In jüngster Zeit hat das Open-Source-KI-Modell Reflection70B aufgrund seiner Leistungskontroverse große Aufmerksamkeit in der Branche auf sich gezogen. Das Modell wurde von HyperWrite veröffentlicht, das ursprünglich behauptete, es sei das weltweit leistungsstärkste Open-Source-Modell und erregte aufgrund seiner hervorragenden Leistung in Tests Dritter viel Aufmerksamkeit. Einige unabhängige Institutionen und Benutzer stellten jedoch später die Leistung in Frage, und die Testergebnisse unterschieden sich erheblich von den ursprünglichen Behauptungen von HyperWrite.
Das gerade vorgestellte Open-Source-KI-Modell Reflection70B wurde in der Branche zuletzt stark in Frage gestellt.
Dieses vom New Yorker Startup HyperWrite veröffentlichte Modell, das angeblich die Llama3.1-Variante von Meta ist, hat aufgrund seiner hervorragenden Leistung in Tests Dritter Aufmerksamkeit erregt. Als jedoch einige Testergebnisse veröffentlicht wurden, geriet der Ruf von Reflection70B in Frage.
Der Grund für die Angelegenheit war, dass Matt Shumer, Mitbegründer und CEO von HyperWrite, Reflection70B am 6. September auf Social Media X ankündigte und es selbstbewusst als „das stärkste Open-Source-Modell der Welt“ bezeichnete.
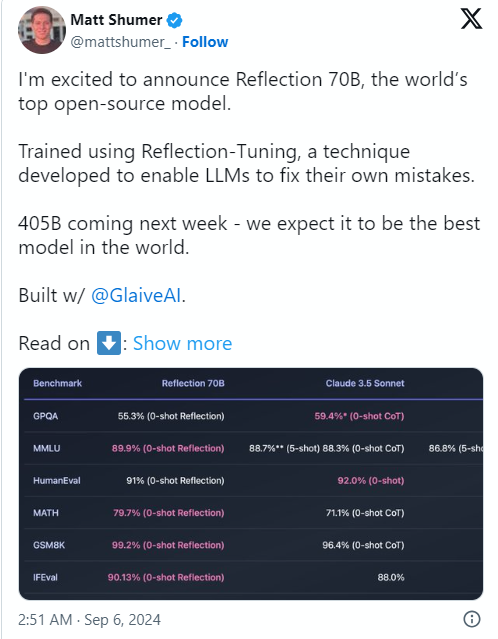
Shumer berichtete auch über die „Reflective Tuning“-Technologie des Modells und behauptete, dass diese Methode es dem Modell ermöglicht, sich selbst zu überprüfen, bevor es Inhalte generiert, und so die Genauigkeit verbessert.
Am Tag nach der Ankündigung von HyperWrite veröffentlichte Artificial Analysis, eine Gruppe, die sich auf „unabhängige Analysen von KI-Modellen und Hosting-Anbietern“ spezialisiert hat, jedoch ihre eigene Analyse auf ist das gleiche wie Llama370B, aber deutlich niedriger als Metas Llama3.170B, was einen erheblichen Unterschied zu den ursprünglich von HyperWrite/Shumer veröffentlichten Ergebnissen darstellt.
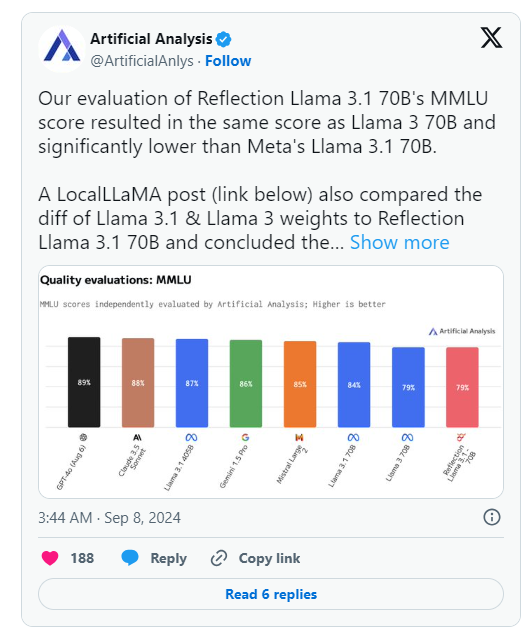
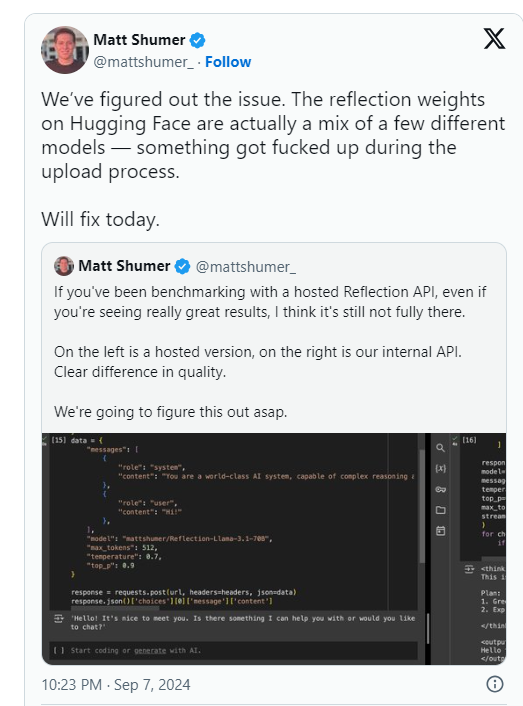
Shumer gab später an, dass beim Hochladen auf Hugging Face (ein Drittanbieter-Repository und Unternehmen für AI-Code-Hosting) ein Problem mit den Gewichtungen (oder Einstellungen für das Open-Source-Modell) von Reflection70B aufgetreten sei, was möglicherweise zu einer schlechteren Leistung als die „interne API“ von HyperWrite geführt habe " Version. .
Artificial Analysis sagte in einer nachfolgenden Erklärung, dass sie Zugriff auf die private API erhalten und eine beeindruckende Leistung gesehen hätten, jedoch nicht auf dem ursprünglich angegebenen Niveau. Da dieser Test auf einer privaten API durchgeführt wurde, konnten sie nicht unabhängig überprüfen, was sie testeten.
Die Gruppe brachte zwei zentrale Probleme zur Sprache, die die ursprünglichen Leistungsansprüche von HyperWrite und Shumer ernsthaft in Frage stellen:
Inzwischen haben auch Benutzer in mehreren Communitys für maschinelles Lernen und KI auf Reddit die behauptete Leistung und Herkunft von Reflection70B in Frage gestellt. Einige haben darauf hingewiesen , dass Reflection70B eine Variante von Llama3 und nicht von Llama-3.1 zu sein scheint , basierend auf einem Modellvergleich, der von einem Dritten auf Github veröffentlicht wurde, was weitere Zweifel an den ursprünglichen Behauptungen von Shumer und HyperWrite aufkommen lässt.
Dies führte dazu, dass mindestens ein X-Benutzer, Shin Megami Boson, am 8. September ET postete
Um 20:07 Uhr EDT beschuldigte Shumer öffentlich „betrügerisches Verhalten“ in der KI-Forschungsgemeinschaft und veröffentlichte eine lange Liste von Screenshots und anderen Beweisen.
Andere haben behauptet, dass es sich bei dem Modell tatsächlich um einen „Wrapper“ oder eine Anwendung handelt, die auf dem proprietären/Closed-Source-Konkurrenten Claude3 von Anthropic aufbaut.
Allerdings haben andere
Derzeit wartet die KI-Forschungsgemeinschaft auf Shumers Antwort auf diese Betrugsvorwürfe und aktualisierte Modellgewichte auf Hugging Face.
Nach der Veröffentlichung des Reflection70B-Modells wurde die Leistung in Frage gestellt, da die Testergebnisse die ursprünglichen Behauptungen nicht widerspiegelten.
⚙️ Der Gründer von HyperWrite erklärte, dass Probleme beim Hochladen von Modellen zu Leistungseinbußen führten, und forderte die Aufmerksamkeit auf die aktualisierte Version.
Das Modell wurde in den sozialen Medien heftig diskutiert, wobei sich Vorwürfe und Verteidigungen mischten.
Derzeit gärt der Reflection70B-Vorfall noch weiter, und das Endergebnis muss noch auf weitere Untersuchungen und Reaktionen warten. Dieser Vorfall erinnert uns auch daran, dass wir bei der Leistungssteigerung eines KI-Modells vorsichtig sein und uns bei der Beurteilung auf unabhängige Verifizierungsergebnisse verlassen sollten.