ai toolkit
1.0.0
นี่คือแหล่งวิจัยของฉัน ฉันทำการทดลองหลายอย่างในนั้นและเป็นไปได้ที่ฉันจะทำลายสิ่งต่างๆ หากมีสิ่งใดขัดข้อง ให้ชำระเงินการคอมมิตก่อนหน้านี้ Repo นี้สามารถฝึกสิ่งต่างๆ ได้มากมาย และเป็นการยากที่จะตามให้ทันทั้งหมด
งานของฉันในโครงการนี้จะเป็นไปไม่ได้หากปราศจากการสนับสนุนอันน่าทึ่งของ Glif และทุกคนในทีม อยากสนับสนุนก็สนับสนุนกลิฟ เข้าร่วมเว็บไซต์ เข้าร่วมกับเราบน Discord ติดตามเราบน Twitter และมาร่วมสร้างสรรค์สิ่งเจ๋งๆ กับเรา
ความต้องการ:
ลินุกซ์:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtหน้าต่าง:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtหากต้องการเริ่มต้นอย่างรวดเร็ว โปรดดูบทช่วยสอน @araminta_k เกี่ยวกับ Finetuning Flux Dev บน 3090 พร้อม 24GB VRAM
ขณะนี้คุณต้องการ GPU ที่มี VRAM อย่างน้อย 24GB เพื่อฝึก FLUX.1 หากคุณใช้เป็น GPU เพื่อควบคุมจอภาพของคุณ คุณอาจต้องตั้งค่าสถานะ low_vram: true ในไฟล์ปรับแต่งภายใต้ model: สิ่งนี้จะนับจำนวนโมเดลบน CPU และควรอนุญาตให้ฝึกฝนโดยแนบจอภาพได้ ผู้ใช้ได้รับมันให้ทำงานบน Windows ด้วย WSL แต่มีรายงานบางส่วนเกี่ยวกับข้อผิดพลาดเมื่อทำงานบน windows แบบเนทิฟ ตอนนี้ฉันเพิ่งทดสอบบน linux เท่านั้น นี่ยังคงเป็นการทดลองอย่างมาก และต้องมีการวัดปริมาณและเทคนิคมากมายเพื่อให้พอดีกับ 24GB เลย
FLUX.1-dev มีใบอนุญาตที่ไม่ใช่เชิงพาณิชย์ ซึ่งหมายความว่าสิ่งที่คุณฝึกอบรมจะได้รับใบอนุญาตที่ไม่ใช่เชิงพาณิชย์ นอกจากนี้ยังเป็นโมเดลที่มีรั้วรอบขอบชิดด้วย ดังนั้นคุณต้องยอมรับใบอนุญาตบน HF ก่อนใช้งาน มิฉะนั้นสิ่งนี้จะล้มเหลว ต่อไปนี้เป็นขั้นตอนที่จำเป็นในการตั้งค่าใบอนุญาต
.env ในรูทของโฟลเดอร์นี้.env เช่นนั้น HF_TOKEN=your_key_hereFLUX.1-schnell คือ Apache 2.0 ทุกสิ่งที่ได้รับการฝึกอบรมสามารถขอใบอนุญาตได้ตามที่คุณต้องการ และไม่ต้องใช้ HF_TOKEN ในการฝึกอบรม อย่างไรก็ตาม ต้องใช้อะแดปเตอร์พิเศษในการฝึก ostris/FLUX.1-schnell-training-adapter นอกจากนี้ยังมีการทดลองอย่างมาก เพื่อคุณภาพโดยรวมที่ดีที่สุด ขอแนะนำให้ฝึกอบรมบน FLUX.1-dev
หากต้องการใช้งาน คุณเพียงแค่ต้องเพิ่มผู้ช่วยในส่วน model ของไฟล์ปรับแต่งของคุณ ดังนี้:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueคุณยังต้องปรับขั้นตอนตัวอย่างของคุณเนื่องจาก schnell ไม่ต้องการมากขนาดนั้น
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml for schnell) ไปยังโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.ymlpython run.py config/whatever_you_want.ymlโฟลเดอร์ที่มีชื่อและโฟลเดอร์การฝึกอบรมจากไฟล์ปรับแต่งจะถูกสร้างขึ้นเมื่อคุณเริ่มต้น โดยจะมีจุดตรวจและรูปภาพทั้งหมดอยู่ในนั้น คุณสามารถหยุดการฝึกเมื่อใดก็ได้โดยใช้ Ctrl+c และเมื่อคุณทำต่อ การฝึกจะดึงกลับจากจุดตรวจสุดท้าย
สำคัญ. หากคุณกด crtl+c ในขณะที่กำลังบันทึก อาจทำให้จุดตรวจสอบนั้นเสียหายได้ ดังนั้นรอจนกว่าจะบันทึกเสร็จ
กรุณาอย่าเปิดรายงานข้อผิดพลาด เว้นแต่จะเป็นข้อผิดพลาดในโค้ด คุณสามารถเข้าร่วม Discord ของฉันและขอความช่วยเหลือได้ที่นั่น อย่างไรก็ตาม โปรดงดเว้น PM มาหาฉันโดยตรงหากมีคำถามหรือการสนับสนุนทั่วไป ถามในความขัดแย้งและฉันจะตอบเมื่อฉันทำได้
หากต้องการเริ่มต้นการฝึกอบรมในพื้นที่ด้วย UI ที่กำหนดเอง เมื่อคุณทำตามขั้นตอนข้างต้นและติดตั้ง ai-toolkit แล้ว:
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py คุณจะสร้างอินสแตนซ์ UI ที่จะให้คุณอัปโหลดภาพ ใส่คำบรรยาย ฝึกอบรม และเผยแพร่ LoRA ของคุณ 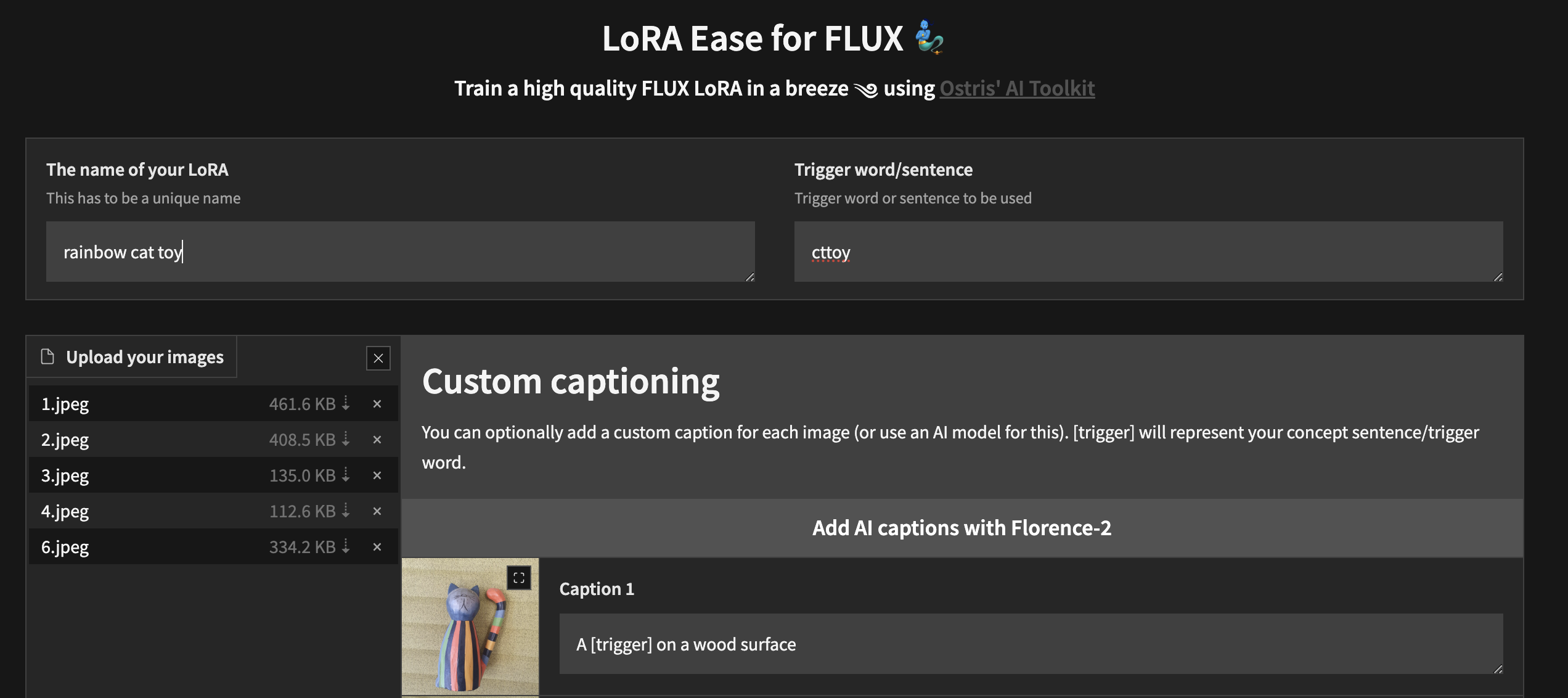
ตัวอย่างเทมเพลต RunPod: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
คุณต้องมี VRAM ขั้นต่ำ 24GB เลือก GPU ตามที่คุณต้องการ
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset หรืออะไรก็ได้ที่คุณต้องการhuggingface-cli login และวางโทเค็นของคุณconfig/examples ไปยังโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.ymlfolder_path: "/path/to/images/folder" เป็นพาธชุดข้อมูลของคุณ เช่น folder_path: "/workspace/ai-toolkit/your-dataset"python run.py config/whatever_you_want.yml
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal เพื่อติดตั้งแพ็คเกจ modal Pythonmodal setup เพื่อตรวจสอบสิทธิ์ (หากไม่ได้ผล ให้ลอง python -m modal setup ) huggingface-cli login และวางโทเค็นของคุณai-toolkitconfig/examples/modal ไปยังโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.yml/root/ai-toolkit paths ตั้งค่าเส้นทาง ai-toolkit ในเครื่องทั้งหมดของคุณที่ code_mount = modal.Mount.from_local_dir เช่น:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
เลือก GPU และ Timeout ใน @app.function (ค่าเริ่มต้นคือ A100 40GB และหมดเวลา 2 ชั่วโมง)
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.ymlStorage > flux-lora-modelsmodal volume ls flux-lora-modelsmodal volume get flux-lora-models your-model-namemodal volume get flux-lora-models my_first_flux_lora_v1
โดยทั่วไปชุดข้อมูลจะต้องเป็นโฟลเดอร์ที่มีรูปภาพและไฟล์ข้อความที่เกี่ยวข้อง ปัจจุบันรองรับรูปแบบเดียวคือ jpg, jpeg และ png ขณะนี้ Webp มีปัญหา ไฟล์ข้อความควรตั้งชื่อเหมือนกับรูปภาพ แต่มีนามสกุล . .txt เช่น image2.jpg และ image2.txt ไฟล์ข้อความควรมีเฉพาะคำบรรยายภาพเท่านั้น คุณสามารถเพิ่มคำว่า [trigger] ลงในไฟล์คำอธิบายภาพได้ และหากคุณมี trigger_word ในการกำหนดค่าของคุณ คำนั้นจะถูกแทนที่โดยอัตโนมัติ
รูปภาพจะไม่ได้รับการขยายขนาด แต่จะลดขนาดลงและวางไว้ในที่เก็บข้อมูลเพื่อจัดเป็นชุด คุณไม่จำเป็นต้องครอบตัด/ปรับขนาดรูปภาพของคุณ ตัวโหลดจะปรับขนาดโดยอัตโนมัติและสามารถรองรับอัตราส่วนภาพที่แตกต่างกันได้
หากต้องการฝึกเลเยอร์เฉพาะด้วย LoRA คุณสามารถใช้ only_if_contains kwargs เครือข่ายได้ ตัวอย่างเช่น หากคุณต้องการฝึกฝนเฉพาะ 2 เลเยอร์ที่ใช้โดย The Last Ben ดังที่กล่าวถึงในโพสต์นี้ คุณสามารถปรับ kwargs เครือข่ายของคุณได้ดังนี้:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " รูปแบบการตั้งชื่อของเลเยอร์จะอยู่ในรูปแบบตัวกระจาย ดังนั้นการตรวจสอบ state dict ของโมเดลจะเปิดเผยส่วนต่อท้ายของชื่อของเลเยอร์ที่คุณต้องการฝึก คุณยังสามารถใช้วิธีนี้เพื่อฝึกตุ้มน้ำหนักเฉพาะกลุ่มได้ ตัวอย่างเช่น หากต้องการฝึกฝน single_transformer สำหรับ FLUX.1 เท่านั้น คุณสามารถใช้สิ่งต่อไปนี้:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " คุณยังสามารถยกเว้นเลเยอร์ตามชื่อได้โดยใช้ละเลย ignore_if_contains เครือข่าย kwarg ดังนั้นเพื่อไม่รวมบล็อกหม้อแปลงเดี่ยวทั้งหมด
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains มีลำดับความสำคัญมากกว่า only_if_contains ดังนั้นหากทั้งสองน้ำหนักครอบคลุมอยู่ ถ้าจะถูกละเว้น
มันอาจยังใช้งานได้อยู่ แต่ฉันยังไม่ได้ทดสอบมาระยะหนึ่งแล้ว
โปรแกรมสร้างรูปภาพที่สามารถนำ frompts จากไฟล์กำหนดค่าหรือสร้างไฟล์ txt และสร้างลงในโฟลเดอร์ ฉันต้องการสิ่งนี้เป็นหลักสำหรับการทดสอบ SDXL ที่ฉันทำอยู่ แต่ได้เพิ่มการขัดเกลาบางอย่างลงไปเพื่อให้สามารถใช้สำหรับการสร้างภาพเป็นชุดได้ ทุกอย่างทำงานโดยใช้ไฟล์ปรับแต่ง ซึ่งคุณสามารถดูตัวอย่างได้ใน config/examples/generate.example.yaml ข้อมูลเพิ่มเติมอยู่ในความคิดเห็นในตัวอย่าง
มันขึ้นอยู่กับตัวแยกข้อมูลในเครื่องมือ LyCORIS แต่เพิ่มคุณสมบัติ QOL บางอย่างและการรองรับ LoRA (lierla) สามารถสกัดได้หลายประเภทในคราวเดียว ทุกอย่างทำงานโดยใช้ไฟล์กำหนดค่า ซึ่งคุณสามารถดูตัวอย่างได้ใน config/examples/extract.example.yml เพียงคัดลอกไฟล์นั้นลงในโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.yml จากนั้นคุณสามารถแก้ไขไฟล์ได้ตามต้องการ และเรียกมันว่า:
python3 run.py config/whatever_you_want.ymlคุณยังสามารถใส่เส้นทางแบบเต็มไปยังไฟล์กำหนดค่าได้ หากคุณต้องการเก็บไว้ที่อื่น
python3 run.py " /home/user/whatever_you_want.yml "หมายเหตุเพิ่มเติมเกี่ยวกับวิธีการทำงานมีอยู่ในไฟล์ปรับแต่งตัวอย่าง LoRA และ LoCON รองรับการแยก 'คงที่', 'เกณฑ์', 'อัตราส่วน', 'ควอนไทล์' ฉันจะอัปเดตสิ่งที่พวกเขาทำและหมายถึงในภายหลัง คนส่วนใหญ่ใช้วิธีคงที่ ซึ่งเป็นการแยกมิติคงที่แบบดั้งเดิม
process คืออาร์เรย์ของกระบวนการต่างๆ ที่จะเรียกใช้ คุณสามารถเพิ่มบางส่วนและผสมและจับคู่ได้ LoRA หนึ่งตัว, LyCON หนึ่งตัว ฯลฯ
เปลี่ยน <lora:my_lora:4.6> เป็น <lora:my_lora:1.0> หรืออะไรก็ได้ที่คุณต้องการด้วยเอฟเฟกต์แบบเดียวกัน เครื่องมือสำหรับปรับขนาดน้ำหนักของ LoRA ควรทำกับ LoCON เช่นกัน แต่ฉันยังไม่ได้ทดสอบ ทุกอย่างทำงานโดยใช้ไฟล์กำหนดค่า ซึ่งคุณสามารถดูตัวอย่างได้ใน config/examples/mod_lora_scale.yml เพียงคัดลอกไฟล์นั้นลงในโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.yml จากนั้นคุณสามารถแก้ไขไฟล์ได้ตามต้องการ และเรียกมันว่า:
python3 run.py config/whatever_you_want.ymlคุณยังสามารถใส่เส้นทางแบบเต็มไปยังไฟล์กำหนดค่าได้ หากคุณต้องการเก็บไว้ที่อื่น
python3 run.py " /home/user/whatever_you_want.yml "หมายเหตุเพิ่มเติมเกี่ยวกับวิธีการทำงานมีอยู่ในไฟล์ปรับแต่งตัวอย่าง สิ่งนี้มีประโยชน์ในการสร้าง LoRA ทั้งหมด เนื่องจากน้ำหนักในอุดมคตินั้นแทบจะไม่อยู่ที่ 1.0 แต่ตอนนี้คุณสามารถแก้ไขได้แล้ว สำหรับสไลเดอร์ พวกมันอาจมีเกล็ดแปลกๆ อยู่ระหว่าง -2 ถึง 2 หรือ -15 ถึง 15 ซึ่งจะทำให้คุณสามารถเจาะเข้าไปได้เพื่อให้พวกมันมีมาตราส่วนที่คุณต้องการ
นี่คือวิธีที่ฉันฝึกแถบเลื่อนล่าสุดส่วนใหญ่ที่ฉันมีใน Civitai คุณสามารถดูพวกมันได้ในโปรไฟล์ Civitai ของฉัน มีพื้นฐานมาจากงานของ p1atdev/LECO และ rohitgandikota/erasing แต่ได้รับการแก้ไขอย่างหนักเพื่อสร้างแถบเลื่อนแทนที่จะลบแนวคิด ฉันมีแผนมากกว่านี้มากเกี่ยวกับเรื่องนี้ แต่มันก็ใช้งานได้ดีเหมือนเดิม นอกจากนี้ยังใช้งานง่ายมาก เพียงคัดลอกไฟล์ปรับแต่งตัวอย่างใน config/examples/train_slider.example.yml ไปยังโฟลเดอร์ config และเปลี่ยนชื่อเป็น whatever_you_want.yml จากนั้นคุณสามารถแก้ไขไฟล์ได้ตามต้องการ และเรียกมันว่า:
python3 run.py config/whatever_you_want.ymlมีข้อมูลเพิ่มเติมมากมายในไฟล์ตัวอย่างนั้น คุณยังสามารถเรียกใช้ตัวอย่างตามที่เป็นอยู่โดยไม่ต้องแก้ไขใดๆ เพื่อดูว่ามันทำงานอย่างไร มันจะสร้างแถบเลื่อนที่จะเปลี่ยนสัตว์ทั้งหมดให้เป็นสุนัข(neg) หรือแมว(pos) เพียงแค่เรียกใช้มันเช่นนั้น:
python3 run.py config/examples/train_slider.example.ymlและคุณจะสามารถดูวิธีการทำงานได้โดยไม่ต้องกำหนดค่าอะไรเลย ไม่จำเป็นต้องมีชุดข้อมูลสำหรับวิธีนี้ ฉันจะโพสต์กวดวิชาที่ดีขึ้นเร็ว ๆ นี้
ตอนนี้คุณสามารถสร้างและแชร์ส่วนขยายที่กำหนดเองได้แล้ว ที่ทำงานภายในเฟรมเวิร์กนี้และมีเครื่องมือในตัวทั้งหมดให้เลือก ฉันอาจจะใช้สิ่งนี้เป็นวิธีการพัฒนาหลักในอนาคต ดังนั้นฉันจึงไม่เพิ่มและเพิ่มคุณสมบัติเพิ่มเติมให้กับ repo พื้นฐานนี้อีกต่อไป ฉันมีแนวโน้มที่จะย้ายฟังก์ชันการทำงานที่มีอยู่จำนวนมากเพื่อทำให้ทุกอย่างเป็นแบบโมดูลาร์ มีตัวอย่างส่วนขยายในโฟลเดอร์ extensions ที่แสดงวิธีสร้างส่วนขยายการรวมโมเดล โค้ดทั้งหมดได้รับการบันทึกไว้อย่างแน่นหนา ซึ่งหวังว่าจะเพียงพอที่จะให้คุณเริ่มต้นได้ หากต้องการสร้างส่วนขยาย เพียงคัดลอกตัวอย่างนั้นและแทนที่ทุกสิ่งที่คุณต้องการ
ตั้งอยู่ในโฟลเดอร์ extensions เป็นการควบรวมโมเดลแบบ finctional อย่างสมบูรณ์ซึ่งสามารถรวมโมเดลได้มากเท่าที่คุณต้องการ มันเป็นตัวอย่างที่ดีของวิธีการสร้างส่วนขยาย แต่ก็เป็นคุณสมบัติที่มีประโยชน์เช่นกัน เนื่องจากการควบรวมกิจการส่วนใหญ่สามารถทำได้ครั้งละหนึ่งโมเดลเท่านั้น และอันนี้จะใช้เวลามากเท่าที่คุณต้องการป้อน มีไฟล์ปรับแต่งตัวอย่างอยู่ในนั้น เพียงคัดลอกไฟล์นั้นไปยังโฟลเดอร์ config ของคุณแล้วเปลี่ยนชื่อเป็น whatever_you_want.yml และใช้งานเหมือนกับไฟล์ปรับแต่งอื่น ๆ
ใช้งานได้ แต่ไม่พร้อมให้ผู้อื่นใช้ ดังนั้นจึงไม่มีการกำหนดค่าตัวอย่าง ฉันยังคงทำงานอยู่ ฉันจะอัปเดตสิ่งนี้เมื่อพร้อม ฉันกำลังเพิ่มคุณสมบัติมากมายสำหรับเกณฑ์ที่ฉันใช้ในการขยายภาพ นักวิจารณ์ (ผู้แยกแยะ) การสูญเสียเนื้อหา การสูญเสียสไตล์ และอื่นๆ อีกเล็กน้อย หากคุณไม่ทราบ VAE สำหรับการแพร่กระจายที่เสถียร (ใช่แม้กระทั่ง MSE และ SDXL) จะดูแย่มากที่ใบหน้าที่เล็กกว่าและจะรั้ง SD ไว้ ฉันจะแก้ไขปัญหานี้ ฉันจะโพสต์เพิ่มเติมเกี่ยวกับเรื่องนี้ในภายหลังพร้อมตัวอย่างที่ดีกว่าในภายหลัง แต่นี่คือการทดสอบคร่าวๆ เกี่ยวกับ VAE ต่างๆ เพิ่งเข้าๆออกๆ มันจะแย่กว่ามากกับใบหน้าที่เล็กกว่าที่แสดงไว้ที่นี่
extensions อ่านเพิ่มเติมเกี่ยวกับเรื่องที่ด้านบนการปรับโครงสร้างครั้งใหญ่อีกประการหนึ่งเพื่อทำให้ SD เป็นโมดูลาร์มากขึ้น
สร้างสคริปต์การสร้างภาพเป็นชุด
การเปลี่ยนแปลงและการปรับปรุงที่สำคัญ เครื่องมือรีสเกล LoRA ใหม่ โปรดดูรายละเอียดด้านบน เพิ่มข้อมูลเมตาที่ดีขึ้นเพื่อให้ Automatic1111 รู้ว่าโมเดลพื้นฐานคืออะไร เพิ่มการทดลองและการอัปเดตมากมาย สิ่งนี้ยังคงไม่เสถียรในขณะนี้ หวังว่าจะไม่มีการเปลี่ยนแปลงที่สำคัญ
น่าเสียดายที่ฉันขี้เกียจเกินกว่าจะเขียนบันทึกการเปลี่ยนแปลงที่เหมาะสมกับการเปลี่ยนแปลงทั้งหมด
ฉันเพิ่มการฝึกอบรม SDXL ให้กับตัวเลื่อน... แต่.. มันทำงานไม่ถูกต้อง การฝึก Slider ขึ้นอยู่กับความสามารถของโมเดลในการทำความเข้าใจว่าพรอมต์ที่ไม่มีเงื่อนไข (พรอมต์เชิงลบ) หมายความว่าคุณไม่ต้องการให้แนวคิดนั้นปรากฏในเอาต์พุต SDXL ไม่เข้าใจสิ่งนี้ไม่ว่าด้วยเหตุผลใดก็ตาม ซึ่งทำให้การแยกแนวคิดภายในโมเดลเป็นเรื่องยาก ฉันแน่ใจว่าชุมชนจะหาทางแก้ไขปัญหานี้เมื่อเวลาผ่านไป แต่ตอนนี้มันจะทำงานได้ไม่สมบูรณ์ และหากคุณคนใดกำลังคิดว่า "เราสามารถแก้ไขได้ด้วยการเพิ่มตัวเข้ารหัสข้อความอีก 1 หรือ 2 ตัวให้กับโมเดล รวมถึงเครือข่ายการแพร่กระจายที่แยกจากกันโดยสิ้นเชิงอีกสองสามเครือข่ายหรือไม่" ไม่ พระเจ้า ไม่ เพียงต้องการการฝึกอบรมเพียงเล็กน้อยโดยไม่ต้องเพิ่มรายงานการทดลองใหม่ๆ เข้าไปทุกรายการ ครูใหญ่ KISS
เพิ่ม "จุดยึด" ให้กับเทรนเนอร์สไลเดอร์ ซึ่งจะทำให้คุณสามารถตั้งค่าพรอมต์ที่จะใช้เป็นตัวกำหนดมาตรฐานได้ คุณสามารถตั้งค่าตัวคูณเครือข่ายเพื่อบังคับให้กระจายความสม่ำเสมอที่น้ำหนักสูงได้


