Tencent Youtu Lab und andere Institutionen haben das erste multimodale große Sprachmodell VITA als Open-Source-Lösung bereitgestellt, das Videos, Bilder, Text und Audio gleichzeitig verarbeiten und ein reibungsloses interaktives Erlebnis bieten kann. Das Aufkommen von VITA zielt darauf ab, die Mängel bestehender groß angelegter Sprachmodelle in der chinesischen Dialektverarbeitung auszugleichen. Basierend auf dem Mixtral8×7B-Modell wird der chinesische Wortschatz erweitert und zweisprachige Anweisungen verfeinert, sodass beide die englische Sprache beherrschen und spricht fließend Chinesisch. Dies stellt für die Open-Source-Community einen bedeutenden Fortschritt im multimodalen Verständnis und in der Interaktion dar.
Kürzlich haben Forscher des Tencent Youtu Lab und anderer Institutionen das erste multimodale Open-Source-Großsprachenmodell VITA auf den Markt gebracht, das Videos, Bilder, Text und Audio gleichzeitig verarbeiten kann und dessen interaktives Erlebnis ebenfalls erstklassig ist.
Das VITA-Modell wurde entwickelt, um die Mängel großer Sprachmodelle bei der Verarbeitung chinesischer Dialekte zu beheben. Es basiert auf dem leistungsstarken Mixtral8×7B-Modell, einem erweiterten chinesischen Wortschatz und fein abgestimmten zweisprachigen Anweisungen, sodass VITA nicht nur Englisch beherrscht, sondern auch fließend Chinesisch spricht.
Hauptmerkmale:
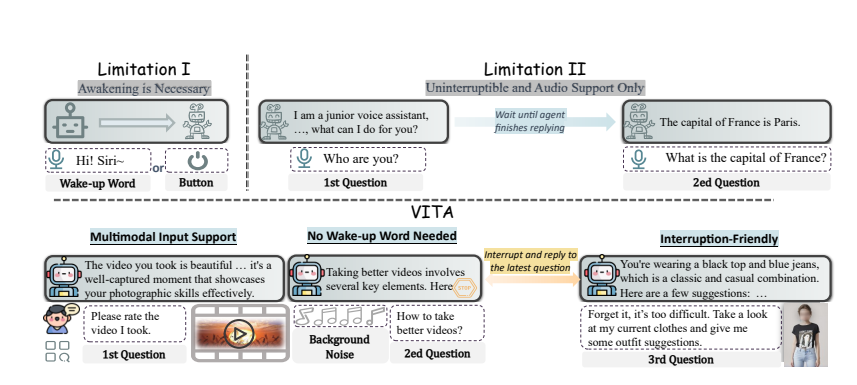
Multimodales Verständnis: Die Fähigkeit von VITA, Video, Bilder, Text und Audio zu verarbeiten, ist unter Open-Source-Modellen beispiellos.
Natürliche Interaktion: Sie müssen nicht jedes Mal „Hey, VITA“ sagen, es kann jederzeit reagieren, wenn Sie sprechen, und selbst wenn Sie mit anderen sprechen, kann es höflich bleiben und nicht nach Belieben unterbrechen.
Open-Source-Pionier: VITA ist ein wichtiger Schritt für die Open-Source-Community im multimodalen Verständnis und der Interaktion und legt den Grundstein für die nachfolgende Forschung.
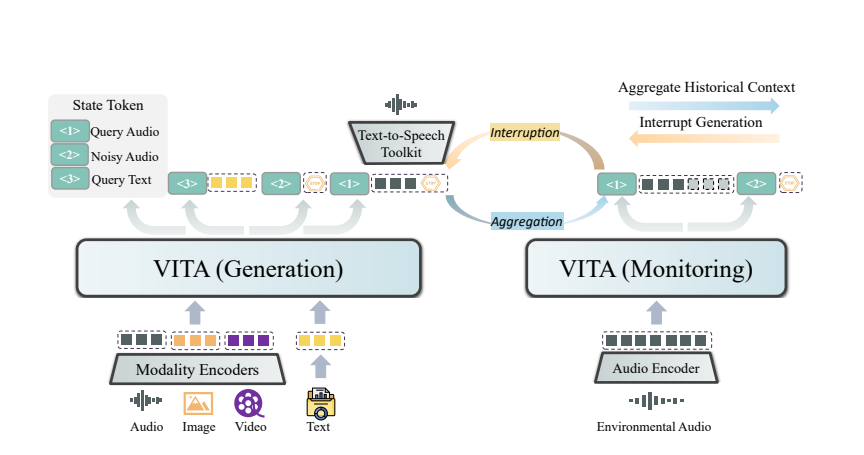
Die Magie von VITA beruht auf dem Einsatz eines dualen Modells. Ein Modell ist für die Generierung von Antworten auf Benutzeranfragen verantwortlich, und das andere Modell verfolgt kontinuierlich die Eingaben aus der Umgebung, um sicherzustellen, dass jede Interaktion korrekt und zeitnah erfolgt.
VITA kann nicht nur chatten, sondern auch als Chat-Partner fungieren, wenn Sie Sport treiben, und sogar Ratschläge geben, wenn Sie reisen. Es kann auch Fragen basierend auf den von Ihnen bereitgestellten Bildern oder Videoinhalten beantworten und zeigt so seine leistungsstarke Praktikabilität.
Obwohl VITA großes Potenzial gezeigt hat, entwickelt es sich in Bezug auf emotionale Sprachsynthese und multimodale Unterstützung immer weiter. Die Forscher planen, die nächste Generation von VITA in die Lage zu versetzen, hochwertiges Audio aus Video- und Texteingaben zu generieren und sogar die Möglichkeit zu untersuchen, gleichzeitig hochwertiges Audio und Video zu erzeugen.
Die Open Source des VITA-Modells ist nicht nur ein technischer Sieg, sondern auch eine tiefgreifende Innovation in der Art der intelligenten Interaktion. Mit der Vertiefung der Forschung haben wir Grund zu der Annahme, dass VITA uns ein intelligenteres und menschlicheres interaktives Erlebnis bieten wird.
Papieradresse: https://arxiv.org/pdf/2408.05211
Die Open Source von VITA bietet eine neue Richtung für die Entwicklung multimodaler großer Sprachmodelle. Seine leistungsstarken Funktionen und die praktische interaktive Erfahrung zeigen, dass die Mensch-Computer-Interaktion in Zukunft intelligenter und humaner sein wird. Wir freuen uns darauf, dass VITA in Zukunft größere Durchbrüche erzielen und den Menschen mehr Komfort bieten wird.