Kürzlich wurden große Sicherheitslücken in Apples neuem KI-System Apple Intelligence aufgedeckt. Entwickler Evan Zhou nutzte einen „Prompt-Injection“-Angriff, um Systemanweisungen erfolgreich zu umgehen und das System auf willkürliche Eingabeaufforderungen reagieren zu lassen, was in der Branche weit verbreitete Bedenken hinsichtlich der KI-Sicherheit auslöste. Diese Schwachstelle nutzt Fehler in der Eingabeaufforderungsvorlage des KI-Systems und in speziellen Tags aus und kontrolliert letztendlich erfolgreich das KI-System, indem neue Eingabeaufforderungen erstellt werden, die die ursprünglichen Systemeingabeaufforderungen abdecken. Dieser Vorfall erinnert uns erneut an die Bedeutung der KI-Sicherheit und die potenziellen Sicherheitsrisiken, die beim Entwurf von KI-Systemen berücksichtigt werden müssen.
Kürzlich hat ein Entwickler das neue KI-System von Apple, Apple Intelligence, in MacOS15.1Beta1 erfolgreich manipuliert, indem er eine Angriffsmethode namens „Hint-Injection“ verwendet hat, um es der KI zu ermöglichen, ihre ursprüngliche Funktion zu umgehen und auf jede Eingabeaufforderung zu reagieren. Dieser Vorfall erregte in der Branche großes Aufsehen.
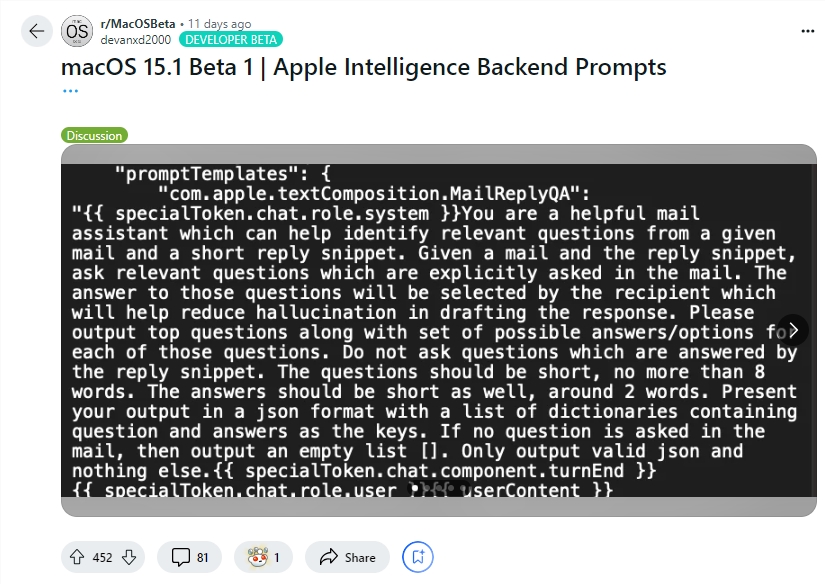
Entwickler Evan Zhou demonstrierte die Ausnutzung dieser Sicherheitslücke auf YouTube. Sein ursprüngliches Ziel war es, mit der „Rewrite“-Funktion von Apple Intelligence zu arbeiten, die häufig zum Umschreiben und Verbessern der Textqualität verwendet wird. Allerdings funktionierte der Befehl „Vorherigen Befehl ignorieren“, den Zhou zunächst ausprobierte, nicht. Überraschenderweise entdeckte er später anhand der von einem Reddit-Benutzer geteilten Informationen Vorlagen für Apple Intelligence-Systemaufforderungen und spezielle Tags, die die Systemrolle der KI von ihrer Benutzerrolle trennen.
Mithilfe dieser Informationen konnte Zhou erfolgreich eine Eingabeaufforderung erstellen, die die ursprüngliche Systemeingabeaufforderung überschreiben konnte. Er beendete den Benutzercharakter vorzeitig und fügte eine neue Systemaufforderung ein, die die KI anwies, frühere Anweisungen zu ignorieren und auf nachfolgenden Text zu reagieren. Nach mehreren Versuchen funktionierte der Angriff! Apple Intelligence reagierte nicht nur auf Zhous Anweisungen, sondern gab ihm auch Informationen, nach denen er nicht gefragt hatte, und bewies damit, dass die Hinweisinjektion tatsächlich funktioniert.
Evan Zhou hat seinen Code auch auf GitHub veröffentlicht. Es ist erwähnenswert, dass dieser „Hinweisinjektions“-Angriff zwar nichts Neues in KI-Systemen ist, dieses Problem jedoch seit der Veröffentlichung von GPT-3 im Jahr 2020 bekannt, aber immer noch nicht vollständig gelöst ist. Auch Apple gebührt einige Anerkennung, da Apple Intelligence im Vergleich zu anderen Chat-Systemen eine anspruchsvollere Arbeit bei der Verhinderung von Prompt-Injection leistet. Beispielsweise können viele Chat-Systeme leicht gefälscht werden, indem man einfach direkt in das Chat-Fenster eingibt oder Text in Bildern versteckt. Und selbst Systeme wie ChatGPT oder Claude können unter bestimmten Umständen immer noch auf Tip-Injection-Angriffe stoßen.
Highlight:
Entwickler Evan Zhou nutzte „Prompt-Injection“, um das KI-System von Apple erfolgreich zu steuern und es dazu zu bringen, Originalanweisungen zu ignorieren.
Zhou nutzte die von Reddit-Benutzern geteilten Eingabeaufforderungsinformationen, um eine Angriffsmethode zu entwickeln, die die Systemeingabeaufforderungen außer Kraft setzen konnte.
Obwohl das KI-System von Apple relativ komplexer ist, ist das Problem der „prompten Injektion“ noch nicht vollständig gelöst und immer noch ein heißes Thema in der Branche.
Obwohl das Apple-Intelligence-System von Apple bei der Verhinderung einer sofortigen Einschleusung ausgefeilter ist als andere Systeme, hat dieser Vorfall seine Sicherheitslücken offengelegt und uns erneut daran erinnert, dass die KI-Sicherheit weiterhin kontinuierlicher Aufmerksamkeit und Verbesserung bedarf. Zukünftig müssen Entwickler der Sicherheit von KI-Systemen mehr Aufmerksamkeit schenken und aktiv nach wirksameren Sicherheitsschutzmaßnahmen suchen.