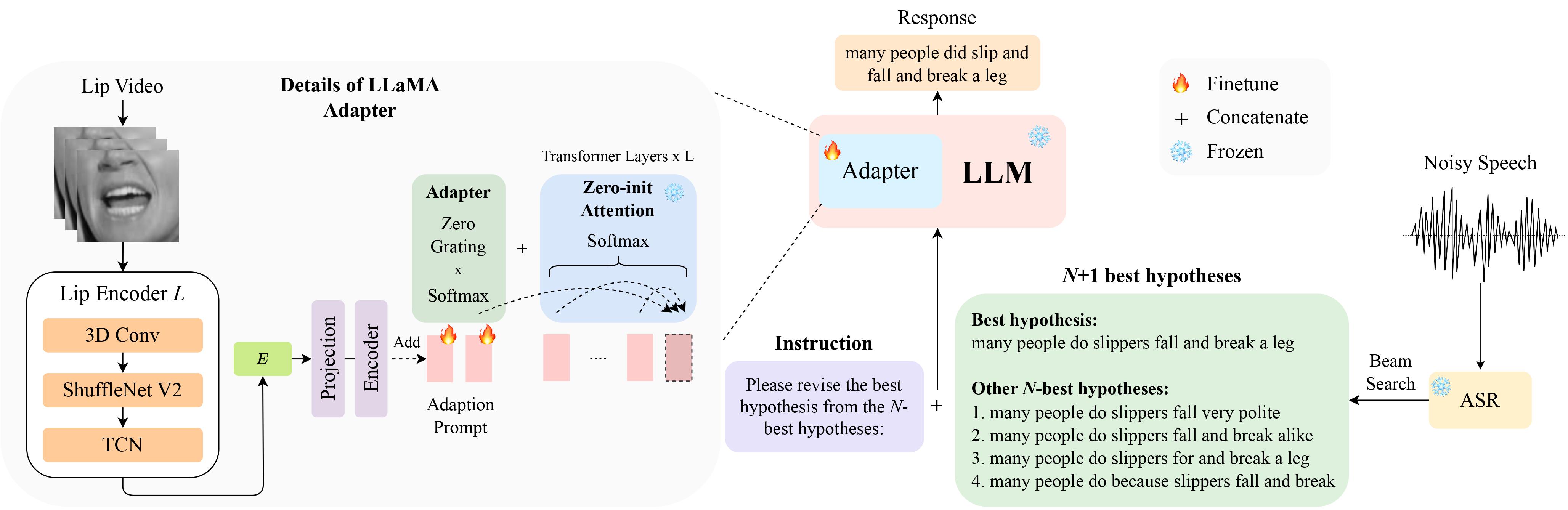
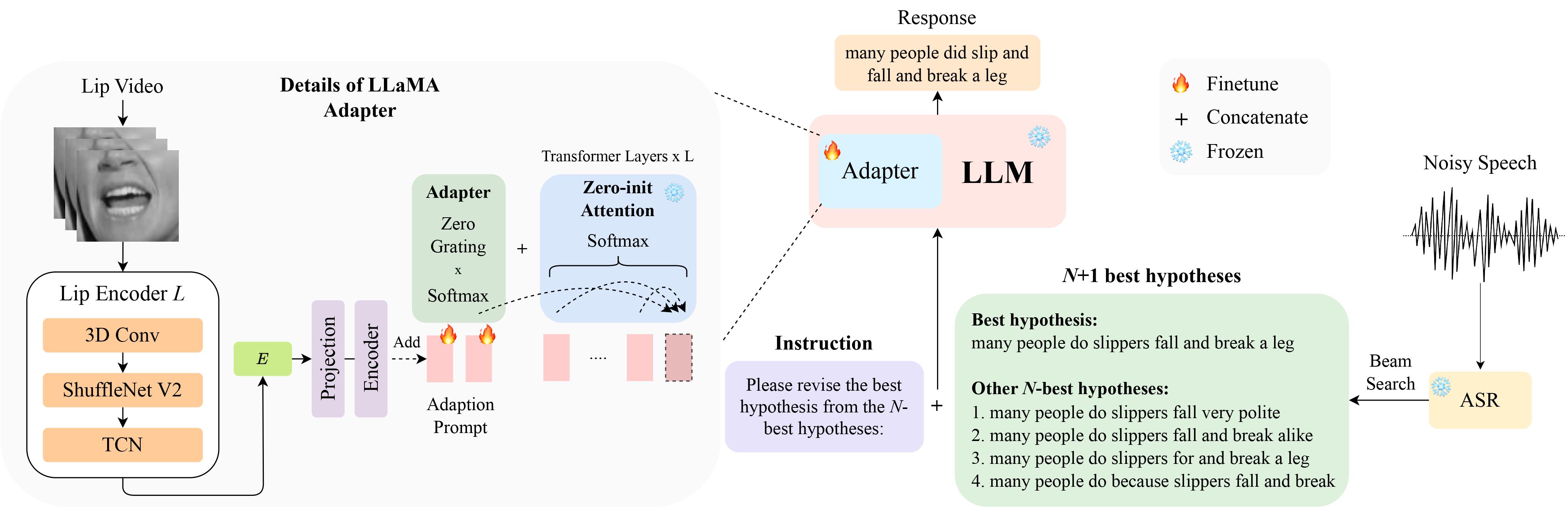
LipGER
Initial Release
Esta é a implementação oficial do nosso artigo LipGER: Correção de erros generativos visualmente condicionados para reconhecimento automático robusto de fala no InterSpeech 2024, que foi selecionado para apresentação oral .
Você pode baixar os dados do LipHyp aqui!
pip install -r requirements.txt
Primeiro prepare os pontos de verificação usando:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfPara ver todos os pontos de verificação disponíveis, execute:
python scripts/download.py | grep Llama-2Para mais detalhes, você também pode consultar este link, onde também pode preparar outros pontos de verificação para outros modelos. Especificamente, usamos o TinyLlama para nossos experimentos.
O ponto de verificação está disponível aqui. Após o download, altere o caminho do ponto de verificação aqui.
LipGER espera que todos os arquivos de treinamento, val e teste estejam no formato sample_data.json. Uma instância no arquivo se parece com:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Você precisa passar os arquivos de fala por um modelo ASR treinado, capaz de gerar N melhores hipóteses. Fornecemos duas maneiras neste repositório para ajudá-lo a conseguir isso. Sinta-se à vontade para usar outros métodos.
pip install whisper e, em seguida, executar nhyps.py a partir da pasta data , você deve estar bem! Observe que para ambos os métodos, o primeiro da lista é a melhor hipótese e os demais são as N-melhores hipóteses (elas são passadas como um campo de lista nhyps_base do JSON e usadas para construir um prompt nas próximas etapas).
Além disso, os métodos fornecidos usam apenas fala como entrada. Para geração de N-melhores hipóteses audiovisuais, utilizamos Auto-AVSR. Se precisar de ajuda com o código, levante um problema!
Supondo que você tenha vídeos correspondentes para todos os seus arquivos de fala, siga estas etapas para cortar o ROI dos vídeos.
python crop_mouth_script.py
python covert_lip.py
Isso converterá o ROI mp4 em hdf5, o código alterará o caminho do ROI mp4 para ROI hdf5 no mesmo arquivo json. Você pode escolher entre os detectores "mediapipe" e "retinaface" alterando o "detector" em default.yaml
Depois de ter as N melhores hipóteses, construa o arquivo JSON no formato necessário. Não fornecemos código específico para esta parte, pois a preparação dos dados pode ser diferente para cada pessoa, mas o código deve ser simples. Novamente, levante uma questão se tiver alguma dúvida!
Os scripts de treinamento LipGER não aceitam JSON para treinamento ou avaliação. Você precisa convertê-los em um arquivo pt. Você pode executar convert_to_pt.py para conseguir isso! Altere model_name de acordo com seu desejo na linha 27 e adicione o caminho para seu JSON na linha 58.
Para ajustar o LipGER, basta executar:
sh finetune.sh
onde você precisa definir manualmente os valores dos data (com o nome do conjunto de dados), --train_path e --val_path (com caminhos absolutos para treinar e arquivos .pt válidos).
Para inferência, primeiro altere os respectivos caminhos em lipger.py ( exp_path e checkpoint_dir ) e depois execute (com o argumento de caminho de dados de teste apropriado):
sh infer.sh
O código para cortar o ROI da boca é inspirado em Visual_Speech_Recognition_for_Multiple_Languages.
Nosso código para LipGER é inspirado no RobustGER. Por favor, cite o artigo deles também se você achar nosso artigo ou código útil.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}