Der Bereich der Verarbeitung natürlicher Sprache (NLP) verändert sich mit jedem Tag, und die rasante Entwicklung großer Sprachmodelle (LLMs) hat uns beispiellose Chancen und Herausforderungen beschert. Unter anderem stellt die Abhängigkeit der Modellbewertung von von Menschen kommentierten Daten einen Engpass dar. Die hohen Kosten und die zeitaufwändige Datenerfassung schränken die effektive Bewertung und kontinuierliche Verbesserung des Modells ein. Der Herausgeber von Downcodes stellt Ihnen eine neue Lösung vor, die von Meta FAIR-Forschern vorgeschlagen wurde – „Self-learning Evaluator“, die eine neue Idee zur Lösung dieses Problems liefert.
Heutzutage entwickelt sich der Bereich der Verarbeitung natürlicher Sprache (NLP) rasant, und große Sprachmodelle (LLMs) können komplexe sprachbezogene Aufgaben mit hoher Genauigkeit ausführen, was der Mensch-Computer-Interaktion mehr Möglichkeiten eröffnet. Ein wesentliches Problem im NLP ist jedoch die Abhängigkeit von menschlichen Anmerkungen zur Modellbewertung.
Von Menschen generierte Daten sind für das Modelltraining und die Validierung von entscheidender Bedeutung, aber das Sammeln dieser Daten ist teuer und zeitaufwändig. Da sich die Modelle weiter verbessern, müssen möglicherweise zuvor gesammelte Anmerkungen aktualisiert werden, wodurch sie für die Bewertung neuer Modelle weniger nützlich werden. Dies führt dazu, dass kontinuierlich neue Daten erfasst werden müssen, was den Umfang und die Nachhaltigkeit einer effektiven Modellbewertung beeinträchtigt.
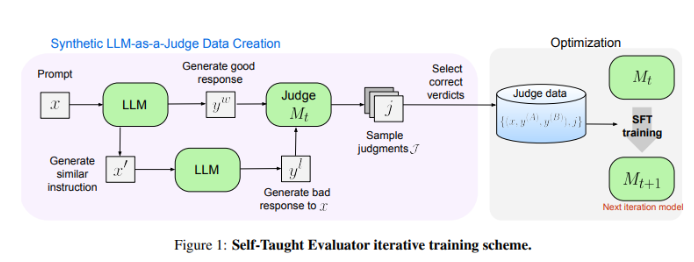
Forscher von Meta FAIR haben eine neue Lösung gefunden – den „Self-Taught Evaluator“. Dieser Ansatz erfordert keine menschlichen Anmerkungen und wird auf synthetisch generierten Daten trainiert. Zunächst generiert ein Seed-Modell kontrastierende synthetische Präferenzpaare. Anschließend wertet das Modell diese Paare aus und verbessert sie iterativ. Dabei nutzt es sein eigenes Urteilsvermögen, um die Leistung in nachfolgenden Iterationen zu verbessern, wodurch die Abhängigkeit von von Menschen erstellten Anmerkungen erheblich reduziert wird.
Die Leistung des „selbstlernenden Evaluators“ testeten die Forscher anhand des Modells Llama-3-70B-Instruct. Diese Methode verbessert die Genauigkeit des Modells im RewardBench-Benchmark von 75,4 auf 88,7 und erreicht damit die Leistung von Modellen, die mit menschlichen Anmerkungen trainiert wurden, oder übertrifft sie sogar. Nach mehreren Iterationen erreichte das endgültige Modell eine Genauigkeit von 88,3 bei einer einzelnen Schlussfolgerung und 88,7 bei einer Mehrheitsabstimmung, was seine hohe Stabilität und Zuverlässigkeit unter Beweis stellt.
Der „Self-Learning Evaluator“ bietet eine skalierbare und effiziente Lösung für die NLP-Modellbewertung, indem er synthetische Daten und iterative Selbstverbesserung nutzt, die Herausforderungen bewältigt, die sich aus der Verwendung menschlicher Annotationen ergeben, und die Entwicklung von Sprachmodellen vorantreibt.
Papieradresse: https://arxiv.org/abs/2408.02666
Der „selbstlernende Evaluator“ von Meta FAIR hat revolutionäre Veränderungen in der NLP-Modellbewertung mit sich gebracht und seine effizienten und skalierbaren Funktionen werden den kontinuierlichen Fortschritt zukünftiger Sprachmodelle effektiv fördern. Dieses Forschungsergebnis verringert nicht nur die Abhängigkeit von von Menschen kommentierten Daten, sondern ebnet vor allem den Weg für die Entwicklung leistungsfähigerer und zuverlässigerer NLP-Modelle. Wir freuen uns auf weitere ähnliche Innovationen in der Zukunft!