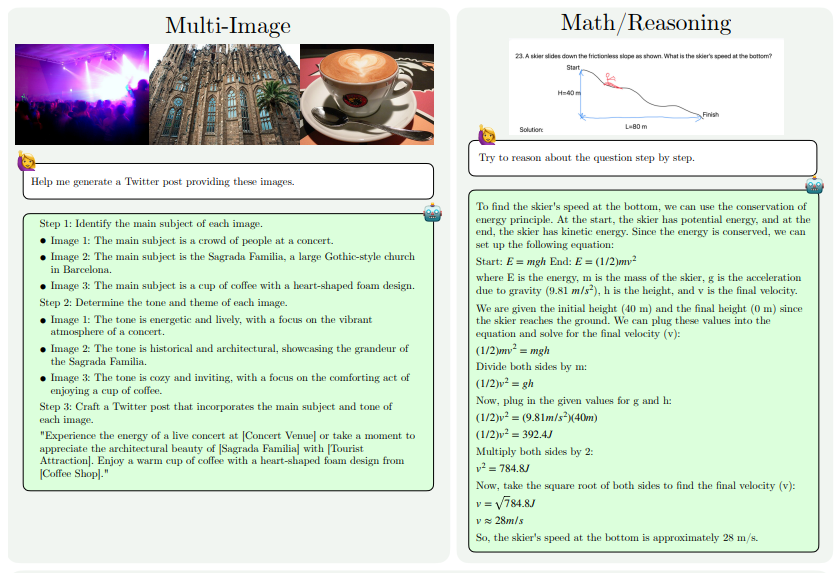
Die Leistungsverbesserungen von MM1.5 spiegeln sich hauptsächlich in den folgenden Aspekten wider: textintensives Bildverständnis, visuelle Referenz und Positionierung, Multi-Image-Argumentation, Videoverständnis und Verständnis der mobilen Benutzeroberfläche. Diese Funktionen ermöglichen die Anwendung von MM1.5 auf ein breiteres Spektrum von Szenarien, z. B. die Identifizierung von Künstlern und Instrumenten anhand von Konzertfotos, das Verstehen von Diagrammdaten und die Beantwortung damit verbundener Fragen, das Auffinden bestimmter Objekte in komplexen Szenen usw.
Um die Leistung von MM1.5 zu bewerten, verglichen die Forscher es mit anderen fortschrittlichen multimodalen Modellen. Die Ergebnisse zeigen, dass MM1.5-1B in einem Modell mit einer Skala von 1 Milliarde Parametern eine gute Leistung erbringt, deutlich besser als andere Modelle auf demselben Niveau. MM1.5-3B übertrifft MiniCPM-V2.0 und liegt auf Augenhöhe mit InternVL2 und Phi-3-Vision. Darüber hinaus ergab die Studie, dass sich die Leistung mit zunehmendem Maßstab erheblich verbessert, unabhängig davon, ob es sich um ein dichtes Modell oder ein MoE-Modell handelt.
Der Erfolg von MM1.5 spiegelt nicht nur Apples Forschungs- und Entwicklungsstärke im Bereich der künstlichen Intelligenz wider, sondern weist auch den Weg für die zukünftige Entwicklung multimodaler Modelle. Durch die Optimierung von Datenverarbeitungsmethoden und Modellarchitektur können auch kleinere Modelle eine starke Leistung erzielen, was für den Einsatz leistungsstarker KI-Modelle auf ressourcenbeschränkten Geräten von großer Bedeutung ist.
Papieradresse: https://arxiv.org/pdf/2409.20566
Alles in allem stellt die Veröffentlichung von MM1.5 einen bedeutenden Fortschritt in der multimodalen Technologie der künstlichen Intelligenz dar. Seine Innovationen in der Datenverarbeitung und Modellarchitektur liefern neue Ideen und Richtungen für die Entwicklung zukünftiger KI-Modelle. Wir freuen uns darauf, dass Apple weiterhin weitere bahnbrechende Ergebnisse im Bereich der künstlichen Intelligenz liefert.