Apple hat zusammen mit der University of Washington und anderen Institutionen ein leistungsstarkes Sprachmodell namens DCLM als Open Source veröffentlicht, mit einer Parametergröße von 700 Millionen und einer erstaunlichen Menge an Trainingsdaten, die 2,5 Billionen Daten-Tokens erreicht. DCLM ist nicht nur ein effizientes Sprachmodell, sondern, was noch wichtiger ist, es bietet ein Tool namens „Dataset Competition“ (DataComp) zur Optimierung des Datensatzes des Sprachmodells. Diese Innovation verbessert nicht nur die Modellleistung, sondern bietet auch neue Methoden und Standards für die Sprachmodellforschung, die Aufmerksamkeit verdienen.
Kürzlich hat Apples Team für künstliche Intelligenz mit vielen Institutionen wie der University of Washington zusammengearbeitet, um ein Open-Source-Sprachmodell namens DCLM auf den Markt zu bringen. Dieses Modell verfügt über 700 Millionen Parameter und verwendet während des Trainings bis zu 2,5 Billionen Datentokens, um uns zu helfen, Sprache besser zu verstehen und zu generieren.
Was ist also ein Sprachmodell? Einfach ausgedrückt ist es ein Programm, das Sprache analysieren und generieren kann und uns dabei hilft, verschiedene Aufgaben wie Übersetzung, Textgenerierung und Stimmungsanalyse zu erledigen. Damit diese Modelle eine bessere Leistung erbringen, benötigen wir hochwertige Datensätze. Allerdings ist die Beschaffung und Organisation dieser Daten keine leichte Aufgabe, da wir irrelevante oder schädliche Inhalte herausfiltern und doppelte Informationen entfernen müssen.
Um dieser Herausforderung zu begegnen, hat das Forschungsteam von Apple DataComp for Language Models (DCLM) ins Leben gerufen, ein Tool zur Datensatzoptimierung für Sprachmodelle. Sie haben kürzlich das DCIM-Modell und den Datensatz als Open-Source-Lösung auf der Plattform Hugging Face bereitgestellt. Zu den Open-Source-Versionen gehören DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 und dclm-baseline-1.0-parquet. Forscher können über diese Plattform eine große Anzahl von Experimenten durchführen und die beste Lösung finden.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
Die Kernstärke von DCLM ist sein strukturierter Arbeitsablauf. Forscher können je nach Bedarf Modelle unterschiedlicher Größe auswählen, die von 412 Millionen bis 700 Millionen Parametern reichen, und auch mit verschiedenen Datenkurationsmethoden wie Deduplizierung und Filterung experimentieren. Durch diese systematischen Experimente können Forscher die Qualität verschiedener Datensätze eindeutig beurteilen. Dies legt nicht nur den Grundstein für zukünftige Forschung, sondern hilft uns auch zu verstehen, wie wir die Modellleistung durch Verbesserung des Datensatzes verbessern können.
Beispielsweise trainierte das Forschungsteam mithilfe des von DCLM erstellten Benchmark-Datensatzes ein Sprachmodell mit 700 Millionen Parametern und erreichte im MMLU-Benchmark-Test eine 5-Schuss-Genauigkeit. Dies ist eine Verbesserung von 6,6 im Vergleich zum vorherigen höchstes Niveau und verbraucht 40 % weniger Rechenressourcen. Die Leistung des DCLM-Basismodells ist auch mit Mistral-7B-v0.3 und Llama38B vergleichbar, die deutlich mehr Rechenressourcen erfordern.
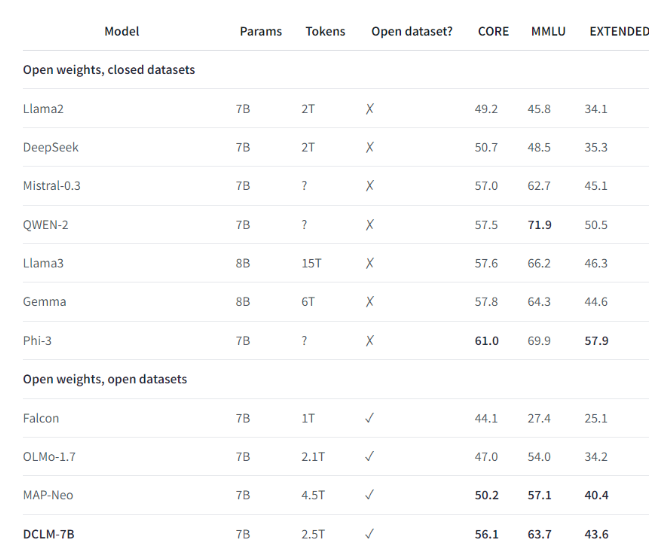
Die Einführung von DCLM stellt einen neuen Maßstab für die Sprachmodellforschung dar und hilft Wissenschaftlern, die Leistung des Modells systematisch zu verbessern und gleichzeitig die erforderlichen Rechenressourcen zu reduzieren.
Höhepunkte:
1️⃣ Apple AI hat mit mehreren Institutionen zusammengearbeitet, um DCLM auf den Markt zu bringen und so ein leistungsstarkes Open-Source-Sprachmodell zu schaffen.
2️⃣ DCLM bietet standardisierte Tools zur Datensatzoptimierung, um Forschern bei der Durchführung effektiver Experimente zu helfen.
3️⃣ Das neue Modell macht bei wichtigen Tests erhebliche Fortschritte und reduziert gleichzeitig den Bedarf an Rechenressourcen.
Alles in allem hat DCLMs Open Source dem Bereich der Sprachmodellforschung neue Dynamik verliehen, und seine effizienten Tools zur Modell- und Datensatzoptimierung sollen eine schnellere Entwicklung auf diesem Gebiet und die Entstehung leistungsfähigerer und effizienterer Sprachmodelle fördern. Wir erwarten, dass DCLM in Zukunft weitere überraschende Forschungsergebnisse liefern wird.