Große Sprachmodelle (LLMs) stehen beim Verständnis langer Texte vor Herausforderungen und ihre Kontextfenstergröße schränkt ihre Verarbeitungsfähigkeiten ein. Um dieses Problem zu lösen, haben Forscher den LooGLE-Benchmark-Test entwickelt, um die Fähigkeit von LLMs zum Verständnis langer Kontexte zu bewerten. LooGLE enthält 776 ultralange Dokumente (durchschnittlich 19,3.000 Wörter), die nach 2022 veröffentlicht wurden, und 6448 Testinstanzen, die mehrere Bereiche abdecken und darauf abzielen, die Fähigkeit des Modells, lange Texte zu verstehen und zu verarbeiten, umfassender zu bewerten. Dieser Benchmark bewertet die Leistung bestehender LLMs und bietet eine wertvolle Referenz für die Entwicklung zukünftiger Modelle.
Im Bereich der Verarbeitung natürlicher Sprache war das Verständnis langer Kontexte schon immer eine Herausforderung. Obwohl große Sprachmodelle (LLMs) bei einer Vielzahl von Sprachaufgaben eine gute Leistung erbringen, sind sie bei der Verarbeitung von Text, der die Größe ihres Kontextfensters überschreitet, häufig eingeschränkt. Um diese Einschränkung zu überwinden, haben Forscher hart daran gearbeitet, die Fähigkeit von LLMs zu verbessern, lange Texte zu verstehen, was nicht nur für die akademische Forschung wichtig ist, sondern auch für reale Anwendungsszenarien, wie zum Beispiel das Verständnis langer domänenspezifischer Kenntnisse Dialoggenerierung und lange Geschichten oder Codegenerierung usw. sind ebenfalls von entscheidender Bedeutung.
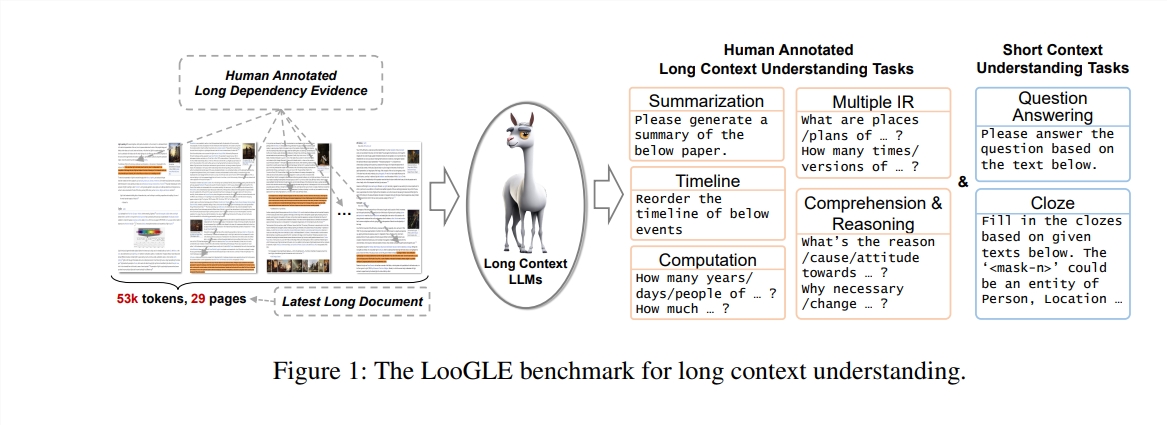
In dieser Studie schlagen die Autoren einen neuen Benchmark-Test vor – LooGLE (Long Context Generic Language Evaluation), der speziell zur Bewertung der Fähigkeit von LLMs, lange Kontexte zu verstehen, entwickelt wurde. Dieser Benchmark enthält 776 ultralange Dokumente nach 2022, jedes Dokument enthält durchschnittlich 19,3.000 Wörter und verfügt über 6448 Testinstanzen, die mehrere Bereiche abdecken, wie z. B. Wissenschaft, Geschichte, Sport, Politik, Kunst, Veranstaltungen und Unterhaltung usw.
Funktionen von LooGLE
Ultralange echte Dokumente: Die Länge von Dokumenten in ooGLE übersteigt die Kontextfenstergröße von LLMs bei weitem, was erfordert, dass sich das Modell längere Texte merken und verstehen kann.
Manuell entworfene lange und kurze Abhängigkeitsaufgaben: Der Benchmark-Test enthält 7 Hauptaufgaben, darunter kurze und lange Abhängigkeitsaufgaben, um die Fähigkeit von LLMs zu bewerten, den Inhalt langer und kurzer Abhängigkeiten zu verstehen.
Relativ neue Dokumente: Alle Dokumente wurden nach 2022 veröffentlicht, was sicherstellt, dass die meisten modernen LLMs diesen Dokumenten während der Vorschulung nicht ausgesetzt waren, was eine genauere Bewertung ihrer kontextuellen Lernfähigkeiten ermöglicht.
Domainübergreifende gemeinsame Daten: Benchmark-Daten stammen aus beliebten Open-Source-Dokumenten wie arXiv-Artikeln, Wikipedia-Artikeln, Film- und Fernsehdrehbüchern usw.
Die Forscher führten eine umfassende Bewertung von acht hochmodernen LLMs durch und die Ergebnisse brachten die folgenden wichtigen Erkenntnisse zu Tage:
Das kommerzielle Modell übertrifft das Open-Source-Modell hinsichtlich der Leistung.
LLMs schneiden bei Aufgaben mit kurzen Abhängigkeiten gut ab, stellen jedoch bei komplexeren Aufgaben mit langen Abhängigkeiten Herausforderungen dar.
Methoden, die auf Kontextlernen und Denkketten basieren, bieten nur begrenzte Verbesserungen beim Verständnis langfristiger Kontexte.
Retrieval-basierte Techniken zeigen erhebliche Vorteile bei der Beantwortung kurzer Fragen, während Strategien zur Erweiterung der Kontextfensterlänge durch optimierte Transformer-Architektur oder Positionskodierung nur begrenzte Auswirkungen auf das Verständnis langer Kontexte haben.
Der LooGLE-Benchmark bietet nicht nur ein systematisches und umfassendes Bewertungsschema zur Bewertung von Langkontext-LLMs, sondern bietet auch Leitlinien für die zukünftige Entwicklung von Modellen mit „echten Langkontextverständnis“-Fähigkeiten. Der gesamte Evaluierungscode wurde zur Referenz und Nutzung durch die Forschungsgemeinschaft auf GitHub veröffentlicht.
Papieradresse: https://arxiv.org/pdf/2311.04939
Code-Adresse: https://github.com/bigai-nlco/LooGLE
Der LooGLE-Benchmark stellt ein wichtiges Instrument zur Bewertung und Verbesserung der Langtextverständnisfähigkeiten von LLMs dar, und seine Forschungsergebnisse sind von großer Bedeutung für die Förderung der Entwicklung auf dem Gebiet der Verarbeitung natürlicher Sprache. Die von den Forschern vorgeschlagenen Verbesserungsvorschläge verdienen meiner Meinung nach Beachtung, dass in Zukunft immer leistungsfähigere LLMs erscheinen werden, um lange Texte besser verarbeiten zu können.