Der Herausgeber von Downcodes erfuhr, dass Forschungsteams des Illinois Institute of Technology und anderer Universitäten gemeinsam Robin3D veröffentlicht haben, ein neues großes Sprachmodell für 3D-Szenen. Das Modell wurde anhand eines riesigen Datensatzes mit Millionen von Anweisungen trainiert und erzielte bei fünf häufig verwendeten multimodalen 3D-Lern-Benchmarks eine Spitzenleistung. Die Innovation von Robin3D liegt in seiner Daten-Engine RIG, die kontradiktorische und diversifizierte Befehlsdaten generieren kann, wodurch die Unterscheidungs-, Verständnis- und Generalisierungsfähigkeiten des Modells verbessert werden und die unzureichenden Generalisierungsfähigkeiten und Überanpassungsprobleme des bestehenden 3D-Großsprachenmodells überwunden werden. Es integriert auch Technologien wie Relationship Augmentation Projektor (RAP) und ID Feature Binding (IFB), um das Verständnis des Modells für Szenen und Objekte zu verbessern.
Das Modell wurde anhand eines umfangreichen Datensatzes trainiert, der eine Million zu befolgende Anweisungen enthielt, und erzielte bei fünf häufig verwendeten multimodalen 3D-Lern-Benchmarks Spitzenleistungen, was einen wichtigen Schritt beim Aufbau eines universellen 3D-Modells darstellt. Signifikanter Fortschritt in Richtung intelligenter Agenten.
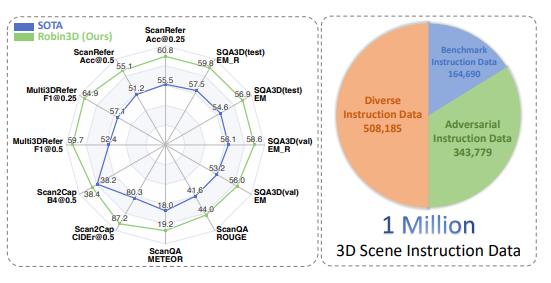
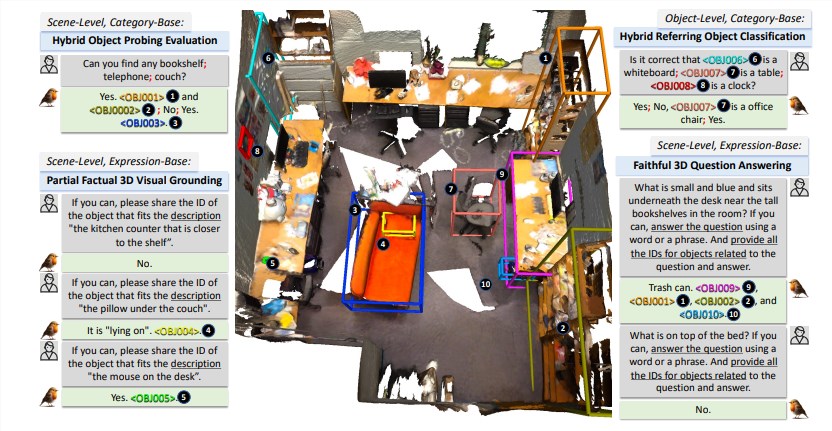
Der Erfolg von Robin3D ist auf seine innovative Daten-Engine RIG (Robust Instruction Generation) zurückzuführen. Die RIG-Engine ist darauf ausgelegt, zwei wichtige Befehlsdatentypen zu generieren: Daten zur Einhaltung gegnerischer Befehle und Daten zur Einhaltung diverser Befehle.
Kontroverse Follow-Through-Daten verbessern das Unterscheidungsverständnis des Modells durch die Mischung positiver und negativer Stichproben, während Diversity Follow-Through-Daten verschiedene Anweisungsstile enthalten, um die Generalisierungsfähigkeit des Modells zu verbessern.
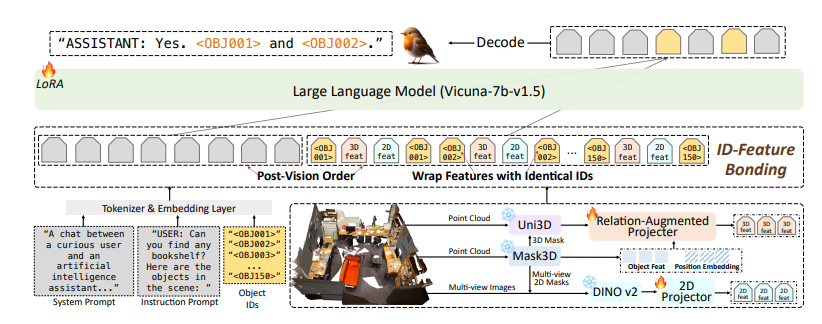
Die Forscher wiesen darauf hin, dass bestehende 3D-Großsprachenmodelle für das Training hauptsächlich auf frontalen 3D-visuellen Sprachpaarungen und vorlagenbasierten Anweisungen basieren, was zu unzureichenden Generalisierungsfähigkeiten und dem Risiko einer Überanpassung führt. Robin3D überwindet diese Einschränkungen effektiv durch die Einführung kontroverser und vielfältiger Befehlsdaten.
Das Robin3D-Modell integriert außerdem Relationship Augmented Projektor (RAP) ID Feature Binding (IFB)-Referenzierungs- und Positionierungsfunktionen. Das RAP-Modul erweitert objektzentrierte Funktionen durch umfangreiche Kontext- und Standortinformationen auf Szenenebene, während das IFB-Modul die Verbindungen zwischen den einzelnen IDs stärkt, indem es sie an die entsprechenden Funktionen bindet.
Experimentelle Ergebnisse zeigen, dass Robin3D die bisher besten Methoden bei fünf Benchmarks übertrifft, darunter ScanRefer, Multi3DRefer, Scan2Cap, ScanQA und SQA3D, ohne dass eine Feinabstimmung für bestimmte Aufgaben erforderlich ist.
Insbesondere in der Multi3DRefer-Auswertung einschließlich des Zero-Target-Falls erzielte Robin3D deutliche Verbesserungen von 7,8 % bzw. 7,3 % bei den Indikatoren F1@0,25 und F1@0,5.
Die Veröffentlichung von Robin3D stellt einen bedeutenden Fortschritt in der räumlichen Intelligenz großer 3D-Sprachmodelle dar und legt eine solide Grundlage für die Entwicklung vielseitigerer und leistungsfähigerer 3D-Agenten in der Zukunft.
Papieradresse: https://arxiv.org/pdf/2410.00255
Das Aufkommen von Robin3D hat zweifellos neue Durchbrüche in den Bereichen 3D-Vision und künstliche Intelligenz gebracht. Seine leistungsstarke Leistung und seine breiten Anwendungsaussichten sind es wert, gespannt zu sein. Ich glaube, dass Robin3D in Zukunft in mehr Bereichen eine Rolle spielen und die schnelle Entwicklung der 3D-Intelligenz vorantreiben wird. Der Herausgeber von Downcodes wird die neuesten Entwicklungen in diesem Bereich weiterhin aufmerksam verfolgen.