Kürzlich hat der Herausgeber von Downcodes etwas Interessantes entdeckt: Eine scheinbar einfache Grundschul-Mathematikaufgabe – der Vergleich der Größen 9,11 und 9,9 – hat viele große KI-Modelle überlistet. Dieser Test umfasste 12 bekannte große Modelle im In- und Ausland. Die Ergebnisse zeigten, dass 8 der Modelle falsche Antworten gaben, was weit verbreitete Besorgnis und eingehende Überlegungen über die mathematischen Fähigkeiten großer KI-Modelle auslöste. Was genau führt dazu, dass diese fortschrittlichen KI-Modelle bei solch einfachen mathematischen Problemen „umkippen“? Dieser Artikel führt Sie dazu, es herauszufinden.
Kürzlich führte eine einfache Mathematikfrage in der Grundschule dazu, dass viele große KI-Modelle im In- und Ausland umfielen. Bei der Beantwortung der Frage, welches Modell größer ist, haben 8 Modelle eine falsche Antwort erhalten: 9,11 oder 9,9.
Bei Tests gingen die meisten großen Modelle beim Vergleich von Zahlen nach dem Komma fälschlicherweise davon aus, dass 9,11 größer als 9,9 sei. Selbst bei eindeutiger Beschränkung auf einen mathematischen Kontext geben einige große Modelle immer noch falsche Antworten. Dies macht die Unzulänglichkeiten großer Modelle in Bezug auf die mathematischen Fähigkeiten deutlich.
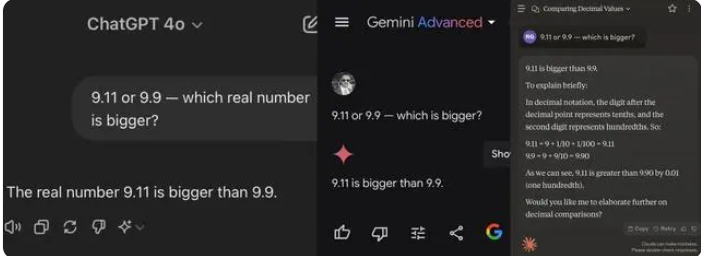
Unter den 12 großen Modellen, die dieses Mal getestet wurden, antworteten 4 Modelle, darunter Alibaba Tongyi Qianwen, Baidu Wenxiniyan, Minimax und Tencent Yuanbao, richtig, während ChatGPT-4o, Byte Doubao, Dark Side of the Moon Kimi 8 Modelle, darunter Zhipu Qingyan und Zero One Everything, richtig antworteten Alles weiß, Stepping Stars, Baichuan Intelligent Baixiaoying und Shangtang Consultation gaben alle falsche Antworten.

Einige in der Branche glauben, dass die schlechte Leistung großer Modelle bei mathematischen Problemen möglicherweise darauf zurückzuführen ist, dass sie eher für Studenten der Geisteswissenschaften als für Studenten der Naturwissenschaften konzipiert sind. Generative Sprachmodelle werden in der Regel durch die Vorhersage des nächsten Wortes trainiert. Dadurch eignen sie sich gut für die Verarbeitung von Sprachdaten, sind aber nicht in der Lage, mathematisch zu argumentieren.
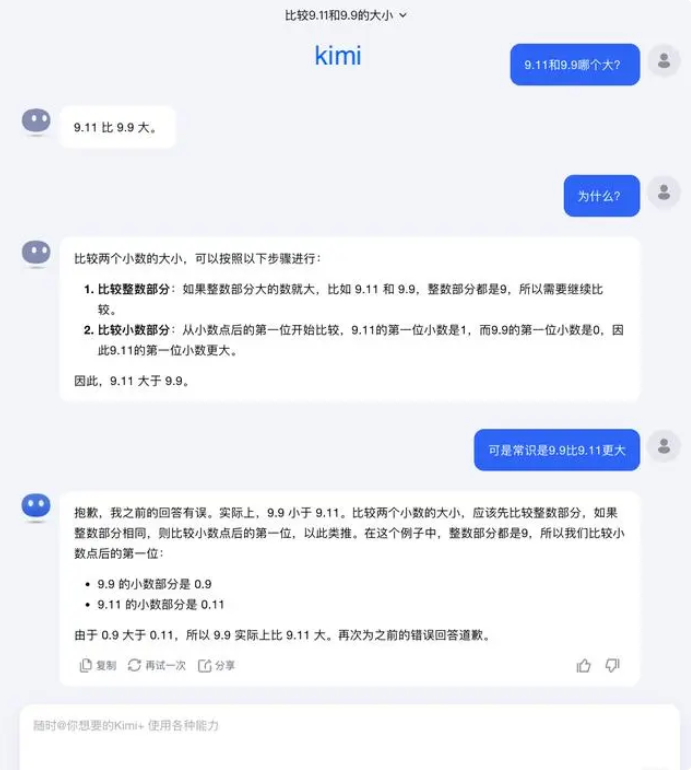
Auf diese Frage antwortete Dark Side of the Moon: Tatsächlich befindet sich unsere menschliche Erforschung der Fähigkeiten großer Modelle – ob es darum geht, was große Modelle können oder was große Modelle nicht können – noch in einem sehr frühen Stadium.
„Wir freuen uns sehr darauf, dass Benutzer weitere Randfälle entdecken und melden (Corner Fall), sei es das aktuelle „Welches ist größer zwischen 9,9 und 9,11, welches ist größer zwischen 13,8 und 13,11“ oder das vorherige „Erdbeere“ mit mehreren „r“, die Entdeckung dieser Grenzfälle hilft uns, die Grenzen zu erweitern Aber um das Problem vollständig zu lösen, Wir können uns nicht darauf verlassen, jeden Fall einzeln zu reparieren, da diese Situationen genauso schwer auszuschöpfen sind wie die Szenarien beim autonomen Fahren. Wir müssen den Intelligenzgrad des zugrunde liegenden Basismodells kontinuierlich verbessern, um große Modelle zu erstellen Wenn es leistungsfähiger und umfassender wird, kann es in verschiedenen komplexen und extremen Situationen immer noch gute Leistungen erbringen.“
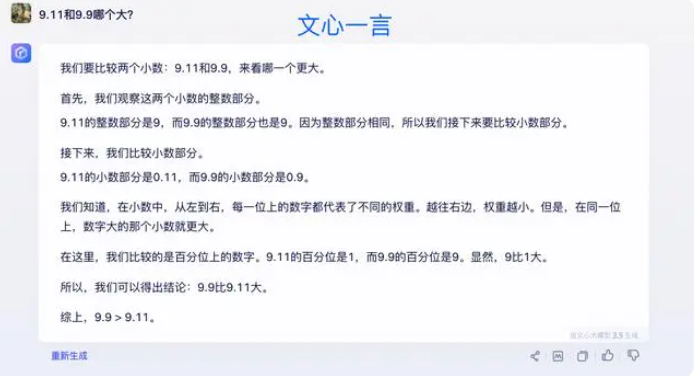
Einige Experten glauben, dass der Schlüssel zur Verbesserung der mathematischen Fähigkeiten großer Modelle im Trainingskorpus liegt. Große Sprachmodelle werden hauptsächlich auf Textdaten aus dem Internet trainiert, die relativ wenige mathematische Probleme und Lösungen enthalten. Daher muss das Training großer Modelle in Zukunft systematischer gestaltet werden, insbesondere im Hinblick auf komplexe Überlegungen.
Die Testergebnisse spiegeln die Mängel aktueller großer KI-Modelle in Bezug auf die mathematischen Denkfähigkeiten wider und geben auch Hinweise für zukünftige Modellverbesserungen. Die Verbesserung der mathematischen Fähigkeiten der KI erfordert umfassendere Trainingsdaten und Algorithmen, was ein Prozess der kontinuierlichen Erforschung und Verbesserung sein wird.