Der Herausgeber von Downcodes erfuhr, dass Groq kürzlich eine erstaunliche LLM-Engine veröffentlicht hat, deren Verarbeitungsgeschwindigkeit die Erwartungen der Branche bei weitem übertrifft und Entwicklern ein beispielloses interaktives Erlebnis mit großen Sprachmodellen bietet. Diese Engine basiert auf Metas Open-Source-LLama3-8b-8192LLM und unterstützt andere Modelle. Ihre Verarbeitungsgeschwindigkeit liegt bei bis zu 1256,54 Mark pro Sekunde und liegt damit deutlich vor GPU-Chips von Unternehmen wie Nvidia. Diese bahnbrechende Entwicklung erregte nicht nur große Aufmerksamkeit bei Entwicklern, sondern ermöglichte auch normalen Benutzern ein schnelleres und flexibleres LLM-Anwendungserlebnis.
Groq hat kürzlich auf seiner Website eine blitzschnelle LLM-Engine eingeführt, die es Entwicklern ermöglicht, schnelle Abfragen und Aufgabenausführungen direkt an großen Sprachmodellen durchzuführen.
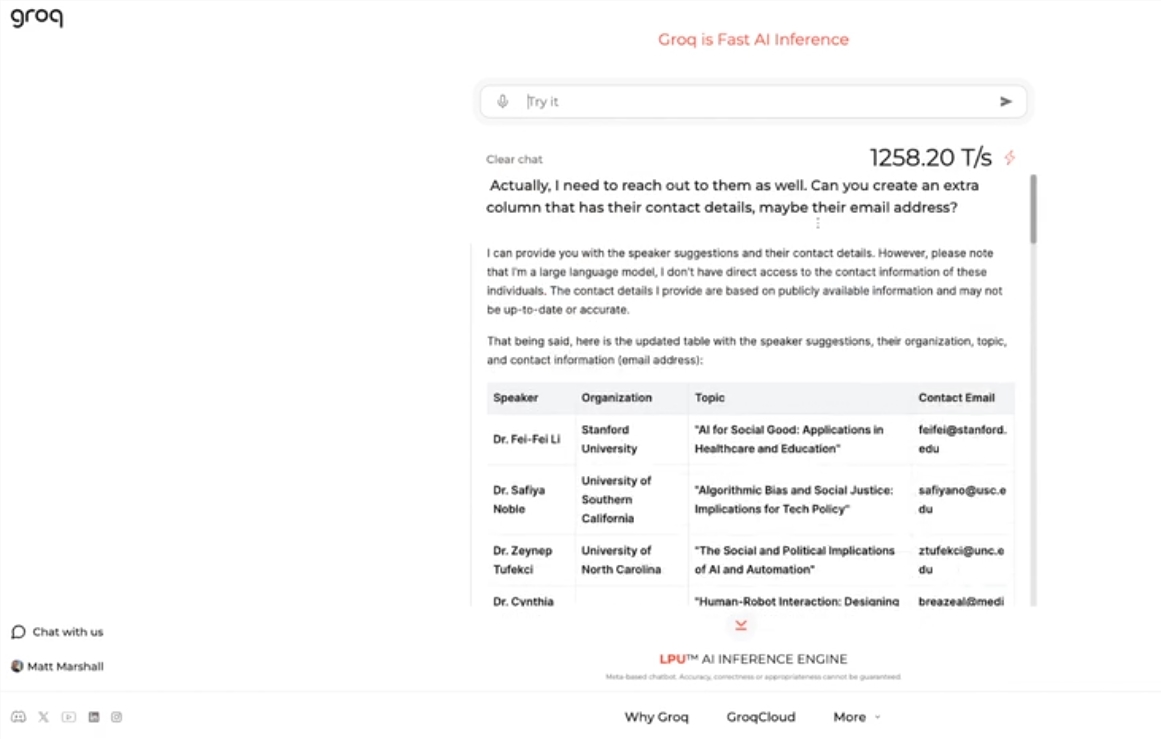
Diese Engine verwendet Metas Open-Source-LLama3-8b-8192LLM, unterstützt standardmäßig andere Modelle und ist erstaunlich schnell. Laut Testergebnissen schafft Groqs Engine 1256,54 Punkte pro Sekunde und übertrifft damit GPU-Chips von Unternehmen wie Nvidia bei weitem. Der Schritt erregte große Aufmerksamkeit bei Entwicklern und Nicht-Entwicklern und demonstrierte die Geschwindigkeit und Flexibilität des LLM-Chatbots.
Jonathan Ross, CEO von Groq, sagte, der Einsatz von LLMs werde weiter zunehmen, da die Menschen entdecken, wie einfach es ist, sie auf der schnellen Engine von Groq zu verwenden. Durch die Demonstration können die Leute sehen, dass verschiedene Aufgaben problemlos mit dieser Geschwindigkeit erledigt werden können, wie z. B. das Erstellen von Stellenanzeigen, das Ändern von Artikelinhalten usw. Die Engine von Groq kann sogar Abfragen auf der Grundlage von Sprachbefehlen durchführen, was ihre Leistungsfähigkeit und Benutzerfreundlichkeit unter Beweis stellt.
Neben kostenlosen LLM-Workload-Diensten stellt Groq Entwicklern auch eine Konsole zur Verfügung, mit der sie auf OpenAI basierende Anwendungen problemlos auf Groq umstellen können.
Diese einfache Wechselmethode hat eine große Anzahl von Entwicklern angezogen und derzeit haben mehr als 280.000 Menschen die Dienste von Groq genutzt. CEO Ross sagte, dass bis zum nächsten Jahr mehr als die Hälfte der weltweiten Inferenzberechnungen auf den Chips von Groq ausgeführt werden, was das Potenzial und die Aussichten des Unternehmens im Bereich KI demonstriert.
Highlight:
Groq führt die blitzschnelle LLM-Engine ein, die 1256,54 Punkte pro Sekunde verarbeitet, weitaus schneller als die GPU-Geschwindigkeit
Die Engine von Groq demonstriert die Geschwindigkeit und Flexibilität von LLM-Chatbots und zieht die Aufmerksamkeit von Entwicklern und Nicht-Entwicklern gleichermaßen auf sich
? Groq bietet einen kostenlosen LLM-Workload-Service, der von mehr als 280.000 Entwicklern genutzt wird. Es wird erwartet, dass im nächsten Jahr die Hälfte der Inferenzberechnungen weltweit auf seinen Chips ausgeführt werden
Die schnelle LLM-Engine von Groq bringt zweifellos neue Möglichkeiten in den KI-Bereich, und ihre hohe Leistung und Benutzerfreundlichkeit werden eine breitere Anwendung der LLM-Technologie fördern. Der Herausgeber von Downcodes glaubt, dass es sich lohnt, auf die zukünftige Entwicklung von Groq zu blicken!