Der Herausgeber von Downcodes wird Sie über einen großen Durchbruch auf dem Gebiet der OCR-Technologie informieren! Forscher haben kürzlich ein OCR-Modell namens GOT (General OCR Theory) entwickelt, das als „OCR2.0“ bekannt ist. Es kombiniert auf clevere Weise die Vorteile traditioneller OCR-Systeme und großer Sprachmodelle und hat erhebliche Fortschritte bei der Texterkennung erzielt . Das GOT-Modell verfügt über eine ausgefeilte Architektur, einen leistungsstarken Bild-Encoder und -Decoder und kann mehrere Arten visueller Informationen verarbeiten. Seine Anwendungsaussichten sind äußerst breit.
Kürzlich haben Forscher ein neues universelles OCR-Modell (Optical Character Recognition) namens GOT (General OCR Theory) entwickelt. In ihrer Arbeit wurde erstmals das Konzept von „OCR2.0“ vorgeschlagen. Dieses neue Modell zielt darauf ab, die Vorteile traditioneller OCR-Systeme mit der Leistungsfähigkeit großer Sprachmodelle zu kombinieren.
Die Architektur von GOT ist recht fortschrittlich und umfasst einen Bildcodierer mit etwa 80 Millionen Parametern und einen Decoder mit 5 Millionen Parametern. Der Bildencoder komprimiert Bilder mit 1024 x 1024 Pixeln in Token, und der Decoder ist für die Umwandlung dieser Token in Text mit bis zu 8000 Zeichen verantwortlich. Auf diese Weise kann das OCR2.0-Modell mehr als nur einfachen Text verarbeiten.
Das Schöne an dieser neuen Technologie liegt in ihrer Fähigkeit, viele Arten visueller Informationen zu erkennen und umzuwandeln , darunter Szenentexte und Dokumenttexte in Englisch und Chinesisch, mathematische und chemische Formeln, Musiksymbole, einfache geometrische Figuren und Diagramme mit Komponenten . Eine solche Funktionalität eröffnet zweifellos neue Möglichkeiten für die automatisierte Verarbeitung in Bereichen wie Wissenschaft, Musik und Datenanalyse.
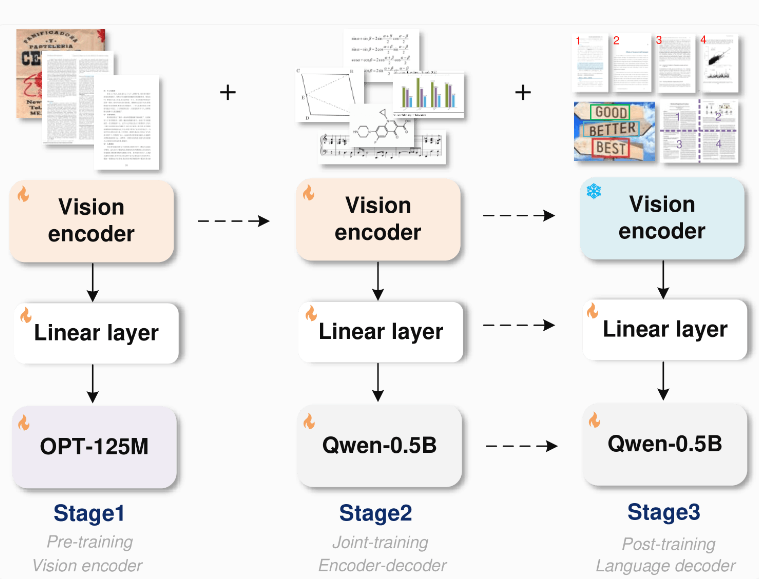
Um den Trainingsprozess zu optimieren, trainierte das Forschungsteam zunächst den Encoder nur für die Texterkennungsaufgabe, führte dann Alibabas Qwen-0.5B als Decoder ein und optimierte das Modell mithilfe verschiedener synthetischer Daten. Sie generierten Trainingsdaten von Millionen von Bild- und Textpaaren mit Rendering-Tools wie LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib und Pyecharts.

Der modulare Aufbau von GOT ermöglicht eine flexible Erweiterung neuer Funktionen in der Zukunft, ohne das gesamte Modell neu zu trainieren. Dieser Aufbau verbessert die Aktualisierungseffizienz des Systems erheblich. Darüber hinaus sagten die Forscher, dass GOT bei verschiedenen OCR-Aufgaben gute Leistungen erbringt, insbesondere bei der Dokument- und Szenentexterkennung, und sogar einige Spezialmodelle und große Sprachmodelle bei der Diagrammerkennung übertrifft.

Erwähnenswert ist, dass das Forschungsteam die kostenlose Demo und den Code von GOT auf Hugging Face veröffentlicht hat, damit andere sie nutzen und weiterentwickeln können. Dieses neue Modell wird zweifellos die Entwicklung der OCR-Technologie vorantreiben und breitere Anwendungsperspektiven eröffnen.
Demo-Zugang: https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo
Highlight:
? GOT (General OCR Theory) ist ein neues OCR-Modell, das das traditionelle OCR-System mit einem großen Sprachmodell namens OCR2.0 kombiniert.
? Dieses Modell kann eine Vielzahl visueller Informationen erkennen und konvertieren, darunter Texte, Formeln, Musiksymbole und Diagramme, und ist auf eine Vielzahl von Bereichen anwendbar.
? Modularer Aufbau und synthetisches Datentraining bieten GOT flexible Erweiterungsmöglichkeiten und hervorragende Leistung bei mehreren OCR-Aufgaben.
Die Open-Source-Veröffentlichung des GOT-Modells wird zweifellos die Innovation der OCR-Technologie beschleunigen und intelligentere und effizientere Texterkennungslösungen in alle Lebensbereiche bringen. Wir freuen uns darauf, dass GOT in zukünftigen Anwendungen ein größeres Potenzial zeigt!