thumb
1.0.0
Une bibliothèque de tests simples et rapides pour les LLM.
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])Chaque invite est exécutée 10 fois de manière asynchrone par défaut, ce qui est environ 9 fois plus rapide que de les exécuter de manière séquentielle. Dans Jupyter Notebooks, une interface utilisateur simple s'affiche pour les réponses d'évaluation aveugle (vous ne voyez pas quelle invite a généré la réponse).
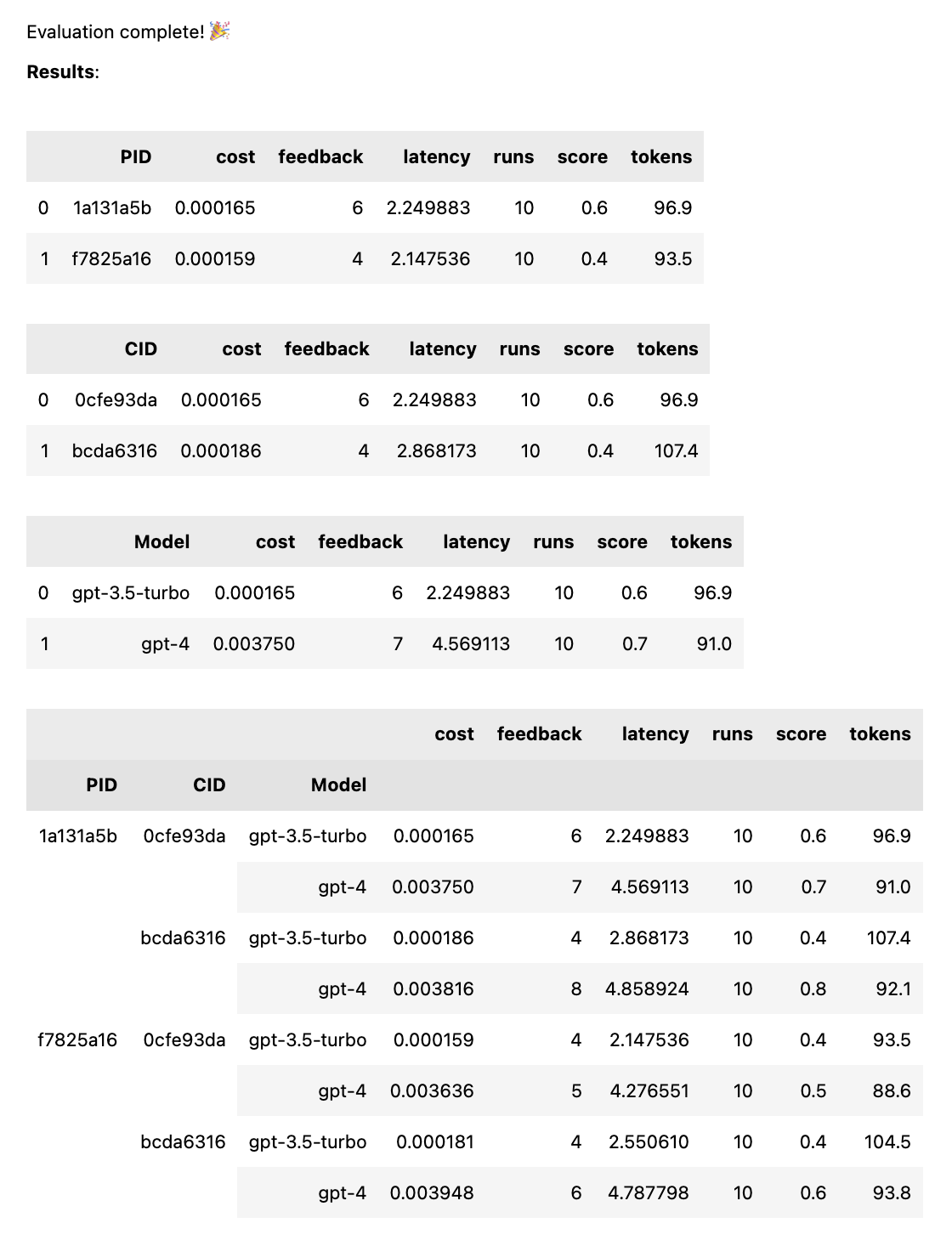
Une fois que toutes les réponses ont été notées, les statistiques de performances suivantes sont calculées, ventilées par modèle d'invite :
avg_score quantité de commentaires positifs en pourcentage de toutes les exécutionsavg_tokens : combien de jetons ont été utilisés dans l'invite et la réponseavg_cost : une estimation du coût moyen d'exécution de l'invite Un rapport simple est affiché dans le bloc-notes et les données complètes sont enregistrées dans un fichier CSV thumb/ThumbTest-{TestID}.csv .

Les cas de test permettent de tester un modèle d'invite avec différentes variables d'entrée. Par exemple, si vous souhaitez tester un modèle d'invite qui inclut une variable pour le nom d'un comédien, vous pouvez configurer des scénarios de test pour différents comédiens.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Chaque scénario de test sera exécuté sur chaque modèle d'invite, donc dans cet exemple, vous obtiendrez 6 combinaisons (3 cas de test x 2 modèles d'invite), qui s'exécuteront chacune 10 fois (60 appels au total à OpenAI). Chaque scénario de test doit inclure une valeur pour chaque variable dans le modèle d'invite.
Les invites peuvent avoir plusieurs variables dans chaque scénario de test. Par exemple, si vous souhaitez tester un modèle d'invite comprenant une variable pour le nom d'un comédien et un sujet de blague, vous pouvez configurer des scénarios de test pour différents comédiens et sujets.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Chaque cas est testé par rapport à chaque invite, afin d'obtenir une comparaison équitable des performances de chaque invite avec les mêmes données d'entrée. Avec 4 cas de test et 2 invites, vous obtiendrez 8 combinaisons (4 cas de test x 2 modèles d'invite), qui s'exécuteront chacune 10 fois (80 appels au total vers OpenAI).
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])Cela exécutera chaque invite sur chaque modèle, afin d'obtenir une comparaison équitable des performances de chaque invite avec les mêmes données d'entrée. Avec 2 invites et 2 modèles, vous obtiendrez 4 combinaisons (2 invites x 2 modèles), qui s'exécuteront chacune 10 fois (40 appels au total vers OpenAI).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) Les invites peuvent être une chaîne ou un tableau de chaînes. Si l'invite est un tableau, la première chaîne est utilisée comme message système et le reste des invites alterne entre les messages Human et Assistant ( [system, human, ai, human, ai, ...] ). Ceci est utile pour tester les invites qui incluent un message système ou qui utilisent le préchauffage (insertion de messages antérieurs dans le chat pour guider l'IA vers le comportement souhaité).
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )Une fois le test terminé, vous obtenez un rapport d'évaluation complet, décomposé par PID, CID et modèle, ainsi qu'un rapport global décomposé par toutes les combinaisons. Si vous ne testez qu’un seul modèle ou un seul cas, ces pannes seront supprimées. Le rapport affiche une clé en bas pour voir quel ID correspond à quelle invite ou à quel cas.
La fonction thumb.test prend les paramètres suivants :
None )10 )gpt-3.5-turbo ])True ) Si vous disposez de 10 exécutions de tests avec 2 modèles d'invite et 3 scénarios de test, cela représente 10 x 2 x 3 = 60 appels à OpenAI. Attention : surtout avec GPT-4, les coûts peuvent s'accumuler rapidement !
Le traçage Langchain vers LangSmith est automatiquement activé si LANGCHAIN_API_KEY est défini comme variable d'environnement (facultatif).
la fonction .test() renvoie un objet ThumbTest . Vous pouvez ajouter d'autres invites ou cas au test, ou l'exécuter plusieurs fois. Vous pouvez également générer, évaluer et exporter les données de test à tout moment.
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Chaque modèle d'invite obtient les mêmes données d'entrée de chaque scénario de test, mais l'invite n'a pas besoin d'utiliser toutes les variables du scénario de test. Comme dans l'exemple ci-dessus, l'invite tell me a knock knock joke n'utilise pas la variable subject , mais elle est toujours générée une fois (sans variable) pour chaque scénario de test.
Les données de test sont mises en cache dans un fichier JSON local thumb/.cache/{TestID}.json après la génération de chaque ensemble d'exécutions pour une combinaison d'invite et de cas. Si votre test est interrompu ou si vous souhaitez y ajouter des éléments, vous pouvez utiliser la fonction thumb.load pour charger les données de test depuis le cache.
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () Chaque exécution pour chaque combinaison d'invite et de cas est stockée dans l'objet (et le cache), et donc appeler à nouveau test.generate() ne générera pas de nouvelles réponses si d'autres invites, cas ou exécutions ne sont pas ajoutés. De même, appeler à nouveau test.evaluate() ne réévaluera pas les réponses que vous avez déjà notées et réaffichera simplement les résultats si le test est terminé.
La différence entre les personnes qui jouent simplement avec ChatGPT et celles qui utilisent l'IA en production est l'évaluation. Les LLM répondent de manière non déterministe et il est donc important de tester à quoi ressemblent les résultats lorsqu'ils sont étendus à un large éventail de scénarios. Sans cadre d'évaluation, vous devez deviner aveuglément ce qui fonctionne (ou non) dans vos invites.
Des ingénieurs sérieux testent et apprennent quelles entrées conduisent à des résultats utiles ou souhaités, de manière fiable et à grande échelle. Ce processus est appelé optimisation rapide et ressemble à ceci :
Les tests du pouce comblent le fossé entre les mécanismes d'évaluation professionnelle à grande échelle et les incitations aveugles par essais et erreurs. Si vous transférez une invite vers un environnement de production, l'utilisation thumb pour tester votre invite peut vous aider à détecter les cas extrêmes et à obtenir les premiers commentaires des utilisateurs ou de l'équipe sur les résultats.
Ces personnes construisent thumb pour s'amuser pendant leur temps libre. ?
marteau-mt |


