Der Herausgeber von Downcodes erfuhr, dass eine bahnbrechende Studie an der Yale University das Geheimnis des KI-Modelltrainings enthüllte: Je höher die Datenkomplexität, desto besser, sondern es gibt einen optimalen „Rand des Chaos“-Zustands. Das Forschungsteam nutzte das zelluläre Automatenmodell geschickt zur Durchführung von Experimenten, untersuchte den Einfluss von Daten unterschiedlicher Komplexität auf den Lerneffekt des KI-Modells und kam zu auffälligen Schlussfolgerungen.
Ein Forschungsteam der Yale University hat kürzlich ein bahnbrechendes Forschungsergebnis veröffentlicht, das eine wichtige Erkenntnis beim Training von KI-Modellen enthüllt: Die Daten mit dem besten KI-Lerneffekt sind nicht einfacher oder komplexer, aber es gibt ein optimales Komplexitätsniveau – einen Zustand, der als bekannt ist Rand des Chaos.
Das Forschungsteam führte Experimente mit elementaren zellulären Automaten (ECAs) durch, bei denen es sich um einfache Systeme handelt, bei denen der zukünftige Zustand jeder Einheit nur von sich selbst und den Zuständen zweier benachbarter Einheiten abhängt. Trotz der Einfachheit der Regeln können solche Systeme vielfältige Muster erzeugen, die von einfach bis hochkomplex reichen. Anschließend bewerteten die Forscher die Leistung dieser Sprachmodelle bei Denkaufgaben und der Vorhersage von Schachzügen.
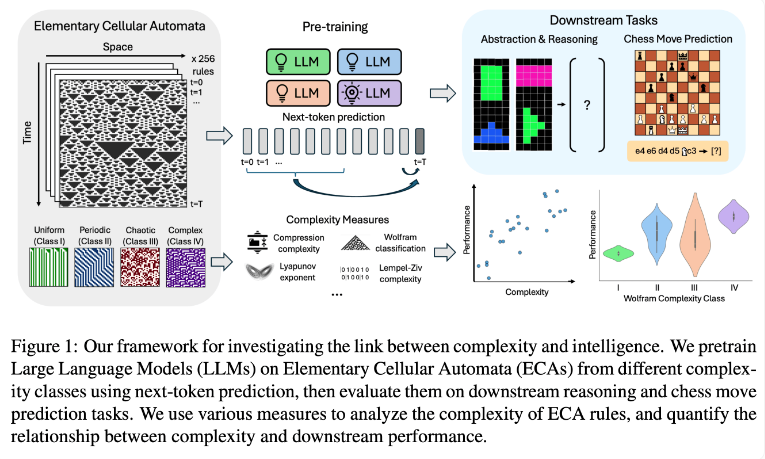
Forschungsergebnisse zeigen, dass KI-Modelle, die auf komplexere ECA-Regeln trainiert wurden, bei nachfolgenden Aufgaben eine bessere Leistung erbringen. Insbesondere zeigten Modelle, die auf ECAs der Klasse IV in der Wolfram-Klassifikation trainiert wurden, die beste Leistung. Die durch solche Regeln erzeugten Muster sind weder völlig geordnet noch völlig chaotisch, sondern weisen vielmehr eine strukturierte Komplexität auf.
Die Forscher fanden heraus, dass Modelle, die zu einfachen Mustern ausgesetzt waren, oft nur einfache Lösungen lernten. Im Gegensatz dazu entwickeln Modelle, die auf komplexere Muster trainiert wurden, anspruchsvollere Verarbeitungsfähigkeiten, selbst wenn einfache Lösungen verfügbar sind. Das Forschungsteam geht davon aus, dass die Komplexität dieser erlernten Darstellung ein Schlüsselfaktor für die Fähigkeit des Modells ist, Wissen auf andere Aufgaben zu übertragen.
Dieser Befund könnte erklären, warum große Sprachmodelle wie GPT-3 und GPT-4 so effizient sind. Die Forscher glauben, dass die umfangreichen und vielfältigen Daten, die beim Training dieser Modelle verwendet wurden, ähnliche Effekte wie die komplexen ECA-Muster in ihrer Studie hervorgerufen haben könnten.
Diese Forschung liefert neue Ideen für das Training von KI-Modellen und eine neue Perspektive für das Verständnis der leistungsstarken Fähigkeiten großer Sprachmodelle. In Zukunft können wir möglicherweise die Leistung und Generalisierungsfähigkeiten von KI-Modellen weiter verbessern, indem wir die Komplexität der Trainingsdaten genauer steuern. Der Herausgeber von Downcodes glaubt, dass dieses Forschungsergebnis tiefgreifende Auswirkungen auf den Bereich der künstlichen Intelligenz haben wird.