Apple und Meta AI haben gemeinsam eine neue Technologie namens LazyLLM auf den Markt gebracht, die die Effizienz großer Sprachmodelle (LLM) bei der Verarbeitung langer Textbegründungen deutlich verbessern soll. Wenn das aktuelle LLM lange Eingabeaufforderungen verarbeitet, steigt die Rechenkomplexität des Aufmerksamkeitsmechanismus mit dem Quadrat der Anzahl der Token, was zu einer langsamen Geschwindigkeit führt, insbesondere in der Vorladephase. LazyLLM wählt dynamisch wichtige Token für die Berechnung aus, wodurch die Anzahl der Berechnungen effektiv reduziert wird, und führt den Aux-Cache-Mechanismus ein, um bereinigte Token effizient wiederherzustellen und so die Geschwindigkeit erheblich zu erhöhen und gleichzeitig die Genauigkeit sicherzustellen.
Kürzlich haben das Apple-Forschungsteam und Meta-KI-Forscher gemeinsam eine neue Technologie namens LazyLLM auf den Markt gebracht, die die Effizienz großer Sprachmodelle (LLM) bei der Argumentation langer Texte verbessert.
Wie wir alle wissen, hat das aktuelle LLM bei der Verarbeitung langer Eingabeaufforderungen häufig Probleme mit der langsamen Geschwindigkeit, insbesondere während der Vorladephase. Dies liegt vor allem daran, dass die Rechenkomplexität moderner Transformatorarchitekturen bei der Berechnung der Aufmerksamkeit quadratisch mit der Anzahl der Token im Hinweis wächst. Daher ist bei Verwendung des Llama2-Modells die Berechnungszeit des ersten Tokens häufig 21-mal so lang wie die der nachfolgenden Decodierungsschritte, was 23 % der Generierungszeit ausmacht.
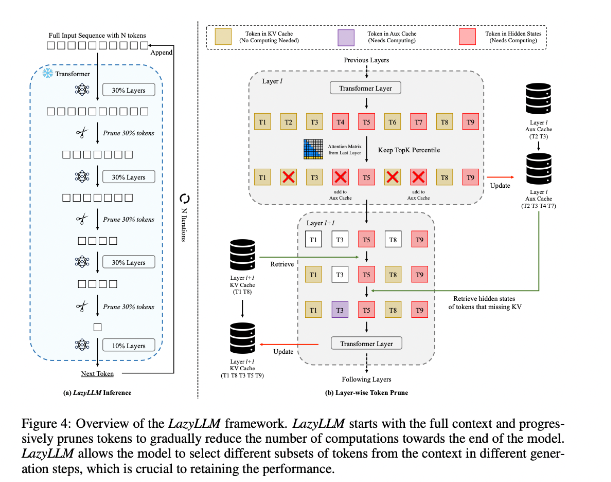
Um diese Situation zu verbessern, schlugen die Forscher LazyLLM vor, eine neue Methode zur Beschleunigung der LLM-Inferenz durch dynamische Auswahl der Berechnungsmethode wichtiger Token. Der Kern von LazyLLM besteht darin, dass es die Wichtigkeit jedes Tokens anhand der Aufmerksamkeitsbewertung der vorherigen Schicht bewertet und dadurch den Rechenaufwand schrittweise reduziert. Im Gegensatz zur permanenten Komprimierung kann LazyLLM bei Bedarf bereinigte Token wiederherstellen, um die Modellgenauigkeit sicherzustellen. Darüber hinaus führt LazyLLM einen Mechanismus namens Aux Cache ein, der den impliziten Status bereinigter Token speichern kann, um diese Token effizient wiederherzustellen und Leistungseinbußen zu verhindern.
LazyLLM zeichnet sich durch seine Inferenzgeschwindigkeit aus, insbesondere in den Phasen des Vorfüllens und Dekodierens. Die drei Hauptvorteile dieser Technik bestehen darin, dass sie mit jedem transformatorbasierten LLM kompatibel ist, keine Neuschulung des Modells während der Implementierung erfordert und eine sehr effektive Leistung bei einer Vielzahl von Sprachaufgaben erbringt. Die dynamische Bereinigungsstrategie von LazyLLM ermöglicht es, den Rechenaufwand erheblich zu reduzieren und gleichzeitig die wichtigsten Token beizubehalten, wodurch die Generierungsgeschwindigkeit erhöht wird.
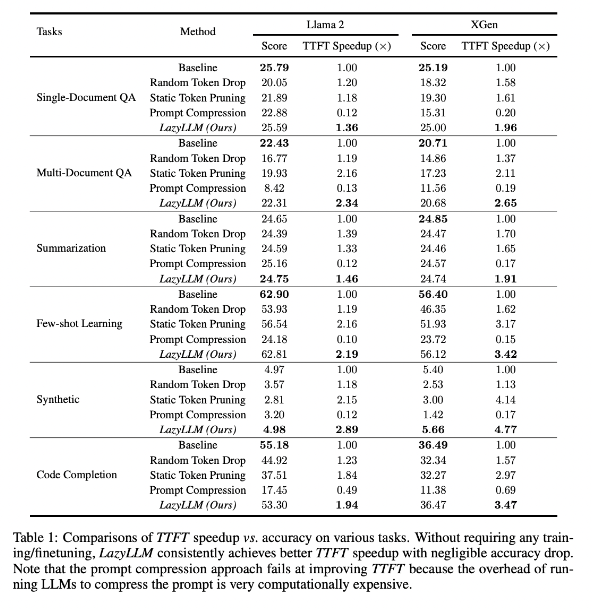
Forschungsergebnisse zeigen, dass LazyLLM bei mehreren Sprachaufgaben eine gute Leistung erbringt, wobei die TTFT-Geschwindigkeit um das 2,89-fache (für Llama2) und das 4,77-fache (für XGen) erhöht wurde, während die Genauigkeit fast der Basislinie entspricht. Unabhängig davon, ob es sich um Fragenbeantwortung, Zusammenfassungsgenerierung oder Codevervollständigungsaufgaben handelt, kann LazyLLM eine schnellere Generierungsgeschwindigkeit erreichen und ein gutes Gleichgewicht zwischen Leistung und Geschwindigkeit erreichen. Seine progressive Beschneidungsstrategie gepaart mit einer schichtweisen Analyse legt den Grundstein für den Erfolg von LazyLLM.
Papieradresse: https://arxiv.org/abs/2407.14057
Höhepunkte:
LazyLLM beschleunigt den LLM-Schlussfolgerungsprozess durch die dynamische Auswahl wichtiger Token, insbesondere in Langtextszenarien.
Diese Technologie kann die Inferenzgeschwindigkeit erheblich verbessern und die TTFT-Geschwindigkeit kann um das bis zu 4,77-fache erhöht werden, während gleichzeitig eine hohe Genauigkeit erhalten bleibt.
LazyLLM erfordert keine Änderungen an bestehenden Modellen, ist mit jedem konverterbasierten LLM kompatibel und einfach zu implementieren.
Alles in allem liefert das Aufkommen von LazyLLM neue Ideen und effektive Lösungen zur Lösung des Problems der Effizienz von LLM-Langtextbegründungen. Seine hervorragende Leistung in Bezug auf Geschwindigkeit und Genauigkeit zeigt, dass es in zukünftigen großen Modellanwendungen eine wichtige Rolle spielen wird. Diese Technologie hat breite Anwendungsaussichten und es lohnt sich, auf ihre weitere Entwicklung und Anwendung gespannt zu sein.