Alibabas neuestes multimodales Allzweck-Großmodell mPLUG-Owl3 hat mit seinen leistungsstarken multimodalen Verständnisfähigkeiten und seiner erstaunlichen Argumentationseffizienz einen Sturm auf dem Gebiet der künstlichen Intelligenz ausgelöst. Es kann 2 Stunden Videoinhalt in 4 Sekunden verstehen und verschiedene von Benutzern gestellte Fragen genau beantworten und zeigt eine hervorragende Leistung beim Bild-, Video- und Textverständnis. Dieser technologische Durchbruch ist nicht nur ein Meilenstein in der Wissenschaft, sondern kündigt auch eine zukünftige Veränderung in der Art und Weise an, wie KI mit Menschen interagiert.
In dieser Zeit der Informationsexplosion nutzen wir Bilder und Videos, um unser Leben festzuhalten und unser Glück jeden Tag zu teilen. Aber haben Sie jemals darüber nachgedacht, was passieren würde, wenn es eine Technologie gäbe, die es Maschinen ermöglicht, diese Bilder und Videos nicht nur wie Menschen zu verstehen, sondern auch tiefgreifend mit uns zu kommunizieren?
Das neueste vom Alibaba-Team veröffentlichte multimodale Großmodell mPLUG-Owl3 ermöglicht es uns mit seiner erstaunlichen Effizienz und Verständnisfähigkeit, einen 2-stündigen Film in 4 Sekunden anzusehen. Dies ist nicht nur ein Modell, sondern eher so! Es handelt sich um einen KI-Assistenten, der sehen, zuhören, sprechen und denken kann.
mPLUG-Owl3, der Name klingt wie eine Eule mit Brille, klug und wachsam. Seine Kernkompetenz ist das Verständnis langer Bildsequenzen. Ob es sich um eine Fotoserie oder ein Video handelt, es kann den Inhalt und sogar die Handlung verstehen.
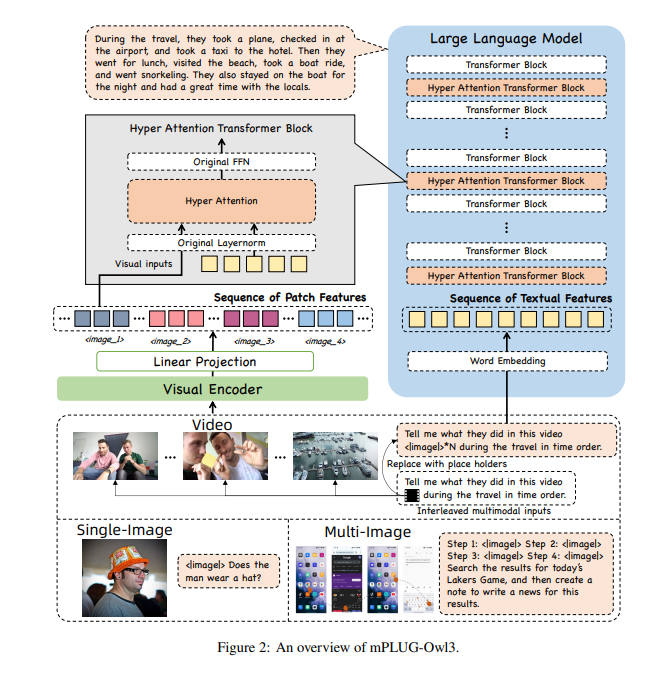
Damit mPLUG-Owl3 so viele Informationen verarbeiten kann, haben die Forscher es mit einem Super-Gehirn-Hyper-Aufmerksamkeits-Modul ausgestattet. Dieses Modul ist wie ein Supergehirn für die KI, das in der Lage ist, visuelle und sprachliche Informationen gleichzeitig zu verarbeiten, sodass die KI sowohl Bilder als auch zugehörige Textinformationen verstehen kann.
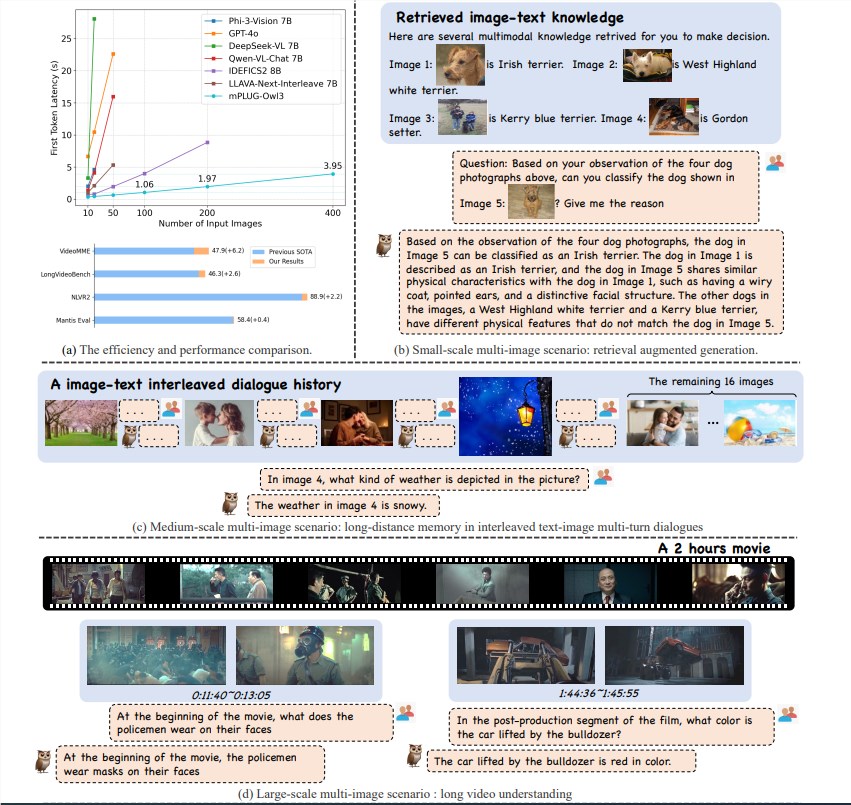
Das mPLUG-Owl3-Modell hat mit seiner hervorragenden Argumentationseffizienz einen großen Durchbruch im Bereich des multimodalen Verständnisses erzielt. Es erreicht nicht nur SOTA (State of the Art) bei Multi-Szenario-Benchmarks wie Einzelbild, Mehrbild, Video usw., sondern reduziert auch die Latenz des ersten Tokens um das Sechsfache und die Anzahl der Bilder, die verarbeitet werden können mit einer einzigen A100-Grafikkarte erhöht sich um das Achtfache und erreicht 400 Blatt.
mPLUG-Owl3 kann das eingehende multimodale Wissen genau verstehen und zur Beantwortung von Fragen nutzen. Es kann Ihnen sogar sagen, auf welchem Wissensstand es sein Urteil gründet, sowie die detaillierten Grundlagen für sein Urteil.
mPLUG-Owl3 kann die inhaltlichen Beziehungen in verschiedenen Materialien richtig verstehen und tiefgreifende Überlegungen anstellen. Ob es um stilistische Unterschiede oder die Erkennung von Zeichen geht, es meistert alles problemlos.
mPLUG-Owl3 ist in der Lage, Videos mit einer Länge von bis zu 2 Stunden anzusehen und zu verstehen und kann innerhalb von 4 Sekunden mit der Beantwortung von Benutzerfragen beginnen, unabhängig davon, welchen Teil des Videos die Frage betrifft.
mPLUG-Owl3 verwendet ein leichtes Hyper-Attention-Modul, um den Transformer-Block zu einem neuen Modul zu erweitern, das die Interaktion mit Grafik- und Textfunktionen sowie die Textmodellierung ermöglicht. Dieses Design reduziert die Anzahl zusätzlich eingeführter neuer Parameter erheblich, wodurch das Modell einfacher zu trainieren ist und auch die Trainings- und Inferenzeffizienz verbessert wird.
Durch das Experimentieren mit einer Vielzahl von Datensätzen erzielt mPLUG-Owl3 SOTA-Ergebnisse bei den meisten multimodalen Einzelbild-Benchmarks. Bei Multibildauswertungen übertrifft es speziell für Multibildszenarien optimierte Modelle. Auf LongVideoBench übertraf es bestehende Modelle und zeigte seine hervorragende Fähigkeit beim Verstehen langer Videos.
Die Veröffentlichung von Alibaba mPLUG-Owl3 ist nicht nur ein Technologiesprung, sondern bietet auch neue Möglichkeiten für die Anwendung multimodaler Großmodelle. Da sich die Technologie weiter verbessert, freuen wir uns darauf, dass mPLUG-Owl3 in Zukunft weitere Überraschungen bereithält.
Papieradresse: https://arxiv.org/pdf/2408.04840
Code: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl3
Online-Erlebnis: https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
Das Aufkommen von mPLUG-Owl3 markiert eine neue Etappe in der Entwicklung der multimodalen Großmodelltechnologie. Seine effizienten Verarbeitungsfähigkeiten und genauen Verständnisfähigkeiten eröffnen breite Perspektiven für zukünftige KI-Technologieanwendungen. Ich glaube, dass mPLUG-Owl3 mit zunehmender Weiterentwicklung der Technologie mehr Komfort und Überraschungen in das Leben der Menschen bringen wird. Wir freuen uns auf weitere innovative Anwendungen auf Basis von mPLUG-Owl3.