Alibaba hat ein neues Open-Source-Sprachmodell Qwen2-Audio auf den Markt gebracht, das die Spracherkennung, Übersetzung und Audioanalyse deutlich verbessert hat. Seine Funktionen und Leistung übertreffen das Produkt der vorherigen Generation, Qwen-Audio, und übertreffen es sogar in mehreren Benchmark-Tests. groß-v3. Qwen2-Audio unterstützt mehrere Sprachen und bietet eine Basisversion und eine verfeinerte Version mit Anweisungen. Benutzer können per Stimme Fragen stellen und Audioinhalte erkennen und analysieren, z. B. das Alter und die Emotionen des Sprechers bestimmen oder verschiedene Geräusche analysieren Komponenten im Audio. Das Modell verwendet mehr Eingabeaufforderungen in natürlicher Sprache für das Vortraining, was das Verständnis und die Reaktionsfähigkeiten erheblich verbessert, und führt zwei Modi des Voice-Chats und der Audioanalyse ein, um die Natürlichkeit der Benutzerinteraktion zu verbessern.
Vor Kurzem hat Alibaba ein neues Open-Source-Sprachmodell namens Qwen2-Audio auf den Markt gebracht, das auf Qwen-Audio basiert. Dieses Modell schneidet nicht nur gut bei der Spracherkennung, Übersetzung und Audioanalyse ab, sondern erzielt auch deutliche Verbesserungen in Funktionalität und Leistung. Qwen2-Audio bietet eine Basisversion und eine verfeinerte Version von Anweisungen. Benutzer können dem Audiomodell per Sprache Fragen stellen und den Inhalt erkennen und analysieren.
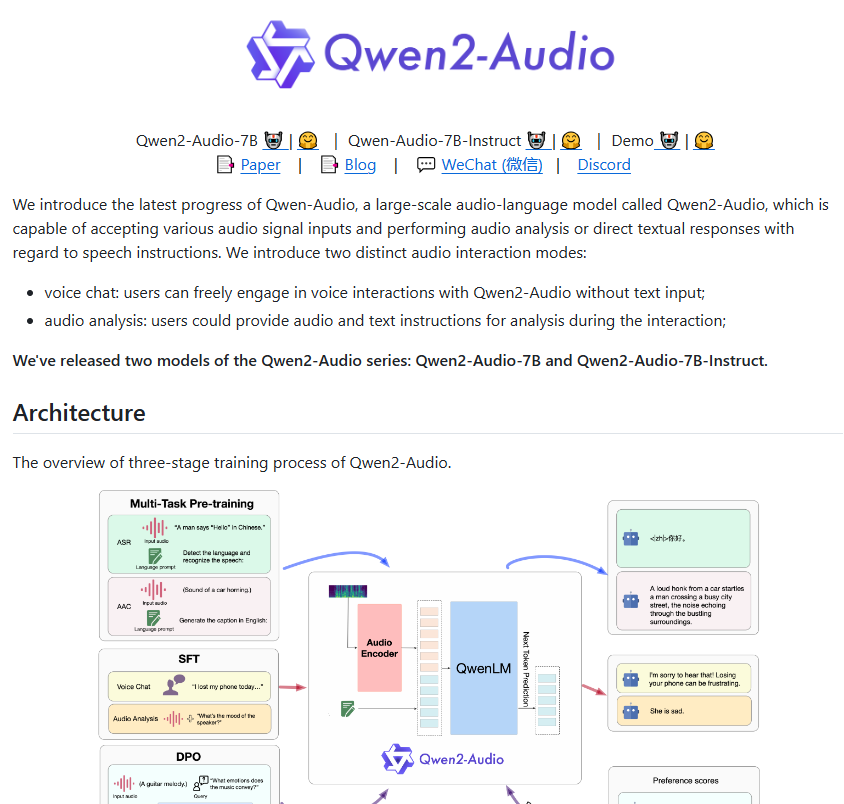
Beispielsweise kann der Benutzer eine Frau zum Sprechen auffordern und Qwen2-Audio kann ihr Alter bestimmen oder ihre Emotionen analysieren; wenn ein lauter Ton eingegeben wird, kann das Modell die verschiedenen Tonkomponenten analysieren. Qwen2-Audio unterstützt mehrere Sprachen, darunter Chinesisch, Kantonesisch, Französisch, Englisch und Japanisch, was einen großen Komfort für die Entwicklung von Stimmungsanalyse- und Übersetzungsanwendungen bietet.
Produkteingang: https://top.aibase.com/tool/qwen2-audio
Im Vergleich zum Qwen-Audio der ersten Generation wurde Qwen2-Audio hinsichtlich Architektur und Leistung vollständig optimiert. In der Vortrainingsphase verwendet dieses neue Modell mehr Hinweise in natürlicher Sprache, um die vorherigen komplexen hierarchischen Bezeichnungen zu ersetzen. Durch diese Verbesserung ist das Modell leichter zu verstehen und auf verschiedene Aufgaben zu reagieren. Außerdem wurde seine Generalisierungsfähigkeit erheblich verbessert.
Die Befehlsverfolgungsfähigkeit von Qwen2-Audio wurde ebenfalls erheblich verbessert und kann Benutzerbefehle genauer verstehen. Wenn der Benutzer beispielsweise den Befehl „Analysiere die emotionale Tendenz in diesem Audio“ ausgibt, kann Qwen2-Audio die im Audio enthaltene Emotion genau bestimmen. Darüber hinaus führt das Modell zwei Modi ein: Voice-Chat und Audioanalyse, wodurch die Sprachinteraktion der Benutzer natürlicher wird. Im Audioanalysemodus kann Qwen2-Audio verschiedene Audiotypen gründlich analysieren und detaillierte und genaue Analyseergebnisse liefern.
Um sicherzustellen, dass die Ausgabe des Modells den menschlichen Erwartungen entspricht, führt Qwen2-Audio außerdem fortschrittliche Technologien wie überwachte Feinabstimmung und direkte Präferenzoptimierung ein. Modelle wirken bei der Interaktion mit Menschen natürlicher und genauer.
In Bezug auf Leistungstests schnitt Qwen2-Audio in mehreren Mainstream-Benchmark-Tests gut ab, insbesondere bei der Genauigkeit der Spracherkennung und Übersetzung, und übertraf Whisper-large-v3 von OpenAI. Die Leistung dieses neuen Modells erregte nicht nur große Aufmerksamkeit in der Branche, sondern läutete auch eine neue Zukunft für die Sprachtechnologie ein.
Highlight:
Qwen2-Audio ist Alibabas neuestes Open-Source-Sprachmodell, das mehrere Sprachen unterstützt und über leistungsstarke Erkennungs- und Analysefunktionen verfügt.
Im Vergleich zur Vorgängergeneration wurde Qwen2-Audio in Leistung und Architektur erheblich optimiert und verbessert so seine Verständnis- und Reaktionsfähigkeit.
?In mehreren Leistungstests übertraf Qwen2-Audio Whisper von OpenAI und zeigte eine starke Wettbewerbsfähigkeit.
Die Open Source von Qwen2-Audio wird die Entwicklung im Bereich der Sprachtechnologie vorantreiben, Entwicklern leistungsstarke Tools zur Verfügung stellen und die Entstehung innovativerer Anwendungen fördern. Seine Vorteile in der Mehrsprachenunterstützung und Leistung machen es zu einer wichtigen Richtung für die zukünftige Entwicklung der Sprachtechnologie. Wir freuen uns auf die Anwendung von Qwen2-Audio in weiteren Szenarien.