Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis der Geheimnisse des Transformer-Modells! Kürzlich wurde in einem Artikel mit dem Titel „Transformer-Schichten als Maler“ der Funktionsmechanismus der mittleren Schicht des Transformer-Modells aus der Perspektive eines „Malers“ anschaulich erläutert. Durch clevere Metaphern und Experimente enthüllt dieser Artikel, wie die Transformer-Hierarchie funktioniert, und liefert uns neue Ideen, um die internen Abläufe großer Sprachmodelle zu verstehen. In der Arbeit vergleicht der Autor jede Schicht des Transformers mit einem Maler, der zusammenarbeitet, um ein großartiges Sprachbild zu schaffen, und verifiziert diese Ansicht durch eine Reihe von Experimenten.
In der Welt der künstlichen Intelligenz gibt es eine besondere Gruppe von Malern – die hierarchische Struktur im Transformer-Modell. Sie sind wie magische Pinsel, die eine farbenfrohe Welt auf die Leinwand der Sprache malen. Ein kürzlich veröffentlichter Artikel mit dem Titel „Transformer Layers as Painters“ bietet uns eine neue Perspektive, um den Arbeitsmechanismus der Transformer-Mittelschicht zu verstehen.
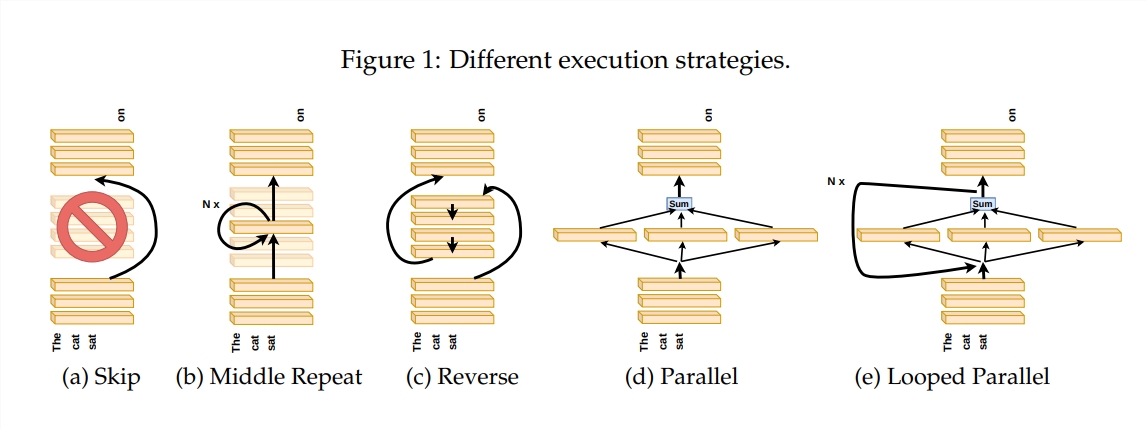
Das Transformer-Modell ist derzeit das beliebteste groß angelegte Sprachmodell und verfügt über Milliarden von Parametern. Jede Schicht davon ist wie ein Maler, der zusammenarbeitet, um ein großartiges Sprachbild zu vervollständigen. Aber wie haben diese Maler zusammengearbeitet? Wie unterschieden sich die von ihnen verwendeten Pinsel und Farben? In diesem Artikel wird versucht, diese Fragen zu beantworten.
Um zu untersuchen, wie die Transformer-Ebene funktioniert, hat der Autor eine Reihe von Experimenten entworfen, darunter das Überspringen bestimmter Ebenen, das Ändern der Reihenfolge der Ebenen oder das parallele Ausführen von Ebenen. Diese Experimente ähneln der Festlegung unterschiedlicher Malregeln für Maler, um zu sehen, ob sie sich anpassen können.
In der Metapher der „Pipeline des Malers“ wird die Eingabe als Leinwand betrachtet, und der Prozess des Durchlaufens der Zwischenschichten ähnelt dem Durchlaufen der Leinwand am Fließband. Jeder „Maler“, also jede Schicht des Transformers, wird das Gemälde entsprechend seinem eigenen Fachwissen modifizieren. Diese Analogie hilft uns, die Parallelität und Skalierbarkeit der Transformer-Schicht zu verstehen.
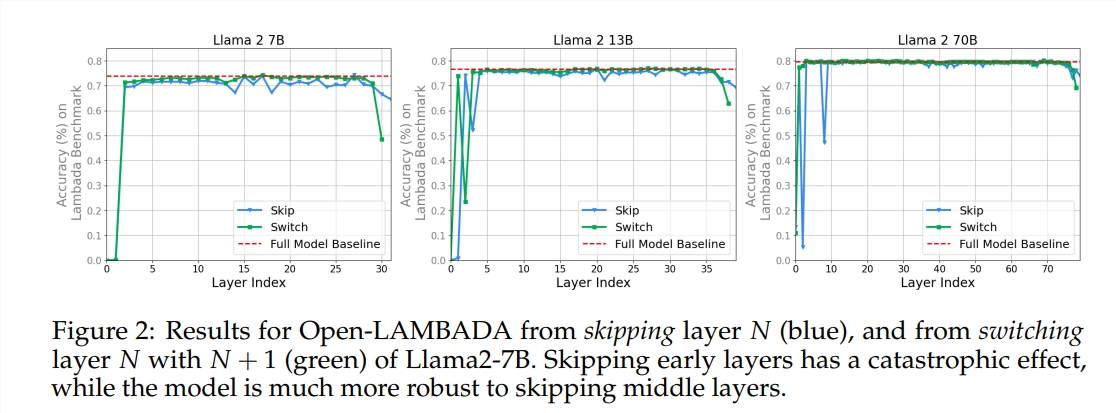
Das Experiment verwendete zwei vorab trainierte große Sprachmodelle (LLM): Llama2-7B und BERT. Die Studie ergab, dass die Maler in den mittleren Rängen anscheinend einen gemeinsamen Farbkasten hatten, der den Raum repräsentierte und sich von jenen in den ersten und letzten Rängen unterschied. Maler, die bestimmte Zwischenschichten überspringen, haben nur geringe Auswirkungen auf das gesamte Gemälde, was darauf hindeutet, dass nicht alle Maler erforderlich sind.
Obwohl die Maler in der mittleren Schicht denselben Farbkasten verwenden, nutzen sie ihre eigenen Fähigkeiten, um unterschiedliche Muster auf die Leinwand zu malen. Wenn Sie einfach eine bestimmte Maltechnik wiederverwenden, verliert das Gemälde seinen ursprünglichen Charme.
Die Reihenfolge, in der Sie zeichnen, ist besonders wichtig für Mathematik- und Denkaufgaben, die eine strenge Logik erfordern. Bei Aufgaben, die auf semantischem Verständnis beruhen, ist der Einfluss der Reihenfolge relativ gering.
Die Forschungsergebnisse zeigen, dass die mittlere Schicht des Transformers einen gewissen Grad an Konsistenz aufweist, aber nicht redundant ist. Bei Mathematik- und Argumentationsaufgaben ist die Reihenfolge der Schichten wichtiger als bei semantischen Aufgaben.
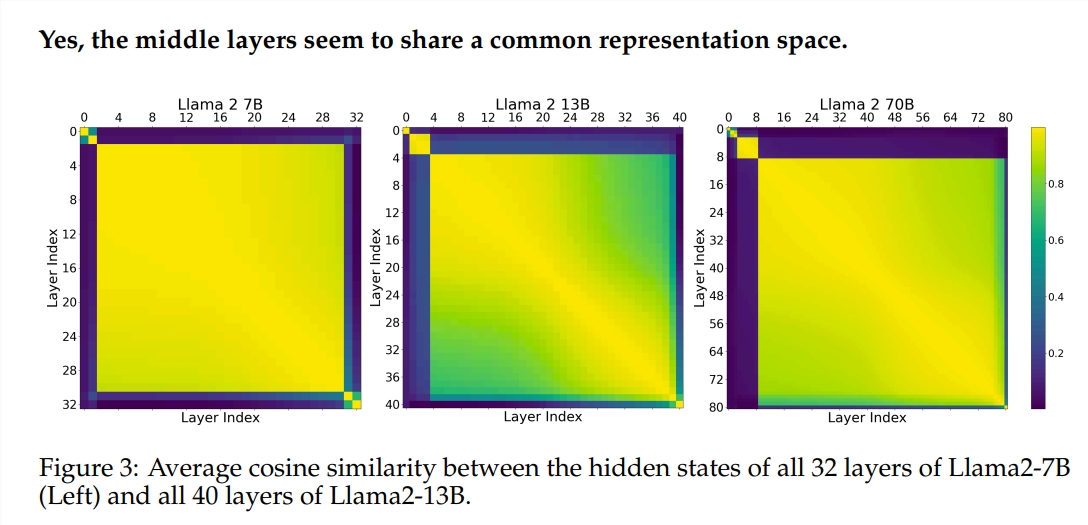
Die Studie ergab außerdem, dass nicht alle Schichten notwendig sind und dass Zwischenschichten übersprungen werden können, ohne die Modellleistung katastrophal zu beeinträchtigen. Obwohl sich die Zwischenschichten denselben Darstellungsraum teilen, erfüllen sie darüber hinaus unterschiedliche Funktionen. Das Ändern der Ausführungsreihenfolge von Ebenen führte zu Leistungseinbußen, was darauf hindeutet, dass die Reihenfolge einen wichtigen Einfluss auf die Modellleistung hat.
Auf dem Weg zur Erforschung des Transformer-Modells versuchen viele Forscher, es zu optimieren, einschließlich Beschneiden, Reduzieren von Parametern usw. Diese Arbeiten liefern wertvolle Erfahrungen und Inspiration für das Verständnis des Transformer-Modells.
Papieradresse: https://arxiv.org/pdf/2407.09298v1
Alles in allem bietet uns dieser Artikel eine neue Perspektive zum Verständnis des internen Mechanismus des Transformer-Modells und liefert neue Ideen für die zukünftige Modelloptimierung. Der Herausgeber von Downcodes empfiehlt interessierten Lesern, den vollständigen Artikel zu lesen, um ein tieferes Verständnis der Geheimnisse des Transformer-Modells zu erlangen!