In den letzten Jahren ist die rasante Entwicklung der Technologie der künstlichen Intelligenz stark auf das Training großer Datenmengen angewiesen. Der Herausgeber von Downcodes stellte jedoch fest, dass die neuesten Untersuchungen des MIT und anderer Institutionen darauf hinwiesen, dass die Schwierigkeit, Daten zu erhalten, dramatisch zunimmt. Früher leicht verfügbare Netzwerkdaten unterliegen heute immer strengeren Beschränkungen, was die Ausbildung und Entwicklung von KI vor große Herausforderungen stellt. Die Studie, die mehrere Open-Source-Datensätze analysierte, offenbart diese krasse Realität.
Hinter der rasanten Entwicklung der künstlichen Intelligenz taucht ein ernstes Problem auf: Die Schwierigkeit der Datenerfassung nimmt zu. Die neuesten Untersuchungen des MIT und anderer Institutionen haben ergeben, dass Webdaten, die einst leicht zugänglich waren, nun immer schwieriger zugänglich werden, was eine große Herausforderung für die KI-Ausbildung und -Forschung darstellt.
Forscher fanden heraus, dass die Lizenzvereinbarungen der Websites, die von mehreren Open-Source-Datensätzen wie C4, RefineWeb, Dolma usw. gecrawlt werden, rasch verschärft werden. Dies beeinträchtigt nicht nur das Training kommerzieller KI-Modelle, sondern behindert auch die Forschung akademischer und gemeinnütziger Organisationen.

Diese Forschung wurde von vier Teamleitern des MIT Media Lab, des Wellesley College, des KI-Startups Raive und anderer Institutionen durchgeführt. Sie stellen fest, dass Datenbeschränkungen zunehmen und Lizenzasymmetrien und Inkonsistenzen immer offensichtlicher werden.
Als Forschungsmethoden nutzte das Forschungsteam das Robots Exclusion Protocol (REP) und die Nutzungsbedingungen (ToS) der Website. Sie fanden heraus, dass selbst Crawler von großen KI-Unternehmen wie OpenAI immer strengeren Einschränkungen ausgesetzt waren.
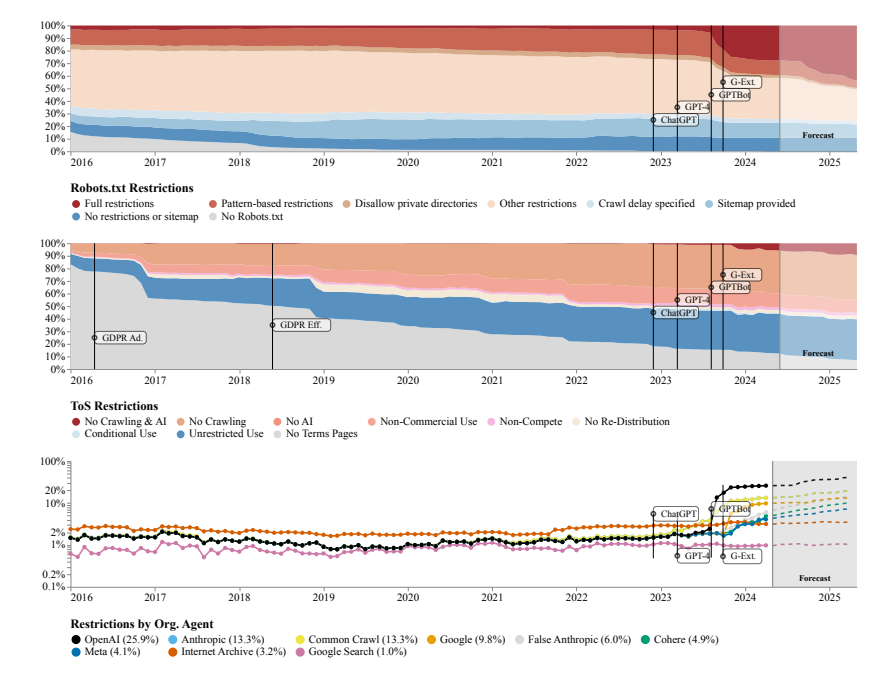
Das SARIMA-Modell prognostiziert, dass die Website-Datenbeschränkungen in Zukunft weiter zunehmen werden, sei es durch robots.txt oder ToS. Dies deutet darauf hin, dass der Zugang zu offenen Netzwerkdaten schwieriger wird.
Die Studie ergab außerdem, dass die aus dem Internet gecrawlten Daten nicht mit dem Trainingszweck des KI-Modells übereinstimmen, was Auswirkungen auf die Modellausrichtung, Datenerfassungspraktiken und das Urheberrecht haben kann.
Das Forschungsteam fordert die Notwendigkeit flexiblerer Vereinbarungen, die die Wünsche der Website-Betreiber widerspiegeln, zulässige und unzulässige Anwendungsfälle trennen und mit den Nutzungsbedingungen synchronisiert werden. Gleichzeitig wollen sie, dass KI-Entwickler Daten im offenen Web für Schulungen nutzen können, und hoffen, dass zukünftige Gesetze dies unterstützen.
Papieradresse: https://www.dataprovenance.org/Consent_in_Crisis.pdf
Diese Forschung hat Alarm geschlagen hinsichtlich des Problems der Datenerfassung im Bereich der künstlichen Intelligenz und auch neue Herausforderungen für das Training und die Entwicklung zukünftiger KI-Modelle aufgeworfen. Wie die Datenerfassung und die Rechte und Interessen der Website-Besitzer in Einklang gebracht werden können, wird zu einem zentralen Thema, das im Bereich der künstlichen Intelligenz ernsthaft geprüft und gelöst werden muss. Der Herausgeber von Downcodes empfiehlt, den Artikel aufmerksam zu lesen, um weitere Einzelheiten zu erfahren.