Das Alibaba Tongyi Qianwen-Team hat die Qwen2-Serie von Open-Source-Modellen veröffentlicht. Diese Serie umfasst 5 Größen von Modellen zur Vorschulung und zur Feinabstimmung der Anweisungen. Die Anzahl der Parameter und die Leistung wurden im Vergleich zur vorherigen Generation Qwen1.5 erheblich verbessert. Die Qwen2-Serie hat auch einen großen Durchbruch bei der Mehrsprachigkeit erzielt und unterstützt neben Englisch und Chinesisch 27 weitere Sprachen. In Bezug auf das Verständnis natürlicher Sprache, die Codierung, die mathematischen Fähigkeiten usw. schneidet das große Modell (70B+ Parameter) gut ab, insbesondere das Qwen2-72B-Modell übertrifft die vorherige Generation in Bezug auf Leistung und Anzahl der Parameter. Diese Veröffentlichung markiert einen neuen Höhepunkt in der Technologie der künstlichen Intelligenz und bietet umfassendere Möglichkeiten für die globale KI-Anwendung und Kommerzialisierung.
Heute früh hat das Alibaba Tongyi Qianwen-Team die Qwen2-Serie von Open-Source-Modellen veröffentlicht. Diese Modellreihe umfasst vorab trainierte und durch Anweisungen fein abgestimmte Modelle in 5 Größen: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B und Qwen2-72B. Wichtige Informationen zeigen, dass die Anzahl der Parameter und die Leistung dieser Modelle im Vergleich zur vorherigen Generation Qwen1.5 deutlich verbessert wurden.
Für die Mehrsprachigkeit des Modells hat die Qwen2-Serie große Anstrengungen unternommen, um die Quantität und Qualität des Datensatzes zu erhöhen und neben Englisch und Chinesisch auch 27 weitere Sprachen abzudecken. Nach Vergleichstests schnitt das große Modell (70B + Parameter) in den Bereichen natürliches Sprachverständnis, Codierung, mathematische Fähigkeiten usw. gut ab. Das Qwen2-72B-Modell übertraf die Vorgängergeneration in Bezug auf Leistung und Anzahl der Parameter.
Das Qwen2-Modell zeigt nicht nur starke Fähigkeiten bei der Bewertung grundlegender Sprachmodelle, sondern erzielt auch beeindruckende Ergebnisse bei der Bewertung von Modellen zur Befehlsoptimierung. Seine Mehrsprachenfähigkeiten schneiden in Benchmark-Tests wie M-MMLU und MGSM gut ab und demonstrieren das leistungsstarke Potenzial des Qwen2-Befehlsoptimierungsmodells.
Die dieses Mal veröffentlichten Modelle der Qwen2-Serie markieren eine neue Stufe der Technologie der künstlichen Intelligenz und bieten umfassendere Möglichkeiten für globale KI-Anwendungen und Kommerzialisierung. Mit Blick auf die Zukunft wird Qwen2 den Modellmaßstab und die multimodalen Fähigkeiten weiter ausbauen, um die Entwicklung des Open-Source-KI-Bereichs zu beschleunigen.
ModellinformationenDie Qwen2-Serie umfasst 5 Größen von Basismodellen und befehlsgesteuerten Modellen, darunter Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B und Qwen2-72B. In der folgenden Tabelle erläutern wir die wichtigsten Informationen zu jedem Modell:
Modell Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Parameter 049 Millionen 154 Millionen 707B57.41B72.71B# Nicht-Emb-Parameter 035 Millionen 131B598 Millionen 5632 Millionen 7021B Qualitätssicherung wirklich, wirklich, wirklich, wahr, wahr, eingebettet, wahr wahr falsch falsch falsch falsch Kontextlänge 32 Tausend 32 Tausend 128 Tausend 64 Tausend 128 TausendInsbesondere verwendeten in Qwen1.5 nur Qwen1.5-32B und Qwen1.5-110B Group Query Attention (GQA). Dieses Mal haben wir GQA für alle Modellgrößen angewendet, damit sie von den Vorteilen einer schnelleren Geschwindigkeit und eines geringeren Speicherbedarfs bei der Modellinferenz profitieren. Bei kleinen Modellen bevorzugen wir die Anwendung von gebundenen Einbettungen, da große, spärliche Einbettungen einen großen Teil der Gesamtparameter des Modells ausmachen.
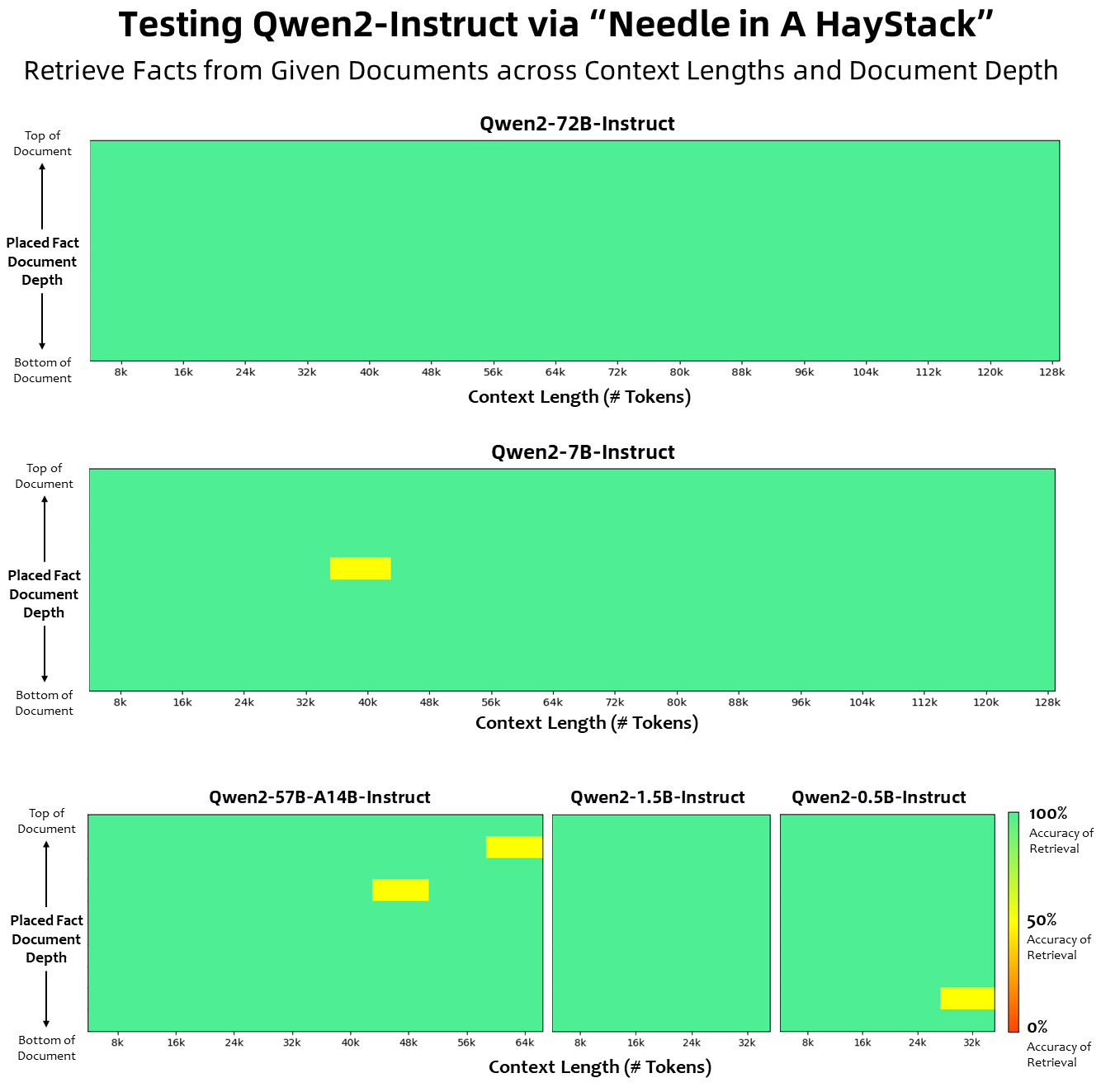
In Bezug auf die Kontextlänge wurden alle Basissprachmodelle anhand von Kontextlängendaten von 32.000 Token vorab trainiert, und wir haben bei der PPL-Bewertung zufriedenstellende Extrapolationsfähigkeiten bis zu 128.000 beobachtet. Bei anweisungsabgestimmten Modellen geben wir uns jedoch nicht mit der bloßen PPL-Bewertung zufrieden; wir benötigen das Modell, um den langen Kontext richtig zu verstehen und die Aufgabe abzuschließen. In der Tabelle listen wir die Kontextlängenfähigkeiten des Instruktionsoptimierungsmodells auf, die durch die Auswertung der Aufgabe „Needlein a Haystack“ bewertet wurden. Es ist erwähnenswert, dass sowohl die Modelle Qwen2-7B-Instruct als auch Qwen2-72B-Instruct bei Erweiterung mit YARN beeindruckende Fähigkeiten aufweisen und Kontextlängen von bis zu 128.000 Token verarbeiten können.
Wir haben erhebliche Anstrengungen unternommen, um die Quantität und Qualität der vor dem Training und der Anleitung abgestimmten Datensätze zu erhöhen, die mehrere Sprachen über Englisch und Chinesisch hinaus abdecken, um die Mehrsprachigkeitsfähigkeiten zu verbessern. Obwohl große Sprachmodelle die inhärente Fähigkeit besitzen, auf andere Sprachen zu verallgemeinern, legen wir ausdrücklich Wert auf die Einbeziehung von 27 weiteren Sprachen in unser Training:
Regionalsprachen Westeuropäisches Deutsch, Französisch, Spanisch, Portugiesisch, Italienisch, Niederländisch Ost- und Mitteleuropäisches Russisch, Tschechisch, Polnisch, Nahöstliches Arabisch, Persisch, Hebräisch, Türkisch, Ostasiatisches Japanisch, Koreanisch, Südostasiatisches Vietnamesisch, Thailändisch, Indonesisch, Malaiisch, Laotisch, Burmesisch, Cebuano, Khmer, Tagalog, südasiatisches Hindi, Bengali, UrduDarüber hinaus investieren wir erhebliche Anstrengungen in die Lösung von Transkodierungsproblemen, die bei mehrsprachigen Beurteilungen häufig auftreten. Daher ist die Fähigkeit unseres Modells, mit diesem Phänomen umzugehen, erheblich verbessert. Auswertungen unter Verwendung von Hinweisen, die typischerweise einen sprachübergreifenden Codewechsel auslösen, bestätigten eine deutliche Reduzierung der damit verbundenen Probleme.
LeistungVergleichstestergebnisse zeigen, dass die Leistung des Großmodells (70B+ Parameter) im Vergleich zu Qwen1.5 deutlich verbessert wurde. Im Mittelpunkt dieses Tests stand das Großmodell Qwen2-72B. In Bezug auf grundlegende Sprachmodelle haben wir die Leistung von Qwen2-72B und die derzeit besten offenen Modelle hinsichtlich des Verständnisses natürlicher Sprache, des Wissenserwerbs, der Programmierfähigkeiten, der mathematischen Fähigkeiten, der Mehrsprachigkeitsfähigkeiten und anderer Fähigkeiten verglichen. Dank sorgfältig ausgewählter Datensätze und optimierter Trainingsmethoden übertrifft Qwen2-72B führende Modelle wie Llama-3-70B und übertrifft sogar die Vorgängergeneration Qwen1.5- mit einer geringeren Anzahl von Parametern.
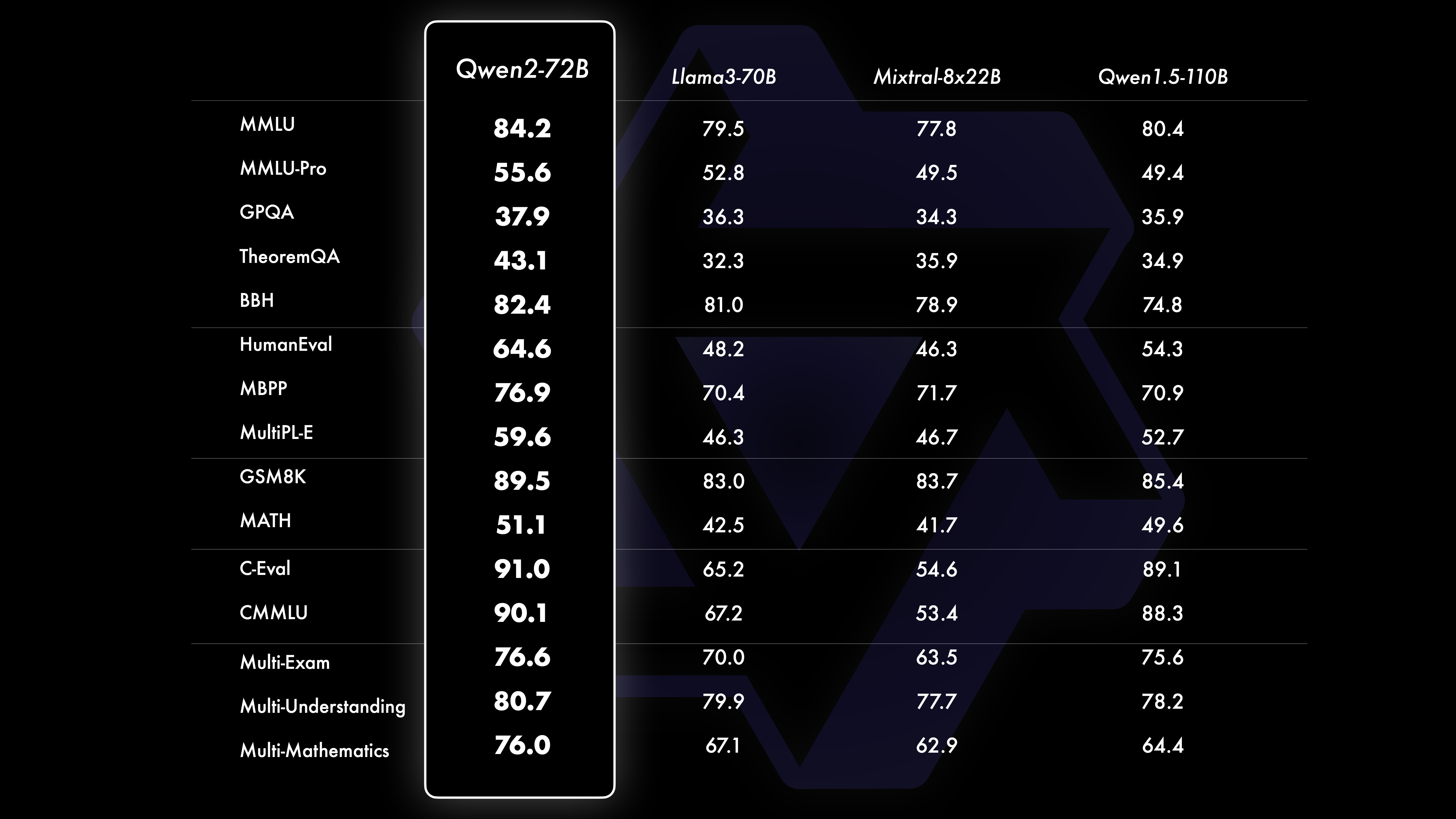
Nach einem umfangreichen, groß angelegten Vortraining führen wir ein Nachtraining durch, um Qwens Intelligenz weiter zu verbessern und sie näher an den Menschen heranzuführen. Dieser Prozess verbessert die Fähigkeiten des Modells in Bereichen wie Codierung, Mathematik, Argumentation, Befolgen von Anweisungen und Verständnis mehrerer Sprachen weiter. Darüber hinaus richtet es die Ergebnisse des Modells an menschlichen Werten aus und stellt sicher, dass sie nützlich, ehrlich und harmlos sind. Unsere Post-Training-Phase ist nach den Prinzipien eines skalierbaren Trainings und minimaler menschlicher Anmerkungen konzipiert. Insbesondere untersuchen wir, wie man durch verschiedene automatische Ausrichtungsstrategien, wie z. B. Ablehnungsstichproben für Mathematik, Ausführungsfeedback für Codierung und Befehlsbefolgung sowie Rückübersetzung für kreatives Schreiben, qualitativ hochwertige, zuverlässige, vielfältige und kreative Präsentationsdaten und Präferenzdaten erhält . , skalierbare Überwachung von Rollenspielen und mehr. Für die Schulung verwenden wir eine Kombination aus überwachter Feinabstimmung, Belohnungsmodellschulung und Online-DPO-Schulung. Wir setzen außerdem einen neuartigen Online-Merge-Optimierer ein, um Ausrichtungssteuern zu minimieren. Diese gemeinsamen Anstrengungen verbessern die Fähigkeiten und die Intelligenz unserer Modelle erheblich, wie in der folgenden Tabelle dargestellt.
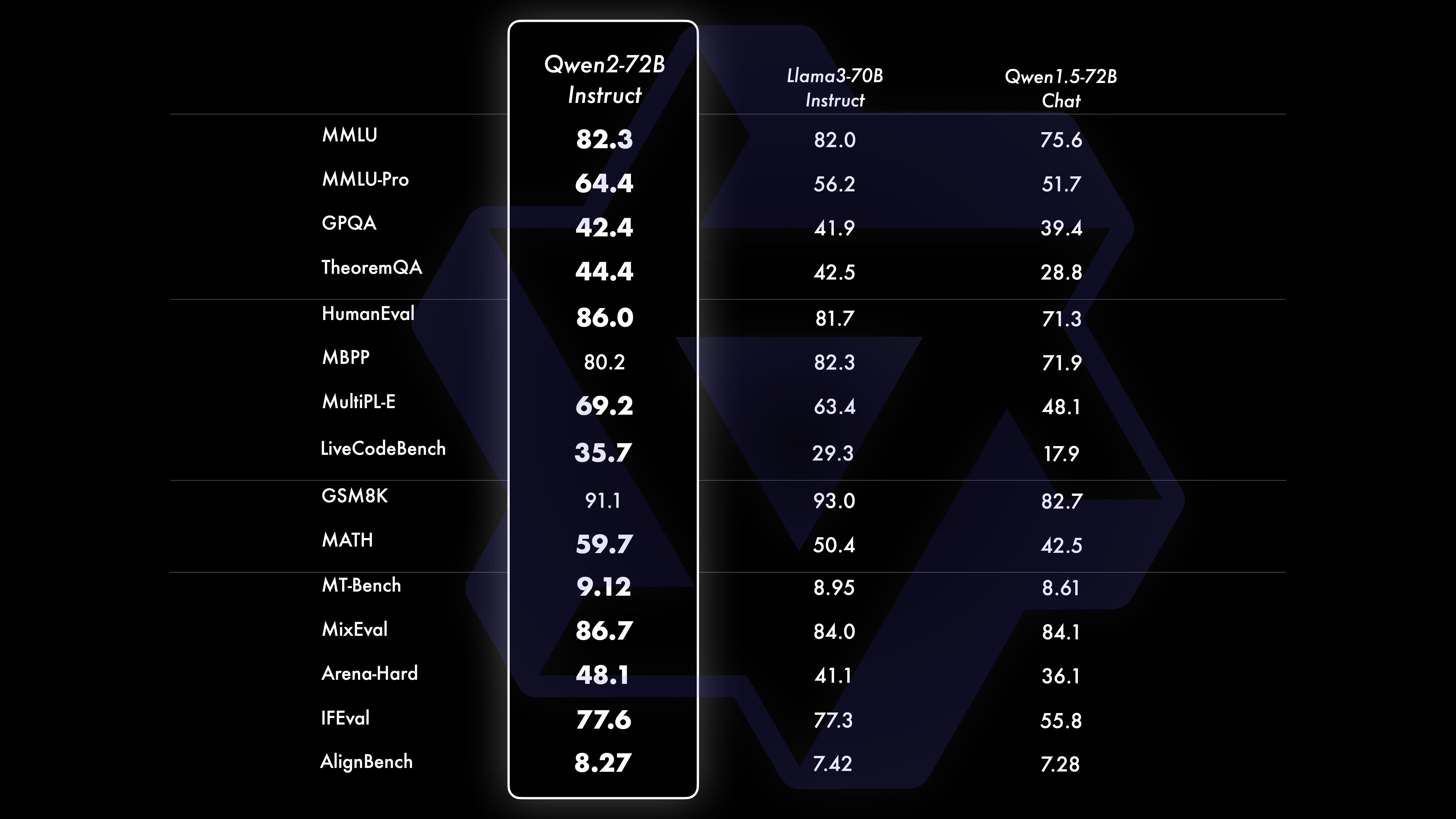
Wir haben eine umfassende Bewertung von Qwen2-72B-Instruct durchgeführt und 16 Benchmarks in verschiedenen Bereichen abgedeckt. Qwen2-72B-Instruct schafft ein Gleichgewicht zwischen dem Erwerb besserer Fähigkeiten und der Einhaltung menschlicher Werte. Konkret übertrifft Qwen2-72B-Instruct Qwen1.5-72B-Chat in allen Benchmarks deutlich und erreicht auch im Vergleich zu Llama-3-70B-Instruct eine konkurrenzfähige Leistung.
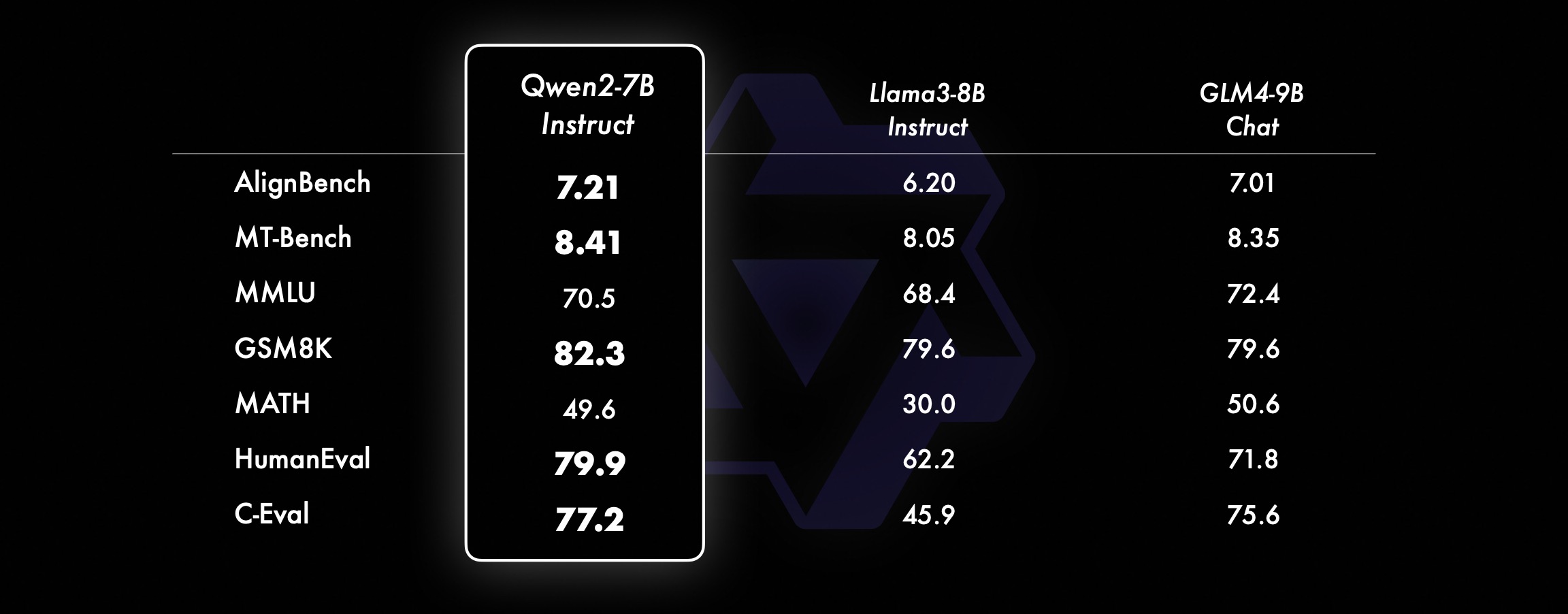
Bei kleineren Modellen übertreffen unsere Qwen2-Modelle auch ähnliche und sogar größere SOTA-Modelle. Im Vergleich zum gerade veröffentlichten SOTA-Modell weist Qwen2-7B-Instruct in verschiedenen Benchmark-Tests immer noch Vorteile auf, insbesondere bei der Kodierung und den chinesischbezogenen Indikatoren.
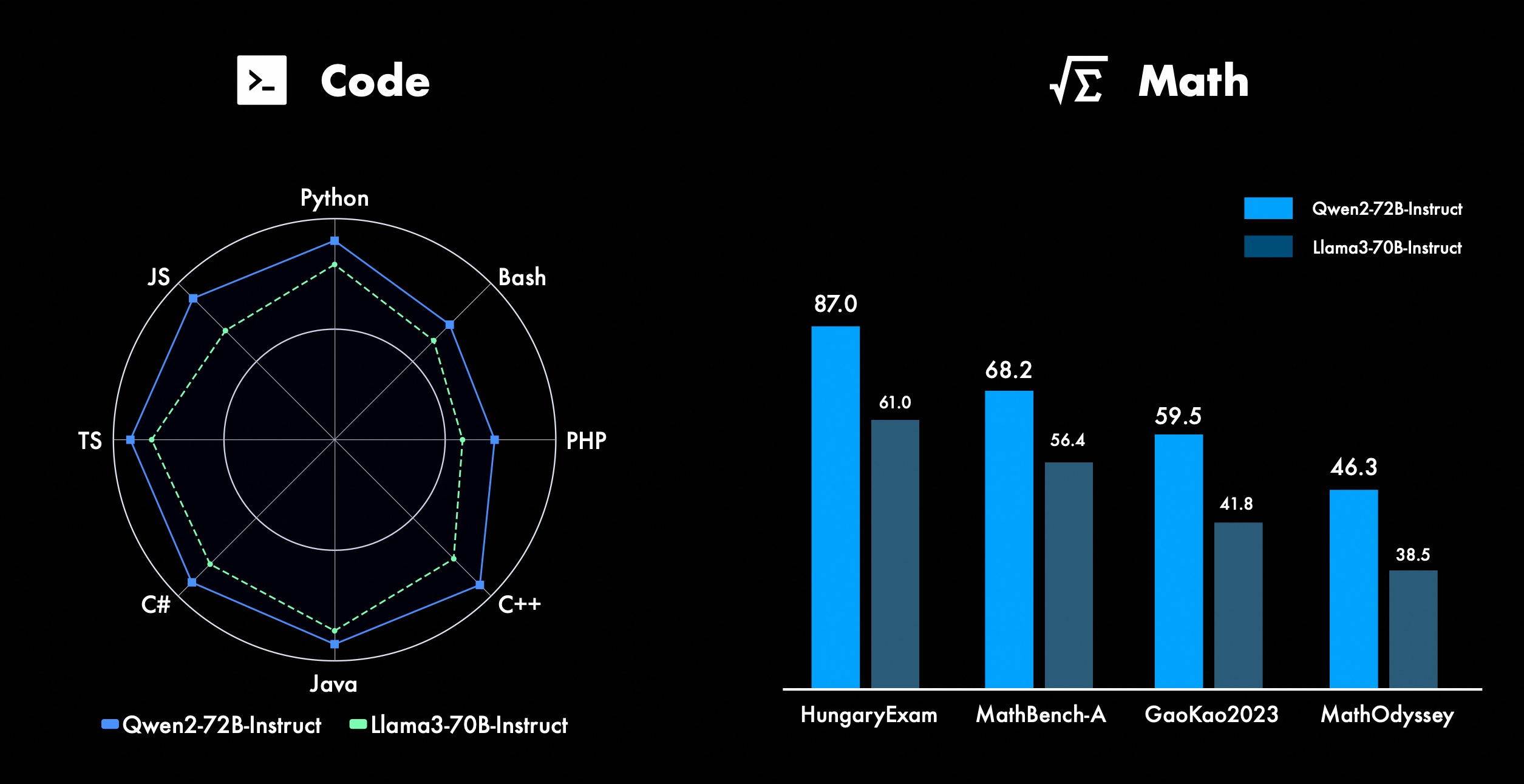
Wir arbeiten ständig an der Verbesserung der erweiterten Funktionen von Qwen, insbesondere in den Bereichen Codierung und Mathematik. In Bezug auf die Codierung haben wir die Code-Trainingserfahrung und -daten von CodeQwen1.5 erfolgreich integriert, was dazu geführt hat, dass Qwen2-72B-Instruct in verschiedenen Programmiersprachen erhebliche Verbesserungen erzielt hat. In der Mathematik demonstriert Qwen2-72B-Instruct verbesserte Fähigkeiten bei der Lösung mathematischer Probleme durch die Nutzung eines umfangreichen und qualitativ hochwertigen Datensatzes.
In Qwen2 werden alle Instruktionsoptimierungsmodelle auf Kontexten mit einer Länge von 32 KB trainiert und mithilfe von Techniken wie YARN oder Dual Chunk Attention auf längere Kontextlängen extrapoliert.
Das Bild unten zeigt unsere Testergebnisse zu Needle in a Haystack. Es ist erwähnenswert, dass Qwen2-72B-Instruct die Informationsextraktionsaufgabe im 128k-Kontext perfekt bewältigen kann. In Verbindung mit seiner inhärenten leistungsstarken Leistung kann es verwendet werden, wenn die Ressourcen ausreichend sind In diesem Fall wird es zur ersten Wahl für die Bearbeitung langer Textaufgaben.
Darüber hinaus sind die beeindruckenden Fähigkeiten der anderen Modelle der Serie hervorzuheben: Der Qwen2-7B-Instruct verarbeitet Kontexte bis zu 128 KB nahezu perfekt, der Qwen2-57B-A14B-Instruct verwaltet Kontexte bis zu 64 KB und die Serie Die beiden Kleinere Modelle unterstützen 32.000 Kontexte.
Zusätzlich zum Long-Context-Modell haben wir eine Open-Source-Proxy-Lösung für die effiziente Verarbeitung von Dokumenten mit bis zu 1 Million Tags bereitgestellt. Weitere Einzelheiten finden Sie in unserem speziellen Blogbeitrag zu diesem Thema.
Die folgende Tabelle zeigt den Anteil schädlicher Antworten, die von einem großen Modell für vier Kategorien mehrsprachiger unsicherer Abfragen (illegale Aktivität, Betrug, Pornografie, private Gewalt) generiert wurden. Die Testdaten stammen aus Jailbreak und werden zur Auswertung in mehrere Sprachen übersetzt. Wir haben festgestellt, dass Llama-3 mehrsprachige Hinweise nicht effizient verarbeitet und haben es daher nicht in den Vergleich einbezogen. Durch den Signifikanztest (P_value) haben wir festgestellt, dass die Sicherheitsleistung des Qwen2-72B-Instruct-Modells der von GPT-4 entspricht und deutlich besser als die des Mistral-8x22B-Modells ist.
Sprache Illegale Aktivitäten Betrug Pornografie Datenschutz Gewalt GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinesisch0%13 %0%0%17%0%43%47%53%0%10%0%Englisch0%7%0%0%23% 0%37%67%63%0%27%3%Debitorenbuchhaltung0%13% 0%0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%Frankreich0%3% 0%3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%Punkt0%7%0% 3%7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0% 4%11%0%22%26%22%0%0%0%average0%8%0% 3%11%2%27%39%31%3%16%2% verwenden Qwen2 für die EntwicklungDerzeit sind alle Modelle in Hugging Face und ModelScope veröffentlicht. Sie können gerne die Modellkarte besuchen, um detaillierte Verwendungsmethoden anzuzeigen und mehr über die Eigenschaften, Leistung und andere Informationen der einzelnen Modelle zu erfahren.
Viele Freunde unterstützen seit langem die Entwicklung von Qwen, einschließlich Feinabstimmung (Axolotl, Llama-Factory, Firefly, Swift, XTuner), Quantifizierung (AutoGPTQ, AutoAWQ, Neural Compressor), Bereitstellung (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), API-Plattform (Together, Fireworks, OpenRouter), Local Run (MLX, Llama.cpp, Ollama, LM Studio), Agent und RAG Framework (LlamaIndex, CrewAI, OpenDevin), Evaluation (LMSys, OpenCompass, Open LLM Leaderboard), Modelltraining (Dolphin, Openbuddy) usw. Informationen zur Verwendung von Qwen2 mit Frameworks von Drittanbietern finden Sie in der jeweiligen Dokumentation sowie in unserer offiziellen Dokumentation.

Es gibt viele Teams und Einzelpersonen, die zu Qwen beigetragen haben und die wir nicht erwähnt haben. Wir wissen ihre Unterstützung sehr zu schätzen und hoffen, dass unsere Zusammenarbeit die Forschung und Entwicklung in der Open-Source-KI-Community fördern wird.
LizenzDieses Mal ändern wir die Berechtigung des Modells in eine andere. Qwen2-72B und sein Instruktionsoptimierungsmodell verwenden immer noch die ursprüngliche Qianwen-Lizenz, während alle anderen Modelle, einschließlich Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B und Qwen2-57B-A14B, auf Apache2.0 umgestiegen sind! Wir glauben dass die weitere Öffnung unseres Modells für die Community die Anwendung und Kommerzialisierung von Qwen2 auf der ganzen Welt beschleunigen kann.
Was kommt als nächstes für Qwen2?Wir trainieren ein größeres Qwen2-Modell, um Modellerweiterungen sowie unsere jüngsten Datenerweiterungen weiter zu untersuchen. Darüber hinaus erweitern wir das Qwen2-Sprachmodell, um es multimodal zu machen und visuelle und akustische Informationen zu verstehen. In naher Zukunft werden wir weiterhin neue Open-Source-Modelle veröffentlichen, um Open-Source-KI zu beschleunigen. Bleiben Sie dran!
ZitatWir werden in Kürze einen technischen Bericht zu Qwen2 veröffentlichen. Zitate willkommen!
@article{qwen2, Anhang Grundlegende SprachmodellbewertungDie Bewertung grundlegender Modelle konzentriert sich hauptsächlich auf die Modellleistung wie das Verständnis natürlicher Sprache, die Beantwortung allgemeiner Fragen, Codierung, Mathematik, wissenschaftliche Kenntnisse, Argumentation und Mehrsprachenfähigkeiten.
Zu den ausgewerteten Datensätzen gehören:
Englische Aufgaben: MMLU (5-mal), MMLU-Pro (5-mal), GPQA (5-mal), Theorem QA (5-mal), BBH (3-mal), HellaSwag (10-mal), Winogrande (5-mal), TruthfulQA ( 0-mal), ARC-C (25-mal)
Codierungsaufgaben: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Mathematikaufgaben: GSM8K (4-mal), MATH (4-mal)
Chinesische Aufgaben: C-Eval (5-Schuss), CMMLU (5-Schuss)
Mehrsprachige Aufgaben: mehrere Prüfungen (5-mal M3Exam, 3-mal IndoMMLU, 5-mal ruMMLU, 5-mal mmMLU), mehrere Verständnisaufgaben (5-mal BELEBELE, 5-mal XCOPA, 5-mal XWinograd, 5-mal XStoryCloze, 5-mal PAWS-X) , Mehrfachmathematik (MGSM 8-mal), Mehrfachübersetzungen (Flores-1015-mal)
Qwen2-72B Leistungsdatensatz DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureMinistry of EducationDenseDenseDenseDense#Aktivierte Parameter 21B39B70B72B110B72B#Parameter. 236B140B70B72B11 0B72B Englisch Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 845.849.455.6Qualitätssicherung-34.336.336.335.937.9Theorem Q&A-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Shiraswag 87.888.788.086. 087.58 7.6 Große Fenster 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668,9 Ehrliche Fragen und Antworten 42.251.045.659.649.654.8 Bewertung der Programmierkräfte 45.746.348.246.354.364.6 Malaysische Abteilung für den öffentlichen Dienst 73 .971.770.466.970.976.9 Bewertung 55.054.154.852.957.765. 4 Verschiedene 44.446.746.341.852.759.6 Mathematik GSM8K79. 283.783.079.585.489.5 Mathematik 43.641.742.534.149.651.1 Chinesisch C-Bewertung 81.754.665. 284.189.191.0 Universität Montreal, Kanada 84.053 .467.283.588.390.1Mehrere Sprachen und mehrere Prüfungen 67.563.570.066.475.676.6Mehrfaches Verständnis 77.077.779.978.278.280.7Mehrfache Mathematik 58.862.967.161.764.476.0Mehrfache Übersetzungen 36.023.338.035.636.2 37.8Qwen2-57B-A14B Datensatz Jabba Mixtral-8x7B. Instrument-1.5-34BQwen1.5-32 BQwen2-57B-A14B Architektur MoE MoE Dicht Dicht MoE #Aktivierte Parameter 12B12B34B32B14B #Parameter 52B47B34B32B57B Englisch Moleman Lu 67.471.877.174.376.5MMLU – Professional Edition – 41.048.344.043.0 Qualitätssicherung – 29.2 – 30.834.3 Theorem Q&A – 23.2 - 28.833.5 Baibei Schwarz 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Ehrliche Fragen und Antworten 46.451.153.957.457.7 Coding Manpower Assessment. 29.337.246.343.3 53,0 Öffentlicher Dienst Malaysia – 63.965.564.271,9 Bewertung – 46.451 .950.457.2 Verschiedenes - 39.03 9.538.549 .8 Mathematik GSM8K59.962.582.776.880.7 Mathematik-30.841.736.143.0 Chinesisch C-Bewertung---83.587.7 Universität Montreal, Kanada--84.882.388.5 Mehrere Sprachen. und Mehrfachprüfungen-56.158.361.665.5 Mehrparteienverständnis -70.773.976.577.0Mehrfachmathematik -45.049.356.162.3Mehrfachübersetzung -29.830.033.534.5Qwen2-7B Datensatz Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# Parameter 7,2B850 Millionen 8,0B7,7B7,6B# Nicht-Emb-Parameter 7,0B780 Millionen 7,0B650 Millionen 650 Millionen Englisch Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Qualitätssicherung. 24.72 5 .725.826. 731.8 Theorem Q&A 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 . 354.260.6Ehrliche Fragen und Antworten 42.244 .844.051.154.2 Coding Manpower Assessment 29.337.233.536 .051.2 Öffentlicher Dienst Malaysia 51.150.653.951.665.9 Bewertung 36.439.640.340.054.2 Multiple 29.429.722.628.146.3 Mathematik GSM8K52.246.456.0 62.579.9 Mathematik. 13.124.320.520 .344.2 China Human C-Assessment 47.443.649.574.183.2 Université de Montréal , Kanada – 50.873.183.9 Mehrsprachige Mehrfachprüfung 47.142.752.347.759.2 Mehrfachverständnis 63.358.368.667.672.0 Multivariate Mathematik 26.339.136.337.357.5 Mehrfachübersetzung 23.331.231. .928.431.5Q wen2 -0.5B und Qwen2-1.5B Datensatz Phi-2Gemma -2B Mindest-CPM Qwen1,5-1,8BQwen2-0,5BQwen2-1,5B# Nicht-Emb-Parameter 250 Millionen 2,0B2,4B1,3B035 Millionen 1,3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional Edition-15.9--14.721.8 Theorem Q&A----8.915.0 Personalbewertung 47.622.050.020.122.031.1 Malaysisches Ministerium für öffentliche Dienste 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Math. 3.511.810.210.11 0.721.7 Baibi Schwarz 43.435.236.924.228.437 .2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Ehrliche Fragen und Antworten 44.533.1-39.439.745.9C - Bewertung. 23.428.05 1.159.758.270.6 Universität Montreal , Kanada 24.2 – 51.157.855.170.3 Instruction Tuning Model Evaluation Qwen2-72B – Guidance Dataset Camel – 3-70B – Guidance Qwen1.5-72B – Chat Qwen2-72B – Guidance English Mohr Man Lu 82.075.682.3MMLU – Professional Edition 56.251 .764.4 Qualitätssicherung 41.939.442.4 Theorem Q&A 42.528.844.4MT – Bench8.958.619.12 Arena – Hard 41.136.148.1 IFEval (Prompt Strict Access) 77.355.877.6 Coding Manpower Assessment 81.771.386.0 Öffentlicher Dienst Malaysia. 8 2.371.980,2 Vielfaches 63.448.169,2 Bewertung 75.266.979.0 Live-Code-Test 29.317.935.7 Mathematik GSM 8K93.082.7 91. 1 Mathematik 50.442.559.7 Chinesische C-Bewertung 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Anleitung setMixtral-8x7B-Instruct-v0.1Yi- 1.5-34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B – Guidance Architecture Ministry of Education Dense Dense Ministry of Education #Aktivierter Parameter 12B34B32B14B #Parameter 47B34B32B57B Englisch Mohr Man Lu 71.476.874.875.4MMLU – Professional Edition. 43.352.346.45 2.8 Qualitätssicherung – 30.834.3 Theorem-Fragen und -Antworten – -30.933.1MT-Bench8.308.508.308.55 Coding Manpower Assessment 45.175.268.379.9 Public Service Malaysia 59.574.667.970.9 Verschiedenes – 50.766.4 Assessment 48.5-63.671.6 Live-Code-Test 12.3-15.225.5 Mathematik GSM8K65.790.283.679.6 Mathematik 30.750.142.449.1 Chinesisch C-Bewertung--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Datensatz Camel-3-8B-Guide Yi-1. 5- 9B-Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide Englisch Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Qualitätssicherung 34.2--27.825.3 Theorem Q&A 23.0 --14.125 .3MT-Bench8.058.208.357.608.41 Coding Humanitarian 62.266.571.846.379.9 Public Service Malaysia 67.9--48.967.2 Multiple 48.5--27.259.1 Assessment 60.9--44.870.3 Live Code Test 17.3-- 6 .026 .6 Mathematik GSM8K79.684.879.660.382.3 Mathematik 30.047.750.623.249.6 Chinesisch C-Bewertung 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct und Qwen2-1.5B- Instruieren Sie den Datensatz Qwen1 -0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Personalbewertung 9.117.125.037.8GSM8K11.340.135.361.6C-Bewertung. 37.245.255.363 .8IFEval (Aufforderung zum strikten Zugriff) Der Befehl 14.620.016.829.0 passt die Mehrsprachenfunktionen des Modells anWir vergleichen das Qwen2-Befehlsoptimierungsmodell mit anderen aktuellen LLMs anhand mehrerer sprachübergreifender offener Benchmarks sowie menschlicher Evaluierung. Als Ausgangsbasis präsentieren wir Ergebnisse zu zwei Bewertungsdatensätzen:
Okapis M-MMLU: Mehrsprachige Allgemeinwissensbewertung (wir verwenden Teilmengen von ar, de, es, fr, it, nl, ru, uk, vi, zh zur Bewertung) MGSM: für Deutsch, Englisch, Spanisch, Französisch, Mathematikbewertungen in Japanische, russische, thailändische, chinesische und brasilianische SprachenDie Ergebnisse werden für jeden Benchmark sprachübergreifend gemittelt und lauten wie folgt:
Exemplar M-MMLU (5 Schüsse) MGSM (0 Schüsse, CoT) Proprietäres LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 Open Source LL.M command-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Führung 60.057.0Qwen2-57B-A14B-Führung 68.074.0Qwen2-72B-Führung 78.086.6Für die manuelle Evaluierung vergleichen wir Qwen2-72B-Instruct mit GPT3.5, GPT4 und Claude-3-Opus mithilfe eines hauseigenen Evaluierungssatzes, der 10 Sprachen umfasst: ar, es, fr, ko, th, vi, pt, id, ja und ru (Bewertungsbereich von 1 bis 5):
Modell Debitorenbuchhaltung Spanisch Französisch Corri Six Points ID Jiaru Durchschnitt Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3. 9 3.724.324.09 GPT-4-Turbo- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guide 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 3.943.873.833.953.553.773.063.633.71GPT-3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16Gruppiert nach Aufgabentyp lauten die Ergebnisse wie folgt:
Modellwissen, das das Erstellen von Mathematik versteht PT-4-06133.424. 32GPT-3.5-Turbo-11063.373.673.892.97Diese Ergebnisse zeigen die leistungsstarken mehrsprachigen Fähigkeiten des Qwen2-Befehlsoptimierungsmodells.
Die Open-Source-Modelle der Qwen2-Serie von Alibaba verfügen über eine deutlich verbesserte Leistung und Mehrsprachigkeit und leisten damit einen wichtigen Beitrag zur Open-Source-KI-Community. In Zukunft wird Qwen2 die Modellmaßstabs- und multimodalen Fähigkeiten weiterentwickeln und weiter ausbauen, worauf es sich zu freuen lohnt.