Künstliche Intelligenz hat in den letzten Jahren erhebliche Fortschritte bei der Bilderkennung gemacht, das Videoverständnis bleibt jedoch eine große Herausforderung. Die Dynamik und Komplexität von Videodaten stellen die KI vor beispiellose Schwierigkeiten. Der vom Google-Forschungsteam entwickelte Video-Encoder VideoPrism soll diese Situation jedoch ändern. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis der leistungsstarken Funktionen und Trainingsmethoden von VideoPrism und seiner tiefgreifenden Auswirkungen auf den zukünftigen Bereich des KI-Videoverständnisses.
In der Welt der KI ist es für Maschinen viel schwieriger, Videos zu verstehen als Bilder. Das Video ist dynamisch, mit Ton, Bewegung und einer Reihe komplexer Szenen. Früher war das Ansehen von Videos mit KI so, als würde man ein Buch vom Himmel lesen, und man war oft verwirrt.
Aber das Aufkommen von VideoPrism könnte alles verändern. Dies ist ein vom Google-Forschungsteam entwickelter Video-Encoder, der mit einem einzigen Modell bei einer Vielzahl von Video-Verständnisaufgaben das neueste Niveau erreichen kann. Ob es darum geht, Videos zu klassifizieren, zu positionieren, Untertitel zu erstellen oder sogar Fragen zu Videos zu beantworten, VideoPrism erledigt das problemlos.

Wie trainiere ich VideoPrism?
Das Training von VideoPrism ist so, als würde man einem Kind beibringen, die Welt zu beobachten. Zunächst müssen Sie ihm verschiedene Videos zeigen, die vom Alltag bis zu wissenschaftlichen Beobachtungen reichen. Anschließend trainieren Sie es auch mit einigen „hochwertigen“ Video-Untertitel-Paaren und etwas verrauschtem Paralleltext (z. B. Text mit automatischer Spracherkennung).
Methode vor dem Training
Daten: VideoPrism verwendet 36 Millionen hochwertige Video-Untertitel-Paare und 58,2 Millionen Videoclips mit verrauschtem Paralleltext.
Modellarchitektur: Basierend auf dem Standard Visual Transformer (ViT) mit faktorisiertem Design in Raum und Zeit.
Trainingsalgorithmus: umfasst zwei Phasen: Video-Text-Vergleichstraining und maskierte Videomodellierung.
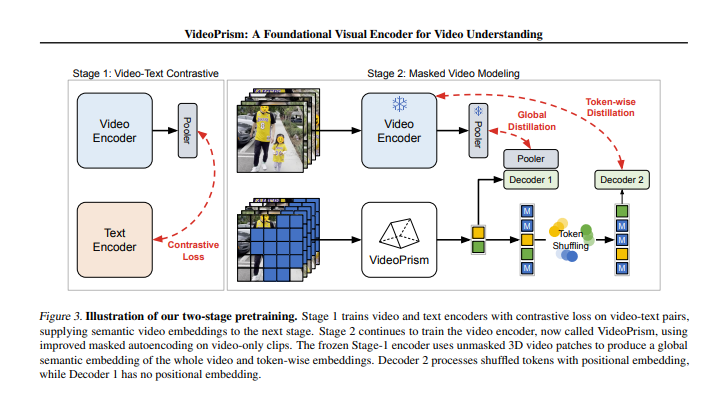
Während des Trainingsprozesses durchläuft VideoPrism zwei Phasen. In der ersten Stufe lernt es die Verbindung zwischen Video und Text durch kontrastives Lernen und global-lokale Destillation. In der zweiten Stufe wird das Verständnis von Videoinhalten durch maskierte Videomodellierung weiter verbessert.
Die Forscher testeten VideoPrism bei mehreren Videoverständnisaufgaben und die Ergebnisse waren beeindruckend. VideoPrism erreicht in 30 von 33 Benchmarks Spitzenleistungen. Ob es um die Beantwortung von Online-Videofragen oder um Computer-Vision-Aufgaben im wissenschaftlichen Bereich geht, VideoPrism hat starke Fähigkeiten unter Beweis gestellt.
Die Geburt von VideoPrism hat dem Bereich des KI-Videoverständnisses neue Möglichkeiten eröffnet. Es kann der KI nicht nur dabei helfen, Videoinhalte besser zu verstehen, sondern könnte auch eine wichtige Rolle in den Bereichen Bildung, Unterhaltung, Sicherheit und anderen Bereichen spielen.
Aber VideoPrism steht auch vor einigen Herausforderungen, etwa beim Umgang mit langen Videos und bei der Vermeidung von Vorurteilen während des Trainingsprozesses. Dies sind Fragen, die in der zukünftigen Forschung angegangen werden müssen.
Papieradresse: https://arxiv.org/pdf/2402.13217
Alles in allem stellt das Aufkommen von VideoPrism einen großen Fortschritt auf dem Gebiet des KI-Videoverständnisses dar. Seine leistungsstarke Leistung und seine breiten Anwendungsaussichten sind aufregend. Ich glaube, dass VideoPrism in Zukunft mit der kontinuierlichen Weiterentwicklung der Technologie seinen Wert in mehr Bereichen unter Beweis stellen und den Menschen mehr Komfort bieten wird.