Moore Thread hat sein großes Audio-Verständnismodell MooER als Open-Source-Lösung bereitgestellt. Dabei handelt es sich um das erste große Open-Source-Sprachmodell der Branche, das auf inländischem GPU-Training und Inferenz mit vollem Funktionsumfang basiert, was einen Meilenstein darstellt. MooER unterstützt die Spracherkennung in Chinesisch und Englisch sowie die Lautübersetzung Chinesisch-Englisch und demonstriert damit leistungsstarke mehrsprachige Verarbeitungsfähigkeiten. Seine innovative dreiteilige Modellstruktur (Encoder, Adapter und Decoder) ermöglicht es dem Modell, Audio effizient zu verarbeiten und nachgelagerte Aufgaben auszuführen. Derzeit sind der Inferenzcode und das auf 5.000 Stunden Daten trainierte Modell Open Source. In Zukunft werden der Trainingscode und das auf 80.000 Stunden Daten trainierte erweiterte Modell Open Source sein, was die Entwicklung erheblich vorantreiben wird der Audio-KI-Technologie im In- und Ausland.
MooER schnitt in Vergleichstests mehrerer bekannter Open-Source-Audioverständnis-Großmodelle gut ab, mit einer chinesischen Wortfehlerrate (CER) von nur 4,21 % und einer englischen Wortfehlerrate (WER) von 17,98 %, insbesondere BLEU auf Chinesisch - Der Testsatz für die englische Übersetzung liegt bei bis zu 25,2 und liegt damit an der Spitze anderer Open-Source-Modelle. Das auf 80.000 Stunden Daten trainierte MooER-80k-Modell weist eine stärkere Leistung auf, wobei CER und WER auf 3,50 % bzw. 12,66 % reduziert wurden, was großes Potenzial zeigt. Dieser Schritt von Moore Thread zeigt nicht nur die starke Stärke heimischer GPUs im KI-Bereich, sondern verleiht auch der Entwicklung der globalen Audio-KI-Technologie neue Dynamik. Es wird erwartet, dass MooER in Zukunft weitere Durchbrüche bringen wird.
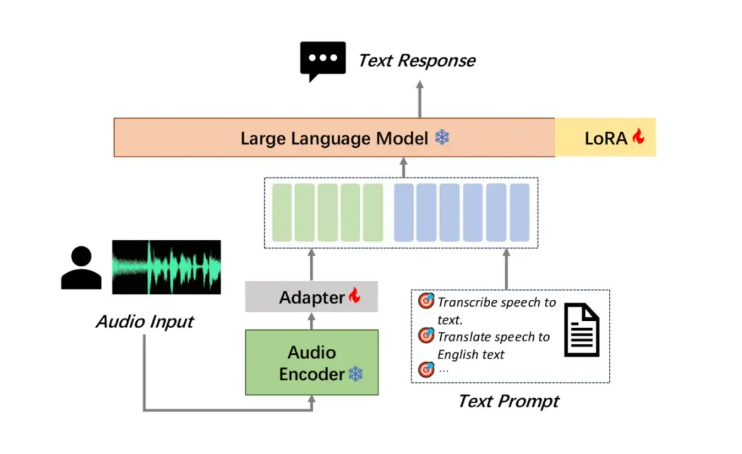
In Vergleichstests mit mehreren bekannten Open-Source-Audio-verstehenden großen Modellen schnitt MooER-5K hervorragend ab. Im chinesischen Test erreichte die Wortfehlerrate (CER) 4,21 %, im englischen Test lag die Wortfehlerrate (WER) bei 17,98 %, was besser oder gleichwertig mit anderen Spitzenmodellen ist. Besonders hervorzuheben ist, dass der BLEU-Wert von MooER beim Covost2zh2en-Übersetzungstestset Chinesisch-Englisch bis zu 25,2 beträgt, deutlich vor anderen Open-Source-Modellen liegt und ein Niveau erreicht, das mit Anwendungen auf industrieller Ebene vergleichbar ist.
Noch aufregender ist, dass das auf 80.000 Stunden Daten trainierte MooER-80k-Modell eine stärkere Leistung zeigt. Der CER des chinesischen Testsatzes sank weiter auf 3,50 % und der WER des englischen Testsatzes wurde ebenfalls auf 12,66 optimiert %. Zeigt großes Entwicklungspotenzial.
Das Open-Source-MooER von Moore Thread demonstriert nicht nur die Anwendungsstärke inländischer GPUs im KI-Bereich, sondern verleiht der Entwicklung der globalen Audio-KI-Technologie auch neue Dynamik. Da immer mehr Trainingsdaten und Codes Open Source werden, erwartet die Branche, dass MooER weitere Durchbrüche in der Spracherkennung, Übersetzung und anderen Bereichen bringen und die Popularisierung und innovative Anwendung der Audio-KI-Technologie fördern wird.
Adresse: https://arxiv.org/pdf/2408.05101
Die Open Source von MooER zeigt, dass inländische GPUs im Bereich großer KI-Modelle erhebliche Fortschritte gemacht haben und wertvolle Ressourcen und Plattformen für in- und ausländische Entwickler bereitstellen. Es wird erwartet, dass MooER in Zukunft in weiteren Anwendungsszenarien eine Rolle spielen und die kontinuierliche Innovation und Entwicklung der Audio-KI-Technologie fördern kann.