Mit der rasanten Entwicklung der künstlichen Intelligenz ist eine leichte und effiziente Technologie zum Verständnis der Benutzeroberfläche zum Schlüssel für KI-Anwendungen geworden. In einem kürzlich veröffentlichten Forschungspapier stellte Apple eine neue Architektur namens UI-JEPA vor, die darauf abzielt, das Problem des effizienten UI-Verständnisses auf leichten Geräten zu lösen. Diese Technologie sorgt nicht nur für eine hohe Leistung, sondern reduziert auch den Rechenbedarf erheblich und bietet neue Möglichkeiten für die Ausführung von KI-Anwendungen auf Geräten mit eingeschränkten Ressourcen. Es wird erwartet, dass das Aufkommen von UI-JEPA die weit verbreitete Popularisierung bequemerer und privaterer KI-Anwendungen vorantreiben wird.
Da die Technologie der künstlichen Intelligenz immer weiter voranschreitet, ist das Verständnis der Benutzeroberfläche (UI) zu einer zentralen Herausforderung bei der Erstellung intuitiver und nützlicher KI-Anwendungen geworden. Kürzlich stellten Apple-Forscher in einem neuen Artikel UI-JEPA vor, eine Architektur, die darauf ausgelegt ist, ein leichtes geräteseitiges UI-Verständnis zu erreichen, das nicht nur eine hohe Leistung aufrechterhält, sondern auch die Kosten für die UI-Berechnungsanforderungen erheblich senkt.
Die Herausforderung beim Verständnis der Benutzeroberfläche liegt in der Notwendigkeit, modalübergreifende Funktionen, einschließlich Bilder und natürlicher Sprache, zu verarbeiten, um zeitliche Beziehungen in UI-Sequenzen zu erfassen. Obwohl multimodale große Sprachmodelle (MLLM) wie Anthropic Claude3.5Sonnet und OpenAI GPT-4Turbo Fortschritte bei der personalisierten Planung gemacht haben, erfordern diese Modelle umfangreiche Rechenressourcen, große Modellgrößen und führen zu einer hohen Latenz. Sie sind nicht für leichte Gerätelösungen mit geringen Anforderungen geeignet Latenz und verbesserte Privatsphäre.
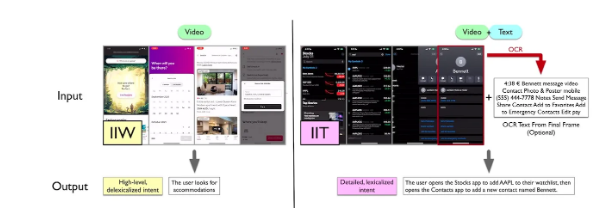
Beispielbildquelle für den IIT- und IIW-Datensatz von UI-JEPA: arXiv
Um die Forschung zum UI-Verständnis weiter voranzutreiben, führen Forscher zwei neue multimodale Datensätze und Benchmarks ein: „Intentions in the Wild“ (IIW) und „Intentions in the Tame“ (IIT). IIW erfasst offene UI-Aktionssequenzen mit unklarer Benutzerabsicht, während IIT sich auf allgemeine Aufgaben mit klarerer Absicht konzentriert.
Die Bewertung der Leistung von UI-JEPA bei neuen Benchmarks zeigt, dass es andere Video-Encoder-Modelle in der Einstellung mit wenigen Aufnahmen übertrifft und eine vergleichbare Leistung wie größere geschlossene Modelle erzielt. Die Forscher fanden heraus, dass die Zusammenführung von aus der Benutzeroberfläche extrahiertem Text mithilfe der optischen Zeichenerkennung (OCR) die Leistung von UI-JEPA weiter verbesserte.
Zu den möglichen Einsatzmöglichkeiten des UI-JEPA-Modells gehören die Erstellung automatisierter Feedbackschleifen für KI-Agenten, die es ihnen ermöglichen, ohne menschliches Eingreifen kontinuierlich aus Interaktionen zu lernen, und die Integration von UI-JEPA in Anwendungen, die darauf ausgelegt sind, Benutzerabsichten über verschiedene Anwendungen und Modi im Agentur-Framework hinweg zu verfolgen .
Das UI-JEPA-Modell von Apple scheint gut zu Apple Intelligence zu passen, einer Suite leichter generativer KI-Tools, die Apple-Geräte intelligenter und effizienter machen sollen. Angesichts des Fokus von Apple auf den Datenschutz könnten die geringen Kosten und die zusätzliche Effizienz des UI-JEPA-Modells seinem KI-Assistenten einen Vorteil gegenüber anderen Assistenten verschaffen, die auf Cloud-Modellen basieren.
Das Aufkommen von UI-JEPA hat neue Möglichkeiten für leichtgewichtige geräteseitige KI-Anwendungen eröffnet. Seine Vorteile beim Schutz der Privatsphäre und bei der effizienten Datenverarbeitung geben ihm breite Anwendungsaussichten in der zukünftigen KI-Entwicklung und verdienen anhaltende Aufmerksamkeit.