AI Job Info
1.0.0
อัปเดตล่าสุด: 25/10/2019
2019/08/21 - อัปเดตแคตตาล็อก
2019/09/05 - เพิ่ม 9 ยูนิต
21/09/2019 - อัปเดตข้อมูลผู้เขียน
10/10/2019 - อัปเดตพระสูตรบวกใบหน้า 10 รายการ
25/10/2019 - อัปเดตของ Alibaba Damo Academy
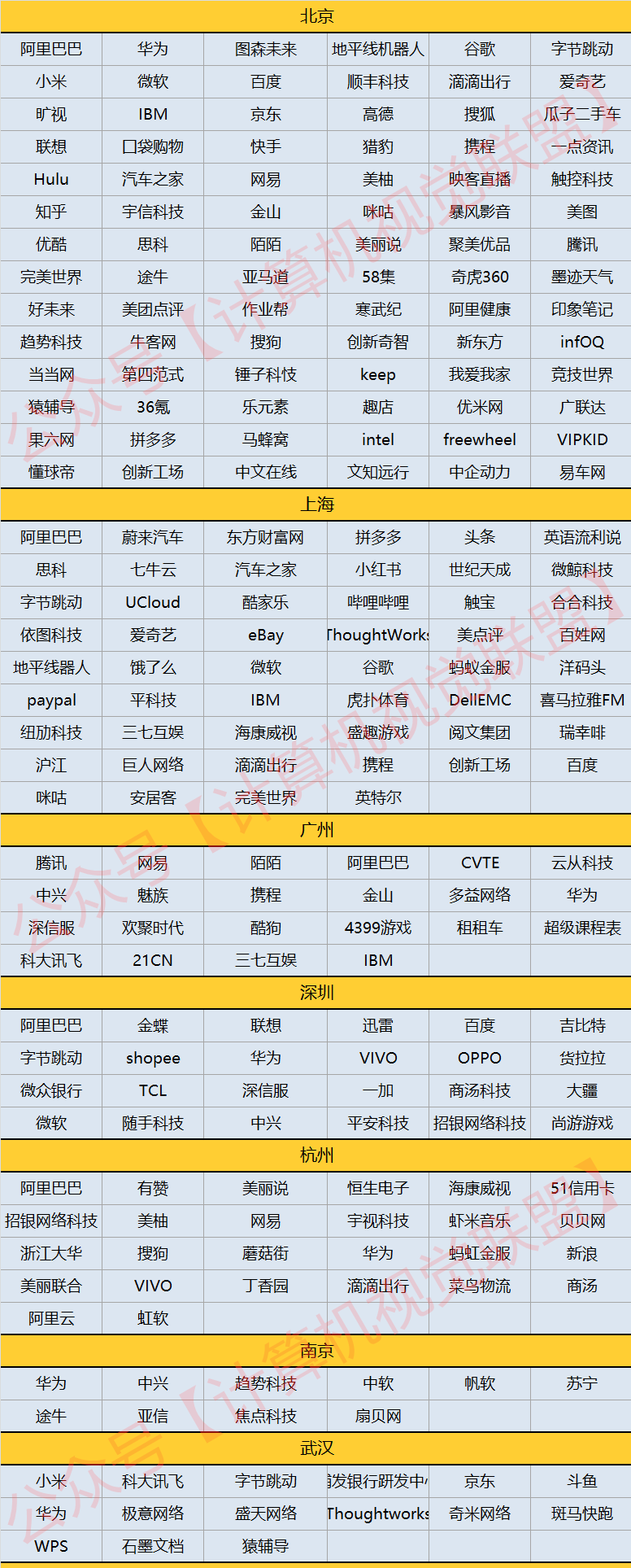
1. ภาพรวมโดยรวมของ Huawei, DJI, Toutiao, Alibaba, Baidu, Alibaba, Tencent, JD.com และ Xiaomi
2. การสัมภาษณ์ฝึกงานอัลกอริธึมการมองเห็นคอมพิวเตอร์ของ Tencent ในปี 2020 สำหรับระดับปริญญาตรีและปริญญาโท 985 ปริญญาโทที่ไม่ใช่สาขาวิชาเอก
3. สัมภาษณ์ฝึกงานภาคฤดูร้อน Baidu Computer Vision
4. สัมภาษณ์ฝึกงาน JD Computer Vision
5.Oppo อนุมัติการสัมภาษณ์งาน C++ ล่วงหน้า
6. Midea อนุมัติวิศวกรการขุดข้อมูล Python ล่วงหน้า
7. ฝึกงานอัลกอริธึมรูปภาพที่ Momo Technology
8. ส่วนหน้าของ Baidu สามด้าน
9. Cambrian: วิศวกรการเรียนรู้เชิงลึก
10. หน้าแรก 2019.7.24
11. ไป่ตู้
12. เทนเซ็นต์
13. ผินตัวทัว2019.8.13
14. ถนนโมกุ 2019.8.14
15. การพัฒนาเกม NetEase Interactive Entertainment
16. การค้นหา 360 องศา (การจัดอันดับ) - วิศวกรการเรียนรู้ของเครื่อง
17. NetEase Internet: วิศวกรการเรียนรู้เชิงลึก
18. SF Express sp และ ihandy ขายพิเศษสำหรับลูกค้าโค
19. ดิดี้ นิวเค่ เอสพี เซสชั่นพิเศษ
20. Kuaishou Niuke sp เซสชันพิเศษ
21. อี้ตู่
22. เทนเซ็นต์
23. วิสัยทัศน์
24. ไป่ตู้
25. โซโก
26. ออปโป้
27.58 ในเมืองเดียวกัน
28. หัวเว่ย
29. อาลีบาบา ดาโม อคาเดมี
หมายเหตุ
ฉันสำเร็จการศึกษาระดับปริญญาตรีและปริญญาโท 985 (โรงเรียนมีอันดับต่ำกว่า) ฉันไม่ได้มีความรู้ด้านคอมพิวเตอร์และเคยทำโครงการ CV ที่เกี่ยวข้องมาก่อน ฉันรู้สึกผิดเล็กน้อย แต่เจ้านายเป็นผู้นำ การแข่งขันหลายครั้ง
งานอัลกอริทึมการมองเห็นคอมพิวเตอร์ของ Tencent
การเรียกคืนเนื้อหาการสัมภาษณ์โดยรวม ไม่ว่าจะสัมภาษณ์ครั้งใดก็ตาม
ไม่ว่าจะเป็นการสัมภาษณ์ครั้งไหน คุณจะต้องแนะนำตัวเองก่อนเสมอ อธิบายจุดแข็งของคุณเป็นเวลาหนึ่งนาที และบางครั้งก็พูดถึงความคิดเห็นของคุณเกี่ยวกับข้อบกพร่องสั้นๆ
คุณเคยเข้าร่วมการฝึกงานที่เกี่ยวข้อง คุณเคยทำโปรเจ็กต์ใดบ้าง เคยเล่นเกมมาแล้วกี่เกม และเคยเล่นตำแหน่งใดบ้าง โดยเน้นที่เกมที่ฉันคุ้นเคย ฉันจะอธิบายรายละเอียดหลักการของอัลกอริทึมและการวิเคราะห์ผลลัพธ์ของเกม หากฉันเล่นเกมอีกครั้งในครั้งต่อไปจะปรับปรุงอันดับของฉันอย่างไร ได้อะไรจากการเล่นเกม? คุณคิดว่าอะไรคือความแตกต่างระหว่างอุตสาหกรรมและการวิจัยทางวิทยาศาสตร์
ปริญญาโทสามัญ 985 แต่ไม่มีคำแนะนำภายใน ฉันได้รับข้อเสนอการฝึกงานภาคฤดูร้อนของ Baidu CV
ไม่ยากเกินไป คนสัมภาษณ์น่ารักมาก มีสัมภาษณ์ 3 รอบ มี Resume โปรเจ็กต์ แล้วเราก็เริ่มขยายงาน
สรุป: พี่ชายของฉันแนะนำให้มุ่งเน้นไปที่การวิจัยอัลกอริธึมพื้นฐาน โครงสร้างข้อมูล แผนผังการตัดสินใจ และวิธีการใช้งานอัลกอริธึมการประมวลผลภาพทั่วไป
สรุป: โดยพื้นฐานแล้วคำถามทั้งหมดของทั้งสองฝ่ายเกี่ยวกับโครงการ และคำถามอื่นๆ คือการเน้นไปที่แนวคิดของคุณในการแก้ปัญหาและวิเคราะห์ข้อผิดพลาดในโครงการของคุณ
สรุป: ผู้สัมภาษณ์ค่อนข้างเป็นมืออาชีพและไม่มีการออกอากาศ อย่าแสร้งทำเป็นไม่เข้าใจ
ผู้เขียน: ส่งต่อสิ่งนี้เกินน้องสาว
ผู้เขียน : สุ่ย ยี่ สุ่ย
1. คำตอบการแนะนำตนเอง: คลื่นแห่งการปฏิบัติงานประจำ ข้อมูลพื้นฐาน + ความสามารถทางเทคนิค + พลังอ่อน
2. บอกเราเกี่ยวกับการแข่งขันหรือโครงการที่คุณเข้าร่วม? คำตอบ: โปสเตอร์พูดถึงการแข่งขัน
3. โดยทั่วไปแล้วโมเดลรูปภาพจะใช้อะไรบ้าง? คำตอบ: ผู้โพสต์บอกว่าเขาใช้โครงข่ายประสาทเทียมระดับลึกเป็นหลักและพูดคุยเกี่ยวกับโปรเจ็กต์
4. คุณรู้จักโมเดลใดบ้างเกี่ยวกับการเรียนรู้เชิงลึกหรือการเรียนรู้ของเครื่อง คำตอบ: ผู้โพสต์ต้นฉบับกล่าวถึง resnet ในโครงการผ่านการเรียนรู้เชิงลึก ในการเรียนรู้ของเครื่อง โดยทั่วไปการแข่งขันจะใช้ lgb และ xgb และบางส่วนก็ใช้ LR เช่นกัน ฉันยังใช้ lsmt, rnn และสิ่งที่คล้ายกันในการแข่งขันครั้งก่อน ๆ เหมาะกับการแข่งขันประเภทนี้
5. คุณเคยใช้ฐานข้อมูลอะไรบ้าง? คำตอบ: ฉันไม่ได้ใช้มันมากนัก ฉันใช้ฐานข้อมูล RDS ของ AWS แต่ฉันได้เรียนรู้คำสั่ง SQL ทั้งหมดแล้ว
6. ขณะนี้มีตารางที่ให้คุณแทรกและอัปเดตได้ จะใช้ SQL เพื่อนำไปใช้ได้อย่างไร? คำตอบ: แทรกและอัปเดต
7. สิ่งที่คุณเพิ่งพูดเป็นสองข้อความ จะนำไปใช้กับข้อความเดียวได้อย่างไร? คำตอบ: ฉันว่างเปล่ามาระยะหนึ่งแล้วและไม่ได้คิดถึงเรื่องนี้จริงๆ ผู้สัมภาษณ์บอกว่าบางทีคุณอาจไม่ได้ใช้มันบ่อยนัก ฉันตอบว่าใช่ ฐานข้อมูลมักจะมีขนาดไม่ใหญ่นัก และข้อกำหนดสำหรับจำนวนข้อความก็ไม่เข้มงวดมาก
8.คุณพูดภาษาอะไรเป็นหลัก? หลาม? คำตอบ: ฉันใช้ Python เมื่อเร็วๆ นี้ แต่โปรเจ็กต์ที่ฉันเพิ่งลงทะเบียนนั้นจริงๆ แล้วใช้ภาษา C++
9.คุณใช้แพ็คเกจ Python ใดเป็นหลัก? คำตอบ: Sklern, numpy, pandas และ matplotlib สำหรับการวาดภาพ ฉันรู้สึกอืดอยู่พักหนึ่งและคิดอะไรไม่ออก
10.หมีแพนด้าใช้ดัชนีอะไร? คำตอบ : ข้อมูลมีการปรับเปลี่ยน ซึ่งค่อนข้างจะคล้ายกับคีย์หลักของฐานข้อมูล (ผมว่าผมตอบได้ไม่ดีเท่านี้นะครับ ไม่รู้ว่าผู้สัมภาษณ์สังเกตเห็นหรือเปล่า...)
11. คุณมีคำถามอะไรสำหรับฉัน? คำตอบ: ตำแหน่งนี้ต้องใช้ทักษะทางวิศวกรรมสูงหรือไม่? หรือต้องใช้ความสามารถอัลกอริธึมสูง? ผู้สัมภาษณ์บอกว่าไม่ต้องตามผมมา ผมเพิ่งถูกจัดให้สัมภาษณ์โดยกลุ่มผู้เขียนรู้สึกเขินอายเล็กน้อย จากนั้นผู้สัมภาษณ์กล่าวว่าอัลกอริทึมจำเป็นต้องได้รับการดำเนินการต่อไป จากนั้นผู้โพสต์ถามคำถามอื่น นั่นคือ เมื่อสมัครงาน ฉันพบว่ามีสองแผนก แผนกไอทีกลุ่ม และ Meiyun Intelligent Data มีความแตกต่างอย่างมากระหว่างการดำรงตำแหน่งนี้ในสองแผนกนี้หรือไม่ ผู้สัมภาษณ์ตอบอยู่พักหนึ่ง - -
ผู้เขียน: EternityY
ผู้แต่ง: เซียวอัน วิ่ง! -
(1) ข้อแตกต่างระหว่าง WeChat Mini Program และ Vue (เพราะมีโครงการทำ WeChat Mini Program)
(2) หลักการสื่อสาร vuex ระหว่างส่วนประกอบ Vue
(3) คุณสมบัติใหม่ที่ใช้กันทั่วไปของ ES6
(4) แผนที่และกำหนดโครงสร้าง
(5) คำขอแบบอะซิงโครนัสสัญญาและ Async กำลังรออยู่
(6) การวาดรูปสามเหลี่ยมโดยใช้หลักการแบ่งส่วน
(7) วาดรูปทรงพัด
(8) แอนิเมชั่นการใช้งานแอนิเมชั่นและ requestAnimationFrame
(9) คุณรู้เกี่ยวกับการขอตัวเลือกการดึงตัวเลือกล่วงหน้าหรือไม่? ข้ามโดเมน
(10) ความปลอดภัยของเว็บ
(11) พิกเซลทางกายภาพและพิกเซลลอจิคัล เช่น 1px บนหน้าจอมีขนาดใหญ่เพียงใด
(12) คุณลักษณะขนาดกล่อง
(13) ความแตกต่างระหว่าง TCP และ UDP
(14) คุณเข้าใจการข้ามต้นไม้แบบไบนารีหรือไม่? วิธีสำรวจด้วยการสำรวจเส้นทางล่วงหน้า - -
(1) การแนะนำโครงการ Balabala ถามมากมายเกี่ยวกับปัญหาที่พบ (โซลูชันใช้ setTimeout ดังนั้นจึงขยาย Promise และ Async/await ต่อไปนี้)
(2) คุณสมบัติบางอย่างของ ES6 และความแตกต่างระหว่างวิธีการอาร์เรย์ ES6
(3) ค่าคีย์ของโครงสร้าง Set มีลักษณะอย่างไร (ไม่ชัดเจน)
(4) มีวิธีอื่นใดในการขจัดอาร์เรย์ที่ซ้ำกันนอกเหนือจาก Set หรือไม่
(5) การดำเนินการแบบอะซิงโครนัสคืออะไร? สัญญาและ Async/รอ
(6) ใช้ Promise เพื่อสรุปคำขอ Ajax โดยเรียกใช้วิธีนี้เพื่อรับข้อมูลที่ร้องขอผ่าน .then()
(7) วิธีการส่งคำขอมีอะไรบ้าง? เช่นอาแจ็กซ์
(8) ข้ามโดเมน: เหตุใดจึงต้องมีข้ามโดเมน? นโยบายต้นกำเนิดเดียวกันคืออะไร? วิธีแก้ปัญหาข้ามโดเมนสามารถแชร์ทรัพยากรระหว่างโดเมนหลักและโดเมนย่อยได้หรือไม่
(9) คุณเคยทำโครงการเทอร์มินัลมือถือหรือไม่? (ฉันทำไปแล้วแต่ลืมไป) วิธีปรับตัวเข้ากับเทอร์มินัลมือถือ
(10) ตัวรูดเทอร์มินัลมือถือและแอนิเมชั่น (ฉันขุดหลุมเพื่อตัวเอง เดิมทีฉันอยากจะพูดถึงมันแบบสบาย ๆ แต่กลับกลายเป็นว่าพวกมันทำงานบนเทอร์มินัลมือถือเป็นหลัก) วิธีบรรลุเอฟเฟกต์ของการเลื่อนขึ้นเพื่อแสดงหน้าถัดไป โดยไม่ต้องใช้ปลั๊กอินตัวปัด? มีกิจกรรมอะไรบ้างบนมือถือ?
(11) วิธีรับพารามิเตอร์ URL ของหน้า
(12) กลไกการมอบหมายงาน
ที่จริงแล้ว การสัมภาษณ์ครั้งที่สองส่วนใหญ่จะถามคำถามโดยพิจารณาจากสิ่งที่คุณทำในเรซูเม่และประเด็นความรู้ที่เกี่ยวข้องกับคำตอบของคุณ
(1) แนะนำโครงการในแง่ของความเป็นมาของโครงการ เหตุผลในการดำเนินการ ผลการดำเนินงาน และปัญหาที่พบ หลังจากคุยกันอยู่นานก็รู้สึกเหมือนจะหมดคำพูดเลยอธิบายไม่ชัดเจนจึงเปลี่ยนเรื่อง
(2) คุณเริ่มเรียนรู้ส่วนหน้าเมื่อใด และเหตุใดคุณจึงยึดติดกับทิศทางส่วนหน้าอยู่เสมอ
(3) คุณทำอะไรอีกบ้างระหว่างฝึกงานที่ Huawei?
(4) คุณเรียนรู้อะไรจากการฝึกงานที่ Huawei คุณได้ปรับปรุงความสามารถของตัวเองอย่างไรบ้าง?
(5) ทำไมต้องเรียนรู้ส่วนหน้าและความเข้าใจเกี่ยวกับส่วนหน้า
(6) การเปลี่ยนผ่านจากโรงเรียนไปสู่การฝึกงานของบริษัทเป็นอย่างไร?
(7) ตอนนี้คุณกำลังเรียนรู้สิ่งใหม่ๆ อะไรบ้าง? (ไม่ใช่ ฉันกำลังดูความรู้พื้นฐาน) จากนั้นให้ฉันยกตัวอย่างความรู้และสถานการณ์การใช้งาน
(8) เหตุใดจึงมีเฟรมเวิร์กส่วนหน้าที่สำคัญสามประการ พวกเขาแก้ปัญหาอะไร?
(9) คุณเผชิญกับความกดดันอะไรบ้าง และคุณปลดปล่อยมันอย่างไร?
(10) ประสบปัญหาอะไรบ้าง และจะแก้ไขอย่างไร? - (ขอคำแนะนำจากเพื่อนร่วมงาน) จะสื่อสารและขอคำแนะนำได้อย่างไร?
(11) คุณคิดว่าคุณมีข้อบกพร่องอะไรบ้าง? ฉันกำลังพูดถึงการขาดประสบการณ์ในทางปฏิบัติ (ดูเหมือนจะไม่ใช่เรื่องดี)
(12) คุณได้เรียนรู้เนื้อหาใหม่อะไรบ้างขณะวางรากฐาน? ไวยากรณ์ ES6, ความปลอดภัยของเว็บ - - จากนั้นฉันก็พูดถึงความปลอดภัยของเว็บโดยละเอียด ถามอีกครั้ง: การโจมตี XSS นั้นตรวจพบได้ยาก -
(13) แผนอาชีพในอนาคต
(14) คุณเคยสัมผัสภาษาพื้นหลังใดบ้าง?
(15) คุณเคยพบกับบริษัทอื่นมาก่อนหรือไม่?
(16) ตอนนี้คุณกำลังรับข้อเสนออื่นใดอีกหรือไม่?
(17) ปกติคุณเรียนรู้ความรู้ส่วนหน้าอย่างไร?
(18) คุณมีเวลาฝึกงานหรือไม่? ไม่มีเวลา ฉันต้องเขียนเรียงความขั้นสุดท้าย
(1) คุณคิดว่าแนวโน้มการพัฒนาในอนาคตของส่วนหน้าคืออะไร?
(2) ถามถึงแผนก กองธุรกิจ และกองเทคโนโลยี
ลิงค์: https://www.nowcoder.com/discuss/231656
7.16.2019: การสัมภาษณ์ทางโทรศัพท์ขัดขวางการบัฟตลอดกระบวนการทั้งหมด
1.แนะนำตัวเอง
2. ความแตกต่างระหว่าง Python และ C++ (ตอบฟีเจอร์ Python มากมาย)
3. ทำไม Python ถึงช้า?
คำตอบ: เนื่องจากฉันไม่ทราบประเภทข้อมูล ฉันจึงต้องตัดสินใจเมื่อรับข้อมูล
(1. Python เป็นภาษาที่ตีความแบบไดนามิก ค่าใน Python จะไม่ถูกเก็บไว้ในแคช แต่จะกระจัดกระจายอยู่ในวัตถุ
2. Python เป็นภาษาล่าม ต่างจาก C++ และ Java, C++ และ Java เป็นทั้งภาษาที่คอมไพล์ กล่าวคือ หลังจากที่เขียนโปรแกรม Java แล้ว คุณต้องคอมไพล์โปรแกรมต้นฉบับและสร้างไฟล์ปฏิบัติการและไฟล์คลาสก่อน หลังจากเขียนโปรแกรมด้วยภาษา Python แล้วส่งไปยังล่าม ล่ามจะแปลโค้ดบรรทัดแรกเป็นโค้ดเครื่องทันที จากนั้นส่งโค้ดบรรทัดนี้ให้ CPU เพื่อดำเนินการ จากนั้นจึงไปยังบรรทัดถัดไปแปลบรรทัดที่สอง ของโค้ดแล้วส่งให้ CPU เพื่อดำเนินการ ดังนั้น Python จะดำเนินการช้ากว่าภาษาที่คอมไพล์เหล่านั้น)
3. คุณอ่านหนังสืออะไรบ้าง (คำตอบ: การเขียนโปรแกรม Python ประสิทธิภาพสูง)
4. หน่วยความจำรั่วคืออะไร? หน่วยความจำรั่วเกิดขึ้นเมื่อใด?
ไม่ถูกลบ
(พื้นที่หน่วยความจำที่ใช้แบบไดนามิกไม่ได้ถูกปล่อยออกมาตามปกติ แต่ไม่สามารถใช้งานได้ต่อไป หน่วยความจำไม่ถูกปล่อยออกมา)
5. การปิดโปรแกรมมีเงื่อนไขว่าอย่างไร?
ไม่มีความคิด!
(อาจเป็นการปิดกระบวนการไม่แน่ใจ)
6. พอยน์เตอร์และการอ้างอิง? เมื่อใดควรใช้พอยน์เตอร์ และเมื่อใดควรใช้การอ้างอิง
(ตัวชี้ไม่จำเป็นต้องเริ่มต้น แต่การอ้างอิงจะต้องเริ่มต้นและไม่สามารถเปลี่ยนแปลงได้หลังจากการโยง ความแตกต่างระหว่างการส่งพอยน์เตอร์ไปยังฟังก์ชันและการส่งผ่านการอ้างอิงไปยังพอยน์เตอร์:
เมื่อส่งพอยน์เตอร์ ตัวชี้จะถูกคัดลอกก่อน ตัวชี้ที่คัดลอกจะถูกใช้ภายในฟังก์ชัน จะส่งผลต่อตัวชี้ดั้งเดิม
สำหรับการส่งต่อการอ้างอิงพอยน์เตอร์ หากพอยน์เตอร์ที่ส่งผ่านชี้ไปที่วัตถุใหม่ ตัวชี้ดั้งเดิมก็จะชี้ไปที่วัตถุใหม่ด้วย ซึ่งจะทำให้หน่วยความจำรั่วไหล เนื่องจากตำแหน่งที่ชี้โดยตัวชี้ดั้งเดิมจะไม่สามารถอ้างอิงได้อีกต่อไป แม้ว่า ไม่มีพอยน์เตอร์ที่ส่งผ่านไปยังออบเจ็กต์ใหม่ แต่ปล่อยพอยน์เตอร์เมื่อฟังก์ชันสิ้นสุด จากนั้นพอยน์เตอร์เดิมจะไม่สามารถใช้งานได้อีกต่อไปเนื่องจากหน่วยความจำเดิมถูกปล่อยออกมา)
7. คุณรู้จักโครงสร้างข้อมูลเหล่านั้นหรือไม่?
คำตอบ: สแต็กรายการอาร์เรย์ฮีป
8. ฮีปคืออะไร?
คำตอบ: โดยปกติแล้ว เราใช้อาร์เรย์เพื่อจำลองฮีปเท่านั้น เราไม่ทราบโครงสร้างที่แท้จริง เราคิดว่ามันเป็นโครงสร้างข้อมูลในสถานะของโหนดหลัก-ลูก (ปัญหาความถี่สูงพิเศษ ซึ่งโดยทั่วไปจะมีการจัดสรรและเผยแพร่ โดยโปรแกรมเมอร์ หากโปรแกรมเมอร์ไม่เผยแพร่มันอาจถูกเรียกคืนโดยระบบปฏิบัติการ (ระบบปฏิบัติการ) เมื่อโปรแกรมสิ้นสุด วิธีการจัดสรรจะคล้ายกับการเติบโตที่เพิ่มขึ้นของรายการที่เชื่อมโยง สแต็กจะถูกแบ่งและเปิดในขณะที่โปรแกรมกำลังทำงาน และเคอร์เนลจะพบพื้นที่ว่างเพียงพอตามรายการลิงก์ที่จะมอบให้กับโปรแกรม หากไม่พบ ให้ทำลายหน่วยความจำที่ไร้ประโยชน์แล้วค้นหาอีกครั้ง หากต้องการรายละเอียดเพิ่มเติม โปรดสรุปด้วยตนเองและตรวจสอบข้อแตกต่างรวมถึงวิธีการสมัครด้วย , การตอบสนองของระบบ ฯลฯ )
9. ความแตกต่างระหว่างฮีปและสแต็ค
Stack เป็นพื้นที่สำหรับจัดเก็บสิ่งของต่างๆ โดยจะจัดเก็บไว้ในส่วนในสุดและออกมาจากส่วนนอกสุด (ปัญหาความถี่สูงพิเศษ จะจัดสรรเมื่อฟังก์ชันทำงานและปล่อยเมื่อฟังก์ชันสิ้นสุดลง จะถูกจัดสรรและปล่อยโดยอัตโนมัติโดย คอมไพเลอร์เพื่อจัดเก็บตัวแปรท้องถิ่นที่จัดสรรไว้สำหรับการรันฟังก์ชัน พารามิเตอร์ฟังก์ชัน ข้อมูลส่งคืน ที่อยู่ผู้ส่งคืน ฯลฯ จะถูกเปิดลง และความเร็วจะเร็วมาก หากประสิทธิภาพในเครื่องดี มันจะโต้ตอบกับรีจิสเตอร์และบันทึก ตัวชี้ PC หากมีพารามิเตอร์ฟังก์ชันจำนวนมากก็จะสร้างเฟรมสแต็กและเก็บไว้ในสแต็ก)
10. กระบวนการและเธรด
(ปัญหาความถี่สูงพิเศษ ผมอ่านสรุปหลังจากเข้าใจระบบคอมพิวเตอร์อย่างเจาะลึกแล้ว 1. กระบวนการคือโปรแกรมที่มีชีวิต โปรแกรมเป็นเพียงข้อความบางส่วน โปรแกรมที่รันอยู่คือกระบวนการซึ่งเป็นหน่วยพื้นฐานของ การจัดตารางเวลาและการจัดสรรทรัพยากรในระบบ ทรัพยากรต่างๆ รวมถึงหน่วยความจำ ฯลฯ เธรดเป็นกระบวนการที่มีน้ำหนักเบาและเป็นหน่วยพื้นฐานของการกำหนดเวลาและการจัดส่ง CPU 2 เนื่องจากกระบวนการใช้ทรัพยากร การพุชสแต็กและการป๊อปจึงช้า ดังนั้นการสลับจึงไม่ยืดหยุ่นและเธรดไม่ได้ใช้ทรัพยากร แต่เป็นเพียงทรัพยากรที่จำเป็นเท่านั้น (การเรียกซ้ำต้องกดบนสแต็กดังนั้นจึงมีทรัพยากรบางส่วน) ดังนั้นเธรดจึงสื่อสารได้ง่าย -> สื่อสารโดยตรงในหน่วยความจำที่จัดสรรโดยกระบวนการ , พร้อมกันได้ง่าย -> การสลับแบบยืดหยุ่น, เหมือนกัน ความเร็วในการสลับเธรดของกระบวนการนั้นเร็วมาก ดังนั้นโอเวอร์เฮดของเธรดจึงมีน้อย 3. พื้นที่ที่อยู่, ความเป็นอิสระของกระบวนการ, เธรดของกระบวนการเดียวกันใช้ทรัพยากรร่วมกัน และไม่ขึ้นกับเธรดของ กระบวนการอื่นๆ)
สรุปหลังเหตุการณ์: แน่นอนว่าฉันล้มเหลว ฉันมีความสุขมาก มันทำให้ฉันเข้าใจปัญหา คนที่ทำงานกับอัลกอริธึมก็ควรรู้เรื่องแบ็คเอนด์ด้วย วิศวกรในสาขาอัลกอริธึมจำเป็นต้องมีความสามารถ
ช่วยทำการบ้าน
ข้างละ 90 นาที
ทำสองคำถามก่อน:
1. ค้นหาตัวเลขสามตัวจากอาร์เรย์ และความแตกต่างระหว่างผลรวมของตัวเลขสามตัวกับค่านั้นมีค่าน้อยที่สุด
ต้องใช้เวลา O(n2) ช่องว่าง O(1)
วิธีการเขียนของฉันคือการเรียงลำดับ + พอยน์เตอร์สองครั้ง มันเป็นคำถามดั้งเดิมของ leecode ฉันไม่ได้แปรง leecode มากนัก แต่โชคดีที่วิธีแก้ปัญหาก็เหมือนกัน
ขอการเรียงลำดับโดยใช้การเรียงลำดับด่วน
2. สตริง A, B และ B ครอบครองลำดับที่สั้นที่สุดของ A (ลำดับที่สั้นที่สุดของ A รวม B ด้วย)
ผู้สัมภาษณ์และฉันต่างก็หัวเราะ เพราะ Python Slice + ในตัวดำเนินการสิ้นสุดด้วยสี่บรรทัด และผู้สัมภาษณ์ก็หัวเราะด้วย ดังนั้นเราจึงตกลงที่จะเขียนฟังก์ชันด้วยตนเองสำหรับขั้นตอนใน
ความรุนแรงจะแก้ปัญหาทุกอย่างได้
1. ข้อมูลเบื้องต้นเกี่ยวกับการแข่งขัน Kaggle (ตั้งแต่ EDA จนจบ)
2. ต้นไม้พื้นฐาน เช่น ID3C4.5 เป็นต้นไม้ไบนารีหรือหลายต้นไม้หรือไม่ คุณสมบัติที่ถูกตัดจะถูกตัดอีกครั้งหรือไม่?
คุณลักษณะแบบแยก (จำนวนส่วนแยก > 2) เป็นการจำแนกประเภทแบบหลายสาขา และแบบต่อเนื่องคือการแยกแบบไบนารี่ สามารถตัดแบบต่อเนื่องได้ แต่ไม่สามารถนำไปใช้งานได้ ขั้นแรกให้สร้างคอลเลกชัน สำรวจคุณลักษณะ และบันทึก ตำแหน่งที่ได้รับข้อมูลสูงสุดแล้วจึงแบ่งส่วนคุณลักษณะนี้ออกจากชุด ดังนั้น คุณลักษณะแบบแยกส่วนจะไม่ถูกตัดออกอีกต่อไปหลังจากตัดแล้ว โชคดีที่ฉันสามารถตัดคุณลักษณะต่อเนื่องได้อีกครั้ง ให้เข้าไปดูซอร์สโค้ดของต้นไม้ ID3 ของคนอื่นและต้นไม้อื่นๆ)
3. รู้เบื้องต้นเกี่ยวกับ BN
(มีคำถามความถี่สูงพิเศษมากมายที่สามารถแนะนำได้ สาระสำคัญของการเรียนรู้ของเครื่องคือการเรียนรู้การกระจาย โดยเฉพาะการสูญเสียการสูญเสียจากล็อก ซึ่งเทียบเท่ากับการปรับเอนโทรปีข้ามให้เหมาะสม และใช้เอนโทรปีข้ามเพื่อวัดความสอดคล้องของการกระจาย 1. การฟอกสีฟันล่วงหน้า การฝึกอย่างรวดเร็ว การไล่ระดับความอิ่มตัวเล็กน้อยที่ปลายทั้งสองของซิกมอยด์ สามารถปรับขนาด BN ให้เป็นขอบเขตเชิงเส้นได้ 2. การเรียนรู้การกระจาย การกระจายของแต่ละเลเยอร์จะเปลี่ยนไปเมื่อ NN ลึกขึ้น และการกระจายแบบบีบอัด BN ทำให้การกระจายของแต่ละเลเยอร์ใกล้เคียงกัน 3 BN ถือได้ว่าเป็นการขยายข้อมูลในระดับหนึ่ง และข้อมูลจะกระวนกระวายใจ โปรดทราบว่าในระหว่างกระบวนการฝึกอบรม BN โปรดจำไว้ว่าแบทช์ปัจจุบันถูกทำให้เป็นมาตรฐานและข้อมูลทั้งหมดเป็น ใช้สำหรับการคาดการณ์ และเลเยอร์ BN มีไฮเปอร์พารามิเตอร์สองตัวที่ต้องปรับให้เหมาะสม) 4. ต้นไม้ใดลึกกว่า GBDT หรือ RF?
RF ลึก ฉันพูดคุยเกี่ยวกับแนวคิดในการเพิ่มและบรรจุถุง Boost ใช้ตัวเรียนรู้ที่มีความแปรปรวนต่ำเพื่อให้พอดีกับค่าเบี่ยงเบน ดังนั้น XBG และ LGB จึงมีการตั้งค่าพารามิเตอร์สำหรับความลึกของต้นไม้ RF คือความแปรปรวนที่เหมาะสม โดยจะตัดตัวอย่างและคุณสมบัติเพื่อสร้างชุดตัวอย่างที่หลากหลาย และต้นไม้แต่ละต้นจะไม่ถูกตัดออกด้วยซ้ำ
5. ความสำคัญของคุณสมบัติ XGB ได้รับการตัดสินอย่างไร?
คำตอบ: ไม่แน่ใจ แต่ใช้บ่อยมาก ฉันเดาว่ามันขึ้นอยู่กับจำนวนจุดแยก (จำนวนที่เกิดขึ้นในทรีทั้งหมด) นั่นคือทั้งหมดที่ฉันพูด
(กำไรที่ได้รับหมายถึงการมีส่วนร่วมแบบสัมพัทธ์ของคุณลักษณะที่เกี่ยวข้องกับแบบจำลอง ซึ่งคำนวณโดยการนำคุณลักษณะแต่ละอย่างมาใช้กับแต่ละแผนภูมิในแบบจำลอง ค่าที่สูงกว่าของการวัดนี้เมื่อเปรียบเทียบกับคุณลักษณะอื่น ๆ หมายความว่าสิ่งสำคัญสำหรับการสร้าง การพยากรณ์มีความสำคัญมากกว่า .
ครอบคลุม เมตริกความครอบคลุมอ้างอิงถึงจำนวนการสังเกตการณ์ที่เกี่ยวข้องกับคุณลักษณะนี้โดยสัมพันธ์กัน ตัวอย่างเช่น หากคุณมีการสังเกต 100 รายการ คุณลักษณะ 4 รายการ และแผนภูมิ 3 รายการ และสมมติว่าคุณลักษณะ 1 ใช้ในการตัดสินใจโหนดใบสำหรับการสังเกต 10, 5 และ 2 รายการในแผนภูมิที่ 1 แผนภูมิที่ 2 และแผนภูมิที่ 3 ตามลำดับ หน่วยเมตริกนี้จะคำนวณ ความครอบคลุมของฟังก์ชันนี้เป็น 10 5 2 = 17 การสังเกต ข้อมูลนี้จะถูกคำนวณสำหรับฟีเจอร์ทั้ง 4 รายการ และจะแสดงเมตริกความครอบคลุมของฟีเจอร์ทั้งหมดเป็นเปอร์เซ็นต์ที่ 17
ความถี่ความถี่ (ความถี่) คือเปอร์เซ็นต์ที่แสดงถึงจำนวนสัมพัทธ์ของครั้งที่คุณลักษณะเฉพาะเกิดขึ้นในแผนผังโมเดล ในตัวอย่างข้างต้น หากฟีเจอร์ 1 เกิดขึ้นใน 2 แยก 1 แยกและ 3 แยกในแต่ละแผนภูมิ 1 แผนภูมิ 2 และแผนภูมิ 3 ดังนั้นน้ำหนักของคุณลักษณะ 1 จะเป็น 2 1 3 = 6 ความถี่ของจุดสนใจ 1 คำนวณเป็นเปอร์เซ็นต์น้ำหนักเหนือน้ำหนักของจุดสนใจทั้งหมด -
6. XGB นั้นง่ายต่อการเข้าใจการถดถอยและการจำแนกประเภทไบนารี่
คุยกันไปหัวเราะไป ผมตอบ label encode ตอนแรกว่าใช้ onehot+softmax แต่จะทำยังไงให้พอดีกับ tree ก่อน softmax หนึ่งขั้น ฉันไม่รู้เรื่องนี้จริงๆ ผู้สัมภาษณ์ให้ฉันพูดเป็นสามประเภทว่าจะสร้าง 100 ต้นหรือ 300 ต้น ฉันตระหนักได้และตอบว่าฉันคิดว่าเป็น 100 ต้น
ผู้สัมภาษณ์บอกว่าให้สร้างต้นไม้ 300 ต้น ให้พอดี 3 ประเภท ตามด้วยซอฟต์แม็กซ์
(หลังจาก onehot ป้ายอินพุตจะเป็นเวกเตอร์ และกลุ่มของต้นไม้จะถูกรวมเข้าด้วยกันสำหรับแต่ละจุดทำนายในเวกเตอร์)
55 นาที ทั้งสองฝั่ง
1. ก่อนอื่นผมขอถามก่อนว่าคุณเรียนวิชาเอก NLP หรือไม่
ไม่ ในทิศทางของอัลกอริธึม เราพูดถึงโครงการในห้องปฏิบัติการ และใช้อัลกอริธึม NN ของรูปภาพจำนวนมาก
2. คำถามสามข้อ
คำถามที่ 1: จำนวนที่ใหญ่ที่สุด Kth
มีการอภิปรายสามวิธี
วิธีที่ 1: ความซับซ้อนของการวิเคราะห์การเรียงลำดับฮีปคือ O(Nlogk) (การวิเคราะห์ถูกต้อง)
วิธีที่ 2: ความซับซ้อนของการวิเคราะห์ไบนารี่แบบเรียงลำดับด่วนคือ O(N)
วิธีที่ 3: การเรียงลำดับความซับซ้อนในการวิเคราะห์ตารางการค้นหา (NLogN)
ข้อกำหนดคือ O(N) ดังนั้นฉันจึงใช้การเรียงลำดับอย่างรวดเร็วเป็นสองประเด็น ผู้สัมภาษณ์กล่าวว่าการเรียงลำดับอย่างรวดเร็วสามารถแก้ปัญหานี้ได้? แต่การเรียงลำดับอย่างรวดเร็วนั้นเร็วที่สุด (ที่ฉันรู้) และเป็นความซับซ้อนของ O (n) ที่จำเป็น
(หลังจากค้นหา Baidu การเรียงลำดับอย่างรวดเร็วและการแฮชนั้นเร็วที่สุดในขณะที่ส่วนที่เหลือไม่เร็ว)
ฉันเขียนรหัส Python ด้วยมือ แต่ฉันไม่รู้ว่ามีอะไรผิดปกติในการรวบรวม ดังนั้นฉันจึงบอกว่าควรเขียนคำถามต่อไปนี้ใน C ++ (ปัญหานี้ร้ายแรงมากฉันไม่พบข้อบกพร่องใด ๆ ในระหว่างการสัมภาษณ์ดังนั้นฉันต้องระวังเกี่ยวกับ Python และตรวจสอบให้แน่ใจ ใช้ C ++ เสมอ)
คำถามที่สอง:
ชั้น N 3, กระดาน 1 3, การเตรียมการหลายอย่าง
dp [n] = dp [n-1]+dp [n-3]
คำถามที่ 3:
ความน่าจะเป็นเท่ากัน 1-7
สร้างความน่าจะเป็นที่เท่ากัน 1-10 วิเคราะห์จำนวนการโทรที่คาดหวัง 1-7
7 ฐานโทรสองครั้งเพื่อสร้าง 0-48 จากนั้นตัดทอน 40 และสูงกว่า 40 แล้ว // 4 1
ความคาดหวังไม่ใช่เรื่องง่ายที่จะคำนวณ
เมื่อคิดเกี่ยวกับเรื่องนี้ผู้สัมภาษณ์อาจอยู่ภายใต้แรงกดดันดังนั้นฉันจึงถามการเรียงลำดับอย่างรวดเร็ว . ไม่ควรมีปัญหากับระดับของผู้สัมภาษณ์ (PS: อย่าคิดว่าความสามารถของผู้สัมภาษณ์ไม่ดีผู้สัมภาษณ์ส่วนใหญ่ทำได้ดี) ขอบคุณ
มีประสิทธิภาพมากฉันมีการสัมภาษณ์หนึ่งวันหลังจากส่งประวัติย่อของฉัน
การสัมภาษณ์ครั้งแรกเป็นไปอย่างราบรื่นและการสัมภาษณ์ครั้งที่สองใช้เวลาหนึ่งร้อยนาที
ด้านหนึ่ง: มันราบรื่นมากที่ฉันไม่ได้บันทึกอะไรในสมุดบันทึกของฉัน คำถามแรก LIS: ฉันไม่ได้ทำอะไร n^2) วิธีการเขียน ฉันลืมคำถามที่สองดังนั้นฉันจึงจบทั้งสองด้านในหนึ่งนาที: พวกเขาทั้งหมดเป็นคำถามที่เปิดกว้างไม่มีคำตอบมาตรฐานระยะเวลาคือ 100 นาทีและเนื้อหาส่วนใหญ่เกี่ยวกับสถานการณ์การแนะนำและการแข่งขันที่แท้จริง? ฉันได้พูดคุยเกี่ยวกับงานของฉันในแต่ละขั้นตอนและงานของฉันในแต่ละขั้นตอน (ถูกต้องสิ่งที่ผู้สัมภาษณ์ต้องการได้ยินอาจเป็นงานของฉันในขั้นตอนต่าง ๆ ปัญหาที่ฉันพบความคิดและการแก้ปัญหาของฉัน) คุณคิดว่าคุณวัดความพึงพอใจของผู้ใช้กับผลการค้นหาได้อย่างไร ใต้. ฉันอยู่ทางใต้เกินไป แต่ฉันได้พูดคุยเกี่ยวกับเวลาการเชื่อมต่อ TCP การกรองเสียงรบกวนตามเวลาเช่นฉากวิดีโอโดยใช้เวลาเปอร์เซ็นไทล์ของความยาววิดีโอประสิทธิภาพของวินาทีกลับ ฯลฯ ผู้สัมภาษณ์สามารถพอใจกับสิ่งนี้ จากนั้นฉันก็ทำให้สมองของฉันไม่สามารถนึกถึงคุณสมบัติที่ดีอื่นได้ดังนั้นฉันจึงใช้คุณสมบัติที่อ่อนแอเช่นความสัมพันธ์ของ quary และอื่น ๆ ผู้สัมภาษณ์ไม่พอใจเพราะสิ่งเหล่านี้ส่วนใหญ่บ่งบอกถึงความสนใจของผู้ใช้มากกว่าความพึงพอใจ คุณคิดว่าเราสามารถแก้ปัญหาการผลักดันผลการค้นหาใหม่ได้อย่างไร คำตอบ: ผลการค้นหาใหม่จะต้องมีประวัติการผลักดัน 0 และไม่มีการอ้างอิง แต่เราไม่รู้ว่าคุณภาพของพวกเขาคืออะไร ดังนั้นเขาจึงผลักมันไปยังผู้ใช้จำนวนน้อยเพื่อส่งเสริมการขาย เมื่อโปรโมตให้ความสนใจกับปรากฏการณ์ของการเพิ่มอัตราการคลิกผ่านกรองมัน blah blah blah ผู้สัมภาษณ์พอใจมาก คุณคิดอย่างไรกับฉากและนางแบบ? โดยส่วนตัวฉันให้ความสนใจเป็นอย่างมากกับฉากเริ่มต้นจากประสบการณ์การวิจัยทางวิทยาศาสตร์ของฉันเองพูดคุยเกี่ยวกับการแนะนำหนังสือแตงโมและบอกการเดินทางทางจิตที่สมบูรณ์ของฉัน ผู้สัมภาษณ์สามารถพอใจ ฉันลืมคำถามบางอย่างมีหลายอย่างที่ฉันสูญเสียเสียงหลังจากพูดถึงพวกเขา แต่คำแนะนำของผู้สัมภาษณ์นั้นเป็นข้อมูลจริง ๆ และสงสัยเกี่ยวกับชีวิต เมื่อผู้สัมภาษณ์วิพากษ์วิจารณ์ฉันแบบนี้ฉันอยากไป Baidu เพราะเขาเอาชนะฉันได้
ไม่มีคำแนะนำภายในและประวัติย่อที่เขียนโดยตรงบนเว็บไซต์ทางการดูเหมือนว่าจะสัมภาษณ์ใน 1 หรือ 2 วัน แต่ - เดิมทีเป็น บริษัท โปรดของฉัน แต่ตอนนี้มันไม่ได้อีกต่อไป การสรรหาโรงเรียน Tencent
แผนกที่ตั้งใจ TEG โทรโดยตรง: โพสต์การวิจัย
แนะนำตัวเองและพูดคุยเกี่ยวกับโครงการ
คุณสนใจในส่วนของเรา: สาขาการตรวจจับบันทึกการบันทึกแผนก
เข้าใจซึ่งกันและกัน
เรามีการประชุมมาคุยกันต่อไปในครั้งต่อไป
10 นาฬิกา: พูดต่อเกี่ยวกับสิ่งที่เราพูดถึงครั้งสุดท้าย
กระบวนการทั้งหมดค่อนข้างผ่อนคลายและสนุกสนาน
การประชุมครั้งที่สองสิ้นสุดลง แต่สถานะยังคงมีการประชุมครั้งที่สอง - -
พูดคุยกับผู้สัมภาษณ์วิธีการใช้วิธีการเรียนรู้ของเครื่องเพื่อจัดการการตรวจจับบันทึกอันตราย การทบทวนความรู้ที่สำคัญที่เรียนรู้ตั้งแต่ต้นถือว่าเป็นการสะท้อนตนเอง ประสบการณ์ที่โดดเด่นมากขึ้นที่สามารถรับได้ที่นี่คือหลายแผนกยังคงมุ่งเน้นไปที่การเรียนรู้กฎและมีข้อกำหนดการตีความที่แข็งแกร่งสำหรับสถานการณ์การจำแนกประเภทการเรียนรู้ของเครื่อง ดังนั้นแบบจำลองที่มีการตีความที่ดีเช่นแบบจำลองต้นไม้และ LR จึงเป็นที่นิยมมาก แต่ในที่สุดผู้สัมภาษณ์ "ขอบคุณ" ฉันอาจหมายความว่าฉันล้มเหลวร้องเพลงซิน
ฉันได้รับแจ้งว่าฉันได้รับ A ใน 3 และครึ่งหนึ่งของคำถามห้าข้อในการสอบข้อเขียนและคะแนนของฉันก็โอเค แต่แผนกล็อคประวัติย่อของฉัน - -
ฉันแจ้งทั้งสองฝ่ายและหลังจากนั้นไม่กี่นาทีพวกเขาก็คุยกันอย่างไม่เป็นทางการและบอกว่าพวกเขาจะพบกันต่อไปในเดือนกันยายน
กระบวนการปัจจุบันสิ้นสุดลงและฉันรู้สึกสบายใจ ฉันต้องรับสมัครเอ็มม์กี่คน ~
Pinduoduoduo ขอบคุณจดหมาย
ด้านหนึ่ง:
แนะนำตัวเอง
โครงการวิจัยทางวิทยาศาสตร์เบื้องต้น
บทนำการแข่งขัน Kaggle
บทนำการแข่งขัน Tencent
คุณเคยใช้ RNN หรือไม่?
คุณใช้ LR หรือไม่
ความแตกต่างระหว่าง XGB และ LGB:
ฉันคิดแค่สามจุดการเรียงลำดับคุณสมบัติการแบ่งส่วนคุณสมบัติฮิสโตแกรมและการเรียงลำดับเต็ม
เขาบอกว่าพวกเขามีความเหมือนกันมากขึ้นและพูดถึงเล็กน้อย XGB ไม่ด้อยกว่า LGB แต่การปรับโสมนั้นไม่ง่ายต่อการจัดการและ LGB นั้นเร็วมาก
-
1) ความเร็วในการฝึกอบรมที่เร็วขึ้นและประสิทธิภาพที่สูงขึ้น: LightGBM ใช้อัลกอริทึมที่ใช้ฮิสโตแกรม
2) การเร่งความเร็วความแตกต่างของฮิสโตแกรม: ฮิสโตแกรมของโหนดเด็กสามารถรับได้โดยการลบฮิสโตแกรมของโหนดพี่น้องจากฮิสโตแกรมของโหนดหลักจึงเร่งการคำนวณ
3) การใช้หน่วยความจำที่ต่ำกว่า: การใช้ถังขยะแบบแยกเพื่อประหยัดและแทนที่ค่าต่อเนื่องส่งผลให้การใช้หน่วยความจำน้อยลง
4) ความแม่นยำที่สูงขึ้น (เมื่อเทียบกับอัลกอริทึมการปรับปรุงอื่น ๆ ): ใช้วิธีการแยกใบที่ชาญฉลาด (เลือกโหนดที่มีกำไรแยกใหญ่ที่สุดในโหนดใบปัจจุบันทั้งหมดสำหรับการแยกและอื่น ๆ วิธีนี้ง่ายต่อการฟล็อกซ์เพราะมันง่ายที่จะตกอยู่ในความลึกที่ค่อนข้างสูงดังนั้นจึงจำเป็นต้องวัดความลึกสูงสุด (เพื่อหลีกเลี่ยงการ overfitting) ซึ่งทำให้เกิดการแยกจากกันในแต่ละโหนดในแต่ละชั้น ซึ่งเป็นปัจจัยหลักในการบรรลุความแม่นยำที่สูงขึ้น อย่างไรก็ตามบางครั้งมันอาจนำไปสู่การ overfitting แต่เราสามารถป้องกันการติดตั้งมากเกินไปโดยการตั้งค่า | max-depth
5) ความสามารถในการประมวลผลข้อมูลขนาดใหญ่: เมื่อเทียบกับ XGBOOST เนื่องจากการลดลงของเวลาฝึกอบรมมันยังสามารถมีความสามารถในการประมวลผลข้อมูลขนาดใหญ่
6) สนับสนุนการเรียนรู้แบบขนาน
7) การสุ่มตัวอย่างในท้องถิ่น: เก็บตัวอย่างที่มีการไล่ระดับสีขนาดใหญ่ (ข้อผิดพลาดขนาดใหญ่) และตัวอย่างตัวอย่างที่มีการไล่ระดับสีขนาดเล็กซึ่งจะช่วยลดจำนวนตัวอย่างและเพิ่มความเร็วในการคำนวณ
-
สำหรับคำถามที่เกี่ยวข้องกับรหัสเพียงแค่ขอให้ผู้สัมภาษณ์เลือก C ++ หรือ Python
ทางเลือกของฉันคือ Python
มีชิ้นส่วนหมากรุกบนกระดานหมากรุก
dp [i] [j] = สูงสุด (dp [i-1] [j], dp [i] [j-1])
ถ้าหมากรุก [i] [j] == 'หมากรุกชิ้น':
dp [i] [j] = 1
Ermian: ฉันเดาว่ามันเจ๋งไม่ใช่คำตอบที่ดี
ผู้สัมภาษณ์คนอื่นที่มีการขัดจังหวะในตัวกำลังยุ่งกับความคิดของฉัน
1. GBDT และ XGB
(GBDT, XGB และ LGB จะต้องเชี่ยวชาญในทุกโครงการที่กล่าวถึง)
2. BN, DROPOUT
(การออกกลางคันสามารถใช้เป็นเคล็ดลับทางเลือกสำหรับการฝึกอบรมเครือข่ายประสาทลึกในแต่ละชุดการฝึกอบรมโดยไม่สนใจครึ่งหนึ่งของเครื่องตรวจจับคุณสมบัติ (ปล่อยให้ครึ่งหนึ่งของโหนดเลเยอร์ที่ซ่อนอยู่มีค่า 0 แน่นอนว่า "ครึ่ง" นี้คือ Hyperparameter การตั้งค่าตัวเอง) สามารถลดปรากฏการณ์ที่มากเกินไปได้อย่างมีนัยสำคัญ
การออกกลางคันหมายถึง: ในระหว่างการแพร่กระจายไปข้างหน้าเราปล่อยให้ค่าการเปิดใช้งานของเซลล์ประสาทบางตัวหยุดทำงานกับความน่าจะเป็น p
ในความเป็นจริงมันเป็นกลยุทธ์การบรรจุถุงเพื่อสร้างการรวมกันของซับเน็ต -
3. ทำไมคุณไม่ใช้ LR ก่อน (ทำไมต้องใช้ LR อย่างง่าย หนาขึ้น 4. จะแยกแยะคุณสมบัติการแข่งขันของ Tencent ได้อย่างไร? Bucketing นั้นยิ่งกว่านั้น คุณสมบัติอย่างต่อเนื่องจะถูกข้าม 5. คุณรู้จัก AUC หรือไม่?
ฉันไม่รู้วิธีการคำนวณ
(ไม่มีสิ่งเช่น AUC สำหรับการถดถอย)
6. อันไหนเร็วกว่าในการพัฒนากองหรือสแต็ก?
MMP ตรงกันข้ามกับสิ่งที่เขาพูดอย่างสมบูรณ์และใช้เวลานานในการตระหนักถึงสิ่งที่เขาพูด สิ่งที่ฉันกำลังพูดถึงคือการจัดสรรกองในระหว่างการรวบรวมดังนั้นจึงไม่จำเป็นต้องขยายหรือหดตัวอะไรเลย คำตอบที่ไม่ถูกต้อง)
7. โอเวอร์โหลดและเขียนใหม่
(โปรดทราบว่าการเขียนใหม่เป็นการเขียนฟังก์ชั่นเสมือนจริงใหม่ฉันตอบผิดในเวลาที่เรียกว่าโอเวอร์โหลดหมายความว่ารายการพารามิเตอร์ของฟังก์ชั่นที่มีชื่อเดียวกันแตกต่างกันฟังก์ชั่นจะถูกเปลี่ยนชื่อในระหว่างการรวบรวม พวกเขาไม่มีชื่อเดียวกันอีกต่อไปเมื่อทำงาน; )
8. วิธีใช้ข้อมูลขนาดใหญ่เพื่อค้นหารายการช้อปปิ้งยอดนิยม 100 รายการ
สร้างกองแฮชขนาดเล็ก
9. วิธีการสร้างชั้นล่างของแผนที่
ฉันบอกว่าฉันยังไม่ได้ดูรหัสพื้นฐาน (โดยวิธีการที่ฉันไม่เคยรู้เลยว่ามีอะไรเช่นแผนที่ฉันเพิ่งทำตารางแฮชด้วยมือฉันวางแผนที่จะดูการวิเคราะห์ซอร์สโค้ด STL เมื่อฉันมีเวลา)
(ต้นไม้สีแดงดำพื้นฐาน, O (log (n) การค้นหา, การแทรกและโครงสร้างข้อมูลการลบ)
สำหรับความซับซ้อนของดัชนีฉันพูดว่าบันทึก (n)
10. มี O (1) หรือไม่? ทันใดนั้นมันก็เริ่มที่ฉันว่ามีตารางแฮชหลังจากที่ฉันเช็ดมัน
จะทำอย่างไรถ้ามีความขัดแย้งในตารางแฮช
ตอบโดย Zip Heavy Hash ปัจจุบัน 1
(ปัญหาความถี่สูงเหมือนกันซิป: รายการที่เชื่อมโยงความขัดแย้งอยู่ที่ส่วนท้ายของรายการที่เชื่อมโยงการตรวจจับ: การตรวจจับเชิงเส้นการตรวจจับรองเช่นค่าปัจจุบัน 1; การแฮชใหม่: ฟังก์ชั่นแฮชหลายรายการ)
ที่จริงแล้วฉันไม่ค่อยเก่งเรื่อง STL ฉันไม่ชอบใช้ฟังก์ชั่นไลบรารี STL ซึ่งทำให้ฉันไม่ค่อยเก่งใน STL รอสักครู่เพื่ออ่านคลื่นของการวิเคราะห์ซอร์สโค้ด STL
mogujie
ประสบการณ์การสัมภาษณ์ดีมากการสัมภาษณ์ครั้งแรกและครั้งที่สองเป็นไปอย่างราบรื่นและ HR นั้นดีมาก เมื่อฉันได้รับการแจ้งเตือนการสัมภาษณ์เป็นครั้งแรกเมื่อฉันเปิดลิงค์มันเป็นอินเทอร์เฟซมีเวลาสัมภาษณ์กล่องแก้ไขได้ปุ่มตกลงและปุ่มยอมแพ้ การอ่านพรอมต์: หากคุณคลิกตกลงเวลาจะไม่สามารถเปลี่ยนแปลงได้ ฉันไม่กล้าที่จะคลิกปุ่มเลิกดังนั้นฉันจึงโทรหาฝ่ายทรัพยากรบุคคลและถามและพวกเขาบอกว่าฉันสามารถยอมแพ้ได้ในเวลาที่ฉันต้องการ ในระหว่างการสัมภาษณ์ครั้งที่สองพรอมต์ในช่องนี้เปลี่ยนเป็นถ้าคุณคลิกตกลงเวลาไม่สามารถเปลี่ยนแปลงได้หากเวลาไม่เหมาะสมโปรดเขียนเวลาที่เหมาะสมและคลิกยกเลิก ฉันรู้สึกว่าฝ่ายทรัพยากรบุคคลนั้นดีมากดังนั้นฉันจึงแสดงความพึงพอใจการสนับสนุนและความซาบซึ้งในการทำงานของฝ่ายทรัพยากรบุคคลในระหว่างการสัมภาษณ์ครั้งที่สอง ดังนั้นฉันรู้สึกว่าถ้าการสัมภาษณ์ HR ผ่านไปแล้วสิ่งเดียวที่เหลืออยู่คือการสัมภาษณ์ข้าม
แต่ฉันกำลังพูดความจริงฉันชอบ HR ของพวกเขาจริงๆ
แนะนำตัวเองสองคำถาม
หลักสูตรแรก:
จำนวนนายกที่ใหญ่ที่สุดภายใน 1,000
มีการกล่าวกันว่า Python สามารถใช้เครื่องกำเนิดไฟฟ้าและวิธีการคัดกรองในพื้นที่ O (1) แต่ยังไม่ได้เขียนและจะไม่ถูกเขียนหากไม่มีข้อกำหนด ตามลำดับจากขนาดใหญ่ถึงเล็ก
ความซับซ้อนในการวิเคราะห์วิธีลดความซับซ้อน? ค้นหาจากบนลงล่างเริ่มต้นจาก 999 และลงหยุดเมื่อพบ -2 ในแต่ละครั้ง การตัดสินบูลเริ่มต้นจาก 2 ถึงหมายเลขรูท x, โมดูโลทั้งหมด, ไม่ใช่ 0 จะกระโดดออกไปเป็นเท็จ แต่ดูเหมือนว่าผู้สัมภาษณ์ไม่รู้จัก Python? ดังนั้นฉันจึงเปลี่ยนเป็น C ++ สำหรับคำถามถัดไป
หลักสูตรที่สอง:
การใช้งานส่วนที่ไม่มีการแบ่งเป็นเรื่องง่ายมาก
โปรดทราบว่าในการเขียนของฉัน ABS (จำนวนลบ) ใน C ++ อาจล้น แต่ไม่สำคัญว่าความเร็ว A จะสำคัญกว่าในระหว่างการสัมภาษณ์
ในระหว่างการทดสอบเป็นลายลักษณ์อักษรฉันเพิ่งเตรียมตัวสำหรับการเพิ่มประสิทธิภาพแบบไบนารีและหัวข้อถัดไปเกิดขึ้น
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 29 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
#include <iostream>
using namespace std;
int jianfa(int num1,int num2)
{
int re = 0;
bool fuhao = false;
if ((num1<0 && num2<0) || (num1>0 && num2>0))
{
fuhao = true;
}
num1 = abs(num1);//小心溢出
num2 = abs(num2);//小心溢出
if(num2==0)
{
cout<<"div zero error"<<endl;
return 0x3f3f3f3f;
}
if(num1<num2)
return 0;
int tmp=1;
while(num1>num2)
{
tmp*=2;
num2*=2;
}
num2/=2;
tmp/=2;
while(num2)
{
if(num1>=num2)
{
num1-=num2;
re =tmp;
}
num2/=2;
tmp/=2;
}
if(fuhao)
return re;
else
return -re;
}
int main() {
int num1,num2;
cin>>num1>>num2;
cout<<jianfa(num1,num2);
return 0;
}
ถามคำถามมากมาย:
ฉันจำพวกเขาไม่ได้และสูญเสียความทรงจำ -
1. ทำไมคุณไม่มีประสบการณ์การฝึกงาน?
ประเด็นแรกคือครูไม่อนุญาตให้ฉันหางานทำ (นี่คือความจริงวันนี้ครูพูดกับเพื่อนร่วมชั้นคนอื่นคุณพบงานหรือไม่ถ้าคุณพบงาน แต่ไม่สามารถจบการศึกษาได้คุณคิดว่างานของคุณไร้ประโยชน์ ... )
ประเด็นที่สองคือเพื่อที่จะได้สัมผัสกับวิศวกรรมจริงฉันได้เข้าร่วมการแข่งขันนอกเหนือจากการวิจัยทางวิทยาศาสตร์ Blah Blah Blah ผู้สัมภาษณ์สามารถพอใจ
2. คุณเคยใช้ LR หรือไม่?
จำเป็น
3. LGB ดีกว่า XGB หรือไม่?
แนะนำความแตกต่างโดยตรงระหว่างทั้งสอง
4. L1 และ L2 แตกต่างกันหรือไม่? ทำไม L1 ถึงกระจัดกระจาย?
จากมุมมองการแจกแจงทางคณิตศาสตร์หนึ่งคือการกระจาย Laplace และอื่น ๆ คือการแจกแจงแบบเกาส์เซียน วิศวกรรมพูดคุยเกี่ยวกับการได้มาโดยประมาณของ L1 และการเพิ่มประสิทธิภาพภายในช่วงเวลา 0 และนอกช่วงเวลา จากนั้น L2 นั้นค่อนข้างง่ายที่จะได้รับโดยตรง
5. ผู้เรียนคนไหนนูนและเหนือกว่า?
LR sigmoid logloss เป็นนูน การถดถอยเชิงเส้น, การเพิ่มประสิทธิภาพของสี่เหลี่ยมจัตุรัสน้อยที่สุด SVM เป็นนูนและเหนือกว่า NN ไม่ได้นูนแน่นอนเพราะมันมักจะมาบรรจบกันที่จุดอาน PCA มีโซลูชันทางคณิตศาสตร์นับไม่ถ้วน แต่การใช้ค่าลักษณะเฉพาะสามารถหาทางออกที่ดีที่สุดได้
(โปรดทราบว่าการสูญเสีย Sigmoid กำลังสองไม่ใช่การเพิ่มประสิทธิภาพนูน)
6. คุณวัดความสำคัญของคุณสมบัติเช่นการผสมผสานคุณสมบัติและการลบและคุณจะปรับพารามิเตอร์ได้อย่างไร?
คำตอบ: ใช้ OneHot Cross-Embeding สำหรับการผสมผสานคุณสมบัติ การรวมกันขึ้นอยู่กับการกระจายที่แท้จริง .
การลบคุณสมบัติและด้านอื่น ๆ ทำให้ฉันนึกถึงขั้นตอนการคัดกรองคุณสมบัติของเจ้านาย Kaggle บางคน
ปรับพารามิเตอร์:
ขั้นตอนแรกคือพารามิเตอร์ของบรรพบุรุษ ตัวอย่างเช่นความลึกของแบบจำลองต้นไม้ความถี่การสุ่มตัวอย่าง ฯลฯ ส่วนใหญ่ขึ้นอยู่กับประสบการณ์
ขั้นตอนที่สองคือการปรับพารามิเตอร์เช่นการลองใช้คุณสมบัติใหม่
7. คุณรู้ฟังก์ชั่นการเปิดใช้งานกี่ฟังก์ชั่น?
ฉันบอกว่าฉันจะไม่พูดถึง Sigmoid Tanh Relu ที่ง่ายที่สุด
8. จุดอานคืออะไร?
ทำไมฉันถึงพูดอย่างนี้อย่างโง่เขลาและจากนั้นฉันก็บอกว่าฉันลืมไปแล้ว แต่มันไม่ใช่จุดที่ดีที่สุดในท้องถิ่น
(เป็นที่เข้าใจกันดีกว่าด้วยภาพของจุดอานโปรดทราบว่าทิศทางเดียวขึ้นไปดังนั้นจึงง่ายที่จะเลื่อนจากด้านบนไปยังจุดอานม้าบนสไลด์ทิศทางอื่น ๆ จะลงไปดังนั้นคุณสามารถลงไปได้ สไลด์ แต่การไล่ระดับสีที่นี่ที่จุดอานคือ 0 ซึ่งแบน จุด) ในสมการที่แตกต่างกันจุดเอกพจน์ที่มีความเสถียรในทิศทางเดียวและไม่เสถียรในทิศทางอื่นเรียกว่าจุดอาน
จุดวิกฤติเรียกว่าจุดอาน ในเมทริกซ์ตัวเลขที่มีค่าสูงสุดในแถวและค่าต่ำสุดในคอลัมน์เรียกว่าจุดอาน ในฟิสิกส์มันกว้างขึ้นและหมายถึงจุดที่ค่าสูงสุดอยู่ในทิศทางเดียวและค่าต่ำสุดอยู่ในทิศทางอื่น
การพูดในวงกว้างเส้นโค้งพื้นผิวหรือ hypersurfaces ในละแวกใกล้เคียงของจุดอานของฟังก์ชั่นที่ราบรื่น (เส้นโค้งพื้นผิวหรือ hypersurface) ทั้งหมดตั้งอยู่ในด้านต่าง ๆ ของแทนเจนต์จนถึงจุดนี้ -
ก่อนอื่นให้ฉันถามว่าคุณเคยใช้ RNN หรือไม่
คำตอบ: ผล RNN ของโครงการวิเคราะห์ว่า RNN ไม่ดีในโครงการหรือไม่และผลระยะแรกของ RNN ในการแข่งขัน (เอฟเฟกต์ระยะแรกดีที่สุด)
คุณเคยใช้ GRU หรือไม่?
คำตอบ: GRU ถูกใช้ครั้งเดียว ประตูหน่วยความจำที่ใช้ช่วยให้มั่นใจได้ว่าการส่งหน่วยความจำระยะยาว
9. ความสนใจคืออะไร?
คำตอบ: ฉันพูดถึงก่อนหน้านี้ว่าฉันเคยใช้ความสนใจ แต่ฉันเคยใช้มันมาก่อนและไม่ทราบหลักการ
(ในฐานะที่เป็นตัวปรับโสมฉันได้ลองเครือข่ายต่าง ๆ แต่ฉันก็ยังไม่เข้าใจธรรมชาติของความสนใจความสนใจคือสิ่งที่คุณต้องการ?)
10. ทำไมการออกกลางคันจึงป้องกันไม่ให้มีการ overfitting?
จากมุมมองของการบรรจุถุง NN เป็นผู้เรียนที่มีค่าเบี่ยงเบนเล็ก ๆ และความแปรปรวนขนาดใหญ่
11. การกรองความร่วมมือ:
เขาบอกว่าเขาเข้าใจ แต่ไม่เคยเขียนโค้ด
(การกรองความร่วมมือฉันรู้สึกว่าหากนักเรียนมีส่วนร่วมในการวิจัยทางวิทยาศาสตร์เป็นหลักมันก็ยังยากที่จะติดต่อถ้าคุณสนใจคุณสามารถค้นหาได้โดยเฉพาะอย่างยิ่งเมื่อพูดถึงวิศวกรแนะนำผลิตภัณฑ์อีคอมเมิร์ซ ยังคงถามได้ง่าย)
12. สิ่งที่ใช้ในการประเมิน CTR?
เมื่อฉันพูดถึง LR และ FM ฉันได้เขียนรหัส FM เป็นส่วนใหญ่ NFM
13. Mogu Street คืออะไร?
คำตอบ: ขายเสื้อผ้า ดังนั้นเขาจึงแนะนำ Mogujie ให้เป็นอีคอมเมิร์ซและการสตรีมสดเป็นหลัก (ฉันเกือบจะหัวเราะเมื่อได้ยินการถ่ายทอดสดฉันไม่สามารถถือมันได้อีกต่อไปดังนั้นฉันจึงรู้สึกมีความสุขอย่างลึกลับจากนั้นเมื่อเขาเห็นว่าฉันไม่สามารถถือมันได้อีกต่อไป โมดูลที่เติบโตเร็วที่สุดบนถนน Mogu)
มันเป็นไปด้วยดีฉันไม่ได้รหัสเพราะฉันไม่มีเวลาพอที่จะพบกันครึ่งชั่วโมง
มีการใช้งานซอฟต์แวร์ที่สมบูรณ์ในโครงการของฉันและส่วนหลักที่ฉันรับผิดชอบเกินกว่า 10,000 บรรทัดของรหัส
ในความเป็นจริงฉันสามารถทำการเข้ารหัสแบบแมนนวลส่วนใหญ่ (ยกเว้นสตริงซึ่งเป็นจุดอ่อนของฉัน)
แนะนำโครงการและพูดคุยเกี่ยวกับรายละเอียดของโครงการ
ในโครงการการผสมผสานคุณสมบัติในฟิลด์การเข้ารหัสล้วนเป็น XOR ดังนั้นการใช้ relu bn เพื่อแยกคุณสมบัติ BN เป็นการปรับปรุงที่ยิ่งใหญ่จริงๆ
พูดคุยเกี่ยวกับหลักการ BN สูตรและการดำเนินการ
(คุณสามารถตรวจสอบซอร์สโค้ด BN ได้ไม่นาน)
ทำไมต้องใช้ BN เพื่อบีบอัดส่วนบวกของแผนที่หลังจาก XOR แทนที่จะเป็นบางสิ่ง (ไม่ได้ยินชัดเจน)
ฉันบอกว่าเลเยอร์ BN ยังนับเป็นการขยายข้อมูลและชั้น BN dithers สตรีมการเข้ารหัสที่มีเพียง 0 และ 1 เพื่อให้การไล่ระดับสีสามารถเปลี่ยนแปลงได้และการเพิ่มประสิทธิภาพจะดีกว่า ชี้ให้เห็นว่าเป็นปัญหาการเพิ่มประสิทธิภาพ)
ทำไมต้องใช้ CNN? จากนั้นผู้สัมภาษณ์แนะนำสิ่งอื่น (ฝัง) ในสาขาคำแนะนำ
คำตอบ: (จริง ๆ แล้วฉันรู้เกี่ยวกับการฝังเพราะเพื่อนที่เข้าร่วมในการแข่งขันเล่น NFM ชั้นแรกคือเลเยอร์ฝัง) คำตอบของฉันมีอคติต่อฉากลักษณะในสาขาการเข้ารหัส ค่าคงที่ ดังนั้นจึงไม่ดีที่จะใช้ CNN เพื่อทำการฝังที่เกี่ยวข้องทั่วโลก คุณสมบัติในคำแนะนำนั้นกระจัดกระจายหลังจากการแยกแยะและคุณสมบัติของตัวเองอาจมีข้อมูลเชิงโต้ตอบที่มีลำดับสูงดังนั้นการทำแผนที่เข้ากับเวกเตอร์แฝงจะดีขึ้น สิ่งนี้ถูกกำหนดโดยฉาก (ฉันยังแนะนำว่าทำไม ResNet จึงดีกว่าสำหรับภาพ แต่ในการเข้ารหัสประสิทธิภาพของเครือข่ายการปรับพารามิเตอร์สุดขั้วสองชั้นของฉันเกินกว่าเครือข่ายที่เหลือในความเป็นจริงมันถูกกำหนดโดยฉากทั้งหมด)
ผู้สัมภาษณ์เป็นช็อตใหญ่!
แนะนำตัวเองคุณจะมาที่ Mogu Street หรือไม่? บทสนทนาก่อนหน้านั้นราบรื่นมากส่วนใหญ่เป็นเพราะฉันแนะนำเกมของตัวเองตั้งแต่ต้นจนจบพื้นหลังของเกมการเดินทางทางจิตตรงกลางและการประมวลผลขั้นสุดท้าย การสอบครั้งแรกและครั้งที่สองเป็นไปอย่างราบรื่นและการสอบสองครั้งแรกก็ราบรื่นอย่างไม่น่าเชื่อ มิฉะนั้นถนน Mogujie ของฉันจะมั่นคง
ให้กระแสของวงเล็บให้ค้นหาคู่ที่จับคู่กันต่อเนื่อง 1 ในสตริง s = '(()) (() () ()' ผลลัพธ์คือ 3 DP ของฉันด้านล่างดูเหมือนจะมี 0 ในตอนแรก? ดังนั้นฉันจึงบอกว่าฉันไม่ได้ดีที่สตริง การเขียนโปรแกรมแบบไดนามิกสามารถทำได้ซึ่งเป็นความแข็งแกร่งของฉัน ที่ด้านล่าง = '()' ฉันคิดว่าอินพุตถูกป้อน แต่การอ่านที่แท้จริงของ S ควรว่างเปล่า Nani? 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
#s = input()
s = '(())(()()()'
#s = '(())(()'
re = []
dp = [0]
for i in s:
if not re:
re.append(i)
dp.append(0)
else:
if i=='(':
re.append(i)
dp.append(0)
else:
if re[-1]=='(':
re.pop()
dp.append(dp.pop()+1)
else:
re.append(')')
dp.append(0)
print(re)
print(dp)
m = 0
cur = 0
for i in dp:
if i!=0:
cur+=i
m = max(cur,m)
else:
cur = 0
print(m)
输出:
['(']
[0, 0, 2, 0, 1, 1, 1]
3
เมื่อถามคำถามในตอนท้ายผู้สัมภาษณ์พูดอะไรที่ดีมาก โดยทั่วไปแล้วเราจำเป็นต้องจัดเรียงตามลำดับบางส่วน แต่ในบางกรณีของการโฆษณาการประมูลเราต้องให้การประมาณการที่ถูกต้องเพื่อให้เราสามารถแบ่งเงินได้อย่างง่ายดาย ตัวอย่างเช่นอัตราการคลิกผ่าน CTR หรือชุดค่าผสมอื่น ๆ จะต้องคำนวณรายได้ตามการจัดอันดับนี้ นอกจากนี้ในการค้นหาที่แนะนำเจ้านายยังแนะนำสิ่งที่เกี่ยวข้องบางอย่าง กล่าวคือสิ่งที่เรียกคืนอาจซ้ำเกินไปหรือจำเป็นต้องกรองออก (ตัวอย่างเช่นมันไม่เหมาะสำหรับเด็กและทุกคนบ้าซึ่งไม่ดี) ดังนั้นการกรองจะทำอย่างไร? และถ้าคุณแนะนำให้บุคคลหนึ่งวิธีเดียวคือการส่งฝูงชนโดยไม่ต้องสร้างคุณสมบัติเพราะเมื่อคุณผลักดันให้บุคคลบางคนบุคคลนี้เทียบเท่ากับโฆษณาทั้งหมดหรือคำแนะนำอื่น ๆ เรียกคืนและเรียงลำดับ ในที่สุดฉันก็ถามเกี่ยวกับอายุเฉลี่ยของ บริษัท เพราะโดยส่วนตัวแล้วฉันสนใจเรื่องนี้ ผู้สัมภาษณ์บอกว่าอย่าเป็นภาระ 5 ปี แข็งแกร่งหล่อและแข็งแกร่ง) เขาให้การสนับสนุนฉันมากขึ้นหลังจากทำงานเป็นเวลาสองปี ยิ่งไปกว่านั้นเขากล่าวว่า Mogujie เป็นแพลตฟอร์มขนาดกลางที่มีผลประโยชน์พิเศษ การไหลของข้อมูลสามารถใช้หลายรุ่น บริษัท . คุณสามารถแสดงออกได้ดีขึ้นเมื่อคุณมาที่ Mogujie ฉันได้รับการแจ้งเตือนจากฝ่ายทรัพยากรบุคคลและขอให้รอให้ผู้สัมภาษณ์มาโรงเรียนหรือไปที่ บริษัท โดยตรงเพื่อสัมภาษณ์
1. แนะนำตัวเอง
ฉันไม่มีข้อเสนอมากมาย
ฉันได้พูดคุยเกี่ยวกับซอฟต์แวร์การวิจัยทางวิทยาศาสตร์ที่ฉันเขียน
เมื่อฉันแนะนำตัวเองฉันพูดถึงว่าฉันชอบเล่นเกม (ฉันเคยเล่นเวอร์ชั่นละเมิดลิขสิทธิ์ แต่ตอนนี้ฉันเล่นเกมของแท้ด้วย Steam Level 50 หรือสูงกว่าและจากนั้นเกมเกือบ 100)
(ฉันได้เรียนรู้การพัฒนาส่วนหลังด้วยตัวเองและฉันไม่ต้องการ Python เพื่อความบันเทิงซึ่งกันและกัน)
2. คุณมักจะชอบเล่นเกมอะไร?
ฉันได้ทำการวิจัยทางวิทยาศาสตร์เมื่อเร็ว ๆ นี้และยังไม่ได้เล่นเกม ฉันเคยชอบเล่น Zelda, Dark Souls, Monster Hunter ฯลฯ
3. คุณเคยเล่นเกม NetEase หรือไม่?
Onmyoji และ Hearthstone
4. มาพูดถึง Hearthstone กันเถอะ?
ฉันเคยชอบเล่น Hearthstone ส่วนใหญ่เป็นเพราะฉันชอบเปิดแพ็ค (ผู้สัมภาษณ์หัวเราะ) และฉันใช้เงินจำนวนมากกับ Hearthstone เพราะฉันเต็มใจที่จะสนับสนุนเกมถ้าฉันชอบมัน ข้อได้เปรียบของ Hearthstone คือการแข่งขันและมันก็เป็นเกมไพ่ดังนั้นมันจึงน่าสนใจในตัวเองและแต่ละเกมจะสุ่มเพื่อให้ประสบการณ์ของแต่ละประโยคแตกต่างกัน อีกจุดหนึ่งคือการประหยัดเหรียญทองเพื่อเปิดแพ็ค ด้วยวิธีนี้คุณจะมีประสบการณ์ใหม่ทุกครั้งและรักษาผู้ใช้ไว้
5. คำถามสามข้อค่อนข้างง่ายคุณต้องเขียนกรณีทดสอบ
การฉีกขาดมือประสบความสำเร็จและการเขียนโค้ดค่อนข้างเร็ว
สองคะแนนสำหรับคำถามแรก
การรวบรวมที่เขียนใน Python รายงานข้อผิดพลาด
มีการหารือเกี่ยวกับเงื่อนไขขอบเขตสี่ประการของการแบ่งแยก
สองประเภทของการส่งคืน ST และ EN สอดคล้องกับขอบเขตการค้นหาที่ส่งคืนข้อมูล [กลาง] <ค่าและ <= ค่าและทั้งสองประเภทสอดคล้องกับขอบเขตบนและล่าง
共四种,然后说四种情况对应,每种的取值范围返回st,返回的取值范围是0到数组长度,返回en,则是-1到数组长度-1 st和en含义不一样,这个最好自己写写理解一下(更新了一下lower_bound的理解,解释了为什么返回值范围是0到len(data) PS:标准库返回的是迭代器位置,是一个指针,我这里从元素的位置概述。 lower_bound 返回数组大于等于value的第一个位置,假如数组中所有元素均小于value,返回尾部迭代器len(data),第一个元素大于等于value,返回0 (第一个元素大于等于value,则所有元素大于等于value,则返回0) 从定义看,这样定义就不可能返回负1。 找身边的跳动大佬讨论了一下,应该没写错了,有误请指正呀。 upper_bound返回大于value的第一个位置。同理,理论上返回值就不包含-1。 标准库的写法里,返回的是st。 加入返回的是en呢,那么返回的含义是什么呢?即返回的st情况-1 lower_bound :返回大于等于value的第一个位置lower_bound_en:返回小于value的第一个位置
upper_bound:返回大于value的第一个位置upper_bound_en:返回小于等于value的第一个位置1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def lower_bound(data,value): st = 0 en = len(data)-1 mid = st+((en-st)>>1) while(st<=en): if data[mid]<value: st = mid 1 else: en = mid -1 mid = st+((en-st)>>1) return st def lower_bound_en(data,value): st = 0 en = len(data)-1 mid = st+((en-st)>>1) while(st<=en): if data[mid]<value: st = mid 1 else: en = mid -1 mid = st+((en-st)>>1) return en def upper_bound(data,value): st = 0 en = len(data)-1 mid = st+((en-st)>>1) while(st<=en): if data[mid]<=value: st = mid 1 else: en = mid -1 mid = st+((en-st)>>1) return st def upper_bound_en(data,value): st = 0 en = len(data)-1 mid = st+((en-st)>>1) while(st<=en): if data[mid]<=value: st = mid 1 else: en = mid -1 mid = st+((en-st)>>1) return en
对比的数改成1。
) 然后说了C++算法标准库(lower_bound和upper_bound)用的哪两种形式:返回st的那两种注意C++标准库返回的是指针第二题是二叉树的深度
python手撕,又报错,然后无IDE查bug还好查到了,print大发好,对python,如果print(“XXX”)没输出东西就说明没运行这一行。
定义树class的时候写的是.next,晕了,应该是.left和.right
第三题是数组旋转
左旋转,自信一波分析写完是右旋转,一脸懵逼,怎么看都是左旋转跑完就是右旋转
然后再那试了试改i,j,然后第二次就输出对了,晕,运气比较好
由于循环用的常数限制,要求改成了数组的范围,注意python len(data)是行len(data[0])是列
正常构造一个和data一样大new数组是先列后行[[0 for _ in range(len(data[0])] for _ in range(len(data)]
然后循环是先行后列(这样局部性更好,运行速度快,更容易缓存命中,当然面试官也没问我也没提)
写法应该是对的,但我不敢改成行列不相等的情况,万一错了呢.PS:想了想应该不对,因为new数组我照着data开辟的,应该行列反过来开辟才对,先行后列构造的话正好对应旋转后的情况,幸好没深究,不过这种bug很容易改,print()大法print一下就出来了
问问题:好希望他问我机器学习的东东,这样我就能装逼了,然而
6、静态内存和动态内存?
讲了static和堆栈是静态,编译的时候决定了大小,动态内存可以自由开辟->堆,也不知道对不对。 -
(回来问了问另一个收割大佬,应该是这样)
7、堆是?
说了向上开辟,速度慢、运行时改,然后开辟的过程,链表存着下一个位置和这一块有没有使用,如果没找到就析构合并内存再找,再找不到返回null(可以参考前面的答案)
8、堆栈是?
说了向下开辟、速度快、编译时分配、主要是存PC指针,然后函数入口参数多组成栈帧存进去等着恢复
9、malloc和new区别free和delete?
1、一个是函数(面试官没问,但我自觉呀,诚实回答忘了是哪个头文件里的了,事后查了查是stdlib我擦我天天写没想到是这个)一个是关键字
2、malloc要算大小,返回void*(然后随口提到void*可以转XX *),强转后按转完后的类型用,要自己算大小;new的时候传类型,就比如100个int,然后直接开100个就好了,他自动将int长度算进去
3、malloc再堆上,new在自由存储区(然后回答忘了自由存储区再哪了) 讲着讲着忘了free和delete的事了
(自由存储区和堆似乎是概念上的区别?我丢,深入理解计算机基础是按C讲的,我哪知道C++的自由存储区和C的堆有啥区别呀,按理来说假如new是依赖malloc实现的,那么他们不该开辟于同一块区域么。C++默认在堆上开辟new需要的空间,所以new来自自由存储区和堆都行。
网搜的答案:
自由存储区是C++中通过new与delete动态分配和释放对象的抽象概念,而堆(heap)是C语言和操作系统的术语,是操作系统维护的一块动态分配内存。
new所申请的内存区域在C++中称为自由存储区。藉由堆实现的自由存储,可以说new所申请的内存区域在堆上。
堆与自由存储区还是有区别的,它们并非等价。
-
10、智能指针了解不?
我从python的内存管理角度讲了计数法析构内存,和智能指针原理一致。但我自觉诚实的说出我没用过智能指针
11、python怎么解决循环引用的?
是不是想问我智能指针的循环引用解法?我忘了呀,我就直说python本身解不了循环引用的问题(这实话实说,确实解不了,python又不是神,循环引用要靠自己析构,对python来说,循环引用的东西就算程序关了都还在),但python有个库函数可以发现循环引用位置,然后调用垃圾收集器析构掉就好(其实就是定位内存泄露,然后gc把它干掉)
12、计网了解不?计算机网络TCP和UDP的区别?
答自学。回答了很多,挺详细了
(UDP主要用于那些对高速传输和实时性有较高要求的通信或广播通信,
TCP用于在传输层有必要实现可靠性传输的情况
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的;UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
这里建议不是特别熟的回答首部设置不一样,别说的太详细。
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
-
13、长传输和短传输?
ไม่มีความคิด
(是http的长连接和短连接吗?HTTP1.1规定了默认保持长连接(HTTP),数据传输完成了保持TCP连接不断开(不发RST包、不四次握手),等待在同域名下继续用这个通道传输数据;相反的就是短连接。)
14、操作系统呢?
回答自己看的深入理解计算机系统,看的很详细,收获了特别多
15、进程和线程?
程序不过一段文本,运行起来才是进程,一顿讲,资源/调度单位啊、共享内存啊、并发啊XXXXXX
(见之前的答案)
16、你还有什么问我?
问了两个问题
一问:您能不能了解到其他面试人的信息,然后对着我教研室座位后面的字节大佬猛夸(因为他特别想去互娛做游戏),一开始面试官还以为这个人挂了呢我想捞一手,一听和我同时面了互娱就轻松了说既然这么强一定能过面试,然后我就突然想到好像可以暗示一波,就说我和他报的都是广州,我很想和他当同事(强烈暗示)
二问:我说我是算法工程师,机器学习特别厉害,平时工作内容是啥啊,机器学习这部分我都用上么
求互娱给个开奖机会,教练我想做游戏~(如果百度把我忘了的话),你敢让我过我就敢去宁可别被我逮住了
负责360搜索的部门,面试体验很好。
忘了面试的一部分,因为连续4面,其中技术面360两个,网易互联网1个,hr面1面,非常之累。
1、介绍自己
2、介绍自己实现的科研软件
用什么语言:C++
什么写的界面:QT
3、LGB和XGB区别
一开始听错了以为是LSTM,我还在想LSTM和XGB的区别,这怎么说,先介绍介绍XGB吧,然后说完XGB反应过来,面试官不是让我说LGB吧。 -那就好说了,一顿讲。
(答案前面有)
4、介绍CNN、卷积层如何实现非线性
使用激活层,不然在卷积都是线性变换。我从猫的视觉锥细胞开始一顿讲,应该讲的挺详细了,CNN的时不变性真的很适合用于信号处理。讲了时不变和局部权值共享,说CNN是DNN的特例。
-
卷积:对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重)做内积操作。
卷积的重要的物理意义是:一个函数(如:单位响应)在另一个函数(如:输入信号)上的加权叠加。
卷积神经网络CNN是多层感知机(MLP)的变种。20世纪60年代,Hubel等在研究猫脑皮层时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了CNN。
CNN:局部连接和共享权值的方式,减少了的权值的数量使得网络易于优化,另一方面降低了过拟合的风险。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。在二维图像处理上有众多优势。
CNN具有一些传统技术所没有的优点:良好的容错能力、并行处理能力和自学习能力,可处理环境信息复杂,背景知识不清楚,推理规则不明确情况下的问题,允许样品有较大的缺损、畸变,运行速度快,自适应性能好,具有较高的分辨率。它是通过结构重组和减少权值将特征抽取功能融合进多层感知器,省略识别前复杂的图像特征抽取过程。
CNN的泛化能力要显著优于其它方法,卷积神经网络已被应用于模式分类,物体检测和物体识别等方面。利用卷积神经网络建立模式分类器,将卷积神经网络作为通用的模式分类器,直接用于灰度图像。
-
5、卷积层pooling层怎么放?激活层放哪里比较好,有什么区别?
没听明白,不该是中间夹一个激活层吗。面试官的pooling真的是一言难以呀?我一直以为是最后的全连接FC层,我心想这不是被全局池化代替了么?不会所以一顿乱说?因为我自己也是改网络的时候,经常会尝试层的位置交换,我都是哪个效果好用哪个。讲的时候想起了何凯明大神的论文里的预激活,然后对着预激活、卷积层在Resnet的作用一顿夸。有会的大佬么。请私聊教教我。 - -
两道题
1、10进制转K进制进制转换
给定一个十进制数M,以及需要转换的进制数N。将十进制数M转化为N进制数输入描述输入为一行,M(32位整数)、N(2 ≤ N ≤ 16),以空格隔开。 输出描述为每个测试实例输出转换后的数,每个输出占一行。如果N大于9,则对应的数字规则参考16进制(比如,10用A表示,等等) 这题很简单,发个自己的写法,过一遍就好,挺简单的。可能个别边界会有问题,但是面试的时候尽量追求速度。 牛客网面试的时候,注意运行全部用例,可以看AC的情况,为什么这么说呢,因为你的输入面试官看不见(他说的),所以他只能给你跑一下看过了多少例子。 像这种水题一定要写得快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
//map<int,char>table;
//table[0]='0';
//table[10]='A';
#include<stdio.h>
#include<iostream>
#include<string>
#include<vector>
using namespace std;
void reverse(vector<int>&a)
{
int l = a.size();
for(int i=0;i<l/2; i)
{
int tmp = a[i];
a[i] = a[l-i-1];
a[l-i-1] = tmp;
}
}
string get(int M,int K)
{
bool ju = false;
if(M<0)
{
ju = true;
}
//注意负数转正数溢出
M=abs(M);
vector<int>data;
while(M)
{
data.push_back(M%K);
M/=K;
}
reverse(data);
string res = "";
if(ju)
res ='-';
for(int i=0;i<data.size();i )
{
if(data[i]<=9)
res ='0' data[i];
else
res ='A'-10 data[i];
}
return res;
}
int main()
{
int M=7,K=2;
cin>>M>>K;
string s = get(M,K);
cout<<s<<endl;
}
2、A->B,B->C,A->C,C->A中有一对链子A->C,C->A问序列里有多少对链子使用哪种数据结构?
要求:序列很长,只看直接相连,A->B->C->A 不算ABC互联。
讲了比较简单的d[i][j]=(bool)的结构,O(N^2)的时间和空间复杂度
又讲了两次扫描,O(N^2)的时间复杂度,O(1)空间复杂度
最后说了数组+链表,极端情况下时间复杂度也较高,但我心里想的是对链表排序也不慢吧,二分查找,时间空间都OK呀,但我傻就傻在我心里想了,嘴上没说链表排序。
最后有会的大佬么请教教我。 -
体验好,一道题,抽的前两道题都做过,一个是奇偶排序,一个是前序中序重建树
都是剑指OFFer原题,面试官见我思路顺畅,问我是不是做过,做过默写就没意思了。
我说做过剑指OFFer原题。 前两道题没手写。
第一道奇偶排序要求稳定排序,思路1就是归并排序,前偶后奇为大于。思路2双指针二分偶数倒
第二道找根节点,二分,没了
第三道没做过,但是也简单,问面试官能不能用python,能的话两分钟结束这道题,说不行就老实写了
这一面主要是深挖项目,深挖!
反问环节,面试官疯狂指导我,真好,这里总结了记住的一部分:
聊了搜索推荐的一些问题,我问的第一个是360对编程能力的要求。面试官的回答是所有的算法工程师都要具备很强的编程能力。
第二个是推荐中排行榜的问题,我说上了排行榜,阅读量就是疯狂增加,一增加就会更留在排行榜上,这种情况怎么办。面试官回答这是正反馈问题,说了很多干货,有兴趣做推荐的可以看看相关内容。
我又问了冷启动的问题,我就说对于新出现的页面,第一次出现,没有任何曝光下,如何给他做推荐呢?这里面试官反问了我,我就回答了自己的思考,先小批次试点曝光,再推广。
面试官开始讲推荐和搜索排序的区别,搜索排序面临的问题更复杂。所谓排序就是获取大数据的网页界面,然后对用户的查询给出一个最可能的结果(LGB可用),用到一些分层、召回(最优可能查询结果捞出来)、排序(对捞出来的东西排序),这里排序要做到去相关性,查询要保证输出结果多样性、表达多样性,还牵扯到了词与词之间的紧密度、运营和相似度命中。
In addition, there are many difficulties in sorting. First, the amount of data is larger and a lot of information is captured. However, the more indexes, the better, because there are duplicate (plagiarized web pages) and low-quality web pages .另外对于learning to rank,我们不需要像回归那样得到准确的回归值,只要得到他的偏序就好。比如A<B,我们算价值是A:80,B:79和A:80 B:77,偏序都一样,只要排序正确即可。而要检验我们排序的好不好,就是根据反馈,检验模型的优劣,比如我们把A在B前面,但是用户不点A点B,用户改Quary词或者翻页,都可以用于检验模型效果。这三时候可能会用概率图解决这些问题。排序技术难度大,底层需要的技术也比较高级。 In addition, there may be a certain gap between the user's inquiry and our results. For example, when a user searches for the price of a certain car, the search result we give is the transaction price of a certain car. This creates a gap .
最后我问了这么一个问题,就是我在做学习强国的时候,查询一个答案, 结果第一个是付费的,第二是是免费的,有限的时间里查到的第一个结果让我付费观看,我就很生气。这个怎么看待?面试官的回答也是很棒呀,所谓的搜索排序最终就是给用户满意的结果,结果可能是多样的,有的排版好内容丰富,有的排版差内容差,我们做的就是把最好的结果展示给用户。对于搜索排序,可能产业化的结果分两个,第一种是满足需求的免费内容,特别用户预期的结果。第二种可能是竞价排序的结果,可能付费观看,大部分用户没有付费的欲望觉得不好,少部分付费用户可能也会特别喜欢,但无论如何,前者肯定也会在搜索结果前列。
啊,面到最后没时间了,面试官让我问问题,我就随便问了两个,然后不得不回360电话了,就说我有点事把视频关了,本来面得挺好的,哭
其他的忘了,就记得两道题
第一道n的二进制表示中有1的个数
1 2 3 4 5 6 int re = 0; while(n) { re; n = n&(n-1); } 然后分析复杂度,最后提示下分析出来了log(1+n)
然后分析平均复杂度,我以为从1 到int_max的所有复杂度求平均。所以怎么都分析不对。
最后才知道是每个的复杂度,晕,面试官告诉我是log前面的系数是0.5。
第二道:
1、建个链表
2、打印链表
3、反转链表
反转链表写的不好,左右边界各判断了一次,正常情况下只判断一次就好,但面试官说也OK,多做一次时间影响不大,结果正确就好。
4、排序链表
做的是真难受,臭牛客,哼哼。写错个变量都指不出来,改bug改到头秃。
排序链表写的是链表快排,最后发现复杂度不是nlog(n),因为我L部分的尾部没有指向mid(base),导致我最后写了个找L部分的尾部,把这一步优化了就没问题了,但是面试官说也行吧排序的结果不会错。
最后问问题的时候,我一边问一边调试,最后终于把链表快排调对了。然后和面试官说我调出来了,就匆匆结束了这次面试,很难过。因为马上360就是二面,我总不能为一面放弃二面把,这里我情商不够处理的不好,哎,难受。面试官人都挺好的,都是我的问题。
面试经验肯定是面的越多越丰富的,从最初乐鑫的笔试挂,到字节跳动笔试不会写输入流(第一道题我本地1分钟就A了,然后不会写输入流,试了15分钟,然后写了第4题,结果本地能过线上报编译错误,我就很生气了,何况这个输入流更复杂我就直接放弃了)笔试直接挂,到现在面试一点也不紧张,可以和面试官愉快吹牛逼了,所以说多点经历也是挺好的(补充,这次字节笔试3.6/4,还可以)
##部分已挂的公司,吐槽一下: OPPO 简历挂?显示简历过,没有通知面试,可能原因是没填内推码,身边的字节大佬也和我一样简历挂。 - -问了去面试的算法同学面试题目婴儿难度。 还有提前批没过,但是简历状态还有,是已处理,不能再次投递。 - - VIVO 笔试挂。 -我真没想到笔试还能挂,不过VIVO SP给的还不错,问的问题也不能说难?没中奖呀难受很气,想想要不要投步步高?三顾茅庐了要阿里内推挂(本来在池子里,然后部门的那个人发邮件给你内推,内推完刷新界面挂,可能原因是我扫了内推连接,但是我一般是不选择内推,想一想阿里内推人也不容易,互相体谅吧) 还有一个不知道哪里的公司挂了我简历,原因是简历是牛客上创建的,都不知道什么时候创建的,简历上面很干净。 -
18-28 作者:工大菜鸡链接:(https://www.nowcoder.com/discuss/295287)
18. 顺丰sp和ihandy牛客专场:
开篇就是吐槽,我为什么写这个?不是因为顺丰面试有多难,而是顺丰答应给我的二面,到现在都没给。 - -从8月1号顺丰给了我人生中第一次公司面试到9月28号我结束秋招,在这期间顺丰不断推迟二面时间,现在又给我推到了10月中旬,不得不说,顺丰的hr还真是佛系呢。 ihandy这货更狠,给我答应的一面到现在都没兑现,每次打电话过去问hr,都是同一个回答:马上帮您安排,然后我就继续傻傻的等一两个星期,循环往复。
1.自我介绍,为什么转行,你原来实验室干的什么?:因为喜欢算(qian)法(duo),原来实验室干的导航制导与控制;
2.介绍比赛,做了哪些数据的清洗,数据增强的处理?作了哪些特征?怎样提取特征的,为什么会想到这个特征呢?:balabala如实说,还说目前进入了复赛,正在复赛准备阶段XXXXX啥的;
3.我看你比赛用到了xgboost和lightGBM,那说下XGboost原理吧:额……不会;
4.那说下LightGBM吧:咳咳,也不会;
4.额那说下GBDT总行了吧:额……还是不会;
5.那你会啥?我:LR。(面试官快哭了TT);
6.那好吧那你说说LR吧:balabala;
7.你听过CATboost吗?我:没。(面试官再一次哭了);
8.说说LSTM的原理:balabala还口述了输入门,更新门,输出门的公式;
9.你有什么想了解顺丰的吗?我:X$Y*&^%(&%@1!2¥……;
我知道我答的很菜,但我还是厚着脸皮问了面试官我的表现咋样,能否就我的面试情况和简历提点建议?后面每一次我视频面试我都会向面试官问这个问题,他们也都会热心的给我提出建议,帮我修改简历,收获很多。
结果:没想到一面给我过了,但是二面迟迟不到。
19. 滴滴牛客sp专场(二面挂):
惭愧,当时在面试的时候还以为滴滴是小公司,问面试官问题的时候,我居然问了滴滴的业务存活情况……
1.自我介绍,转行之类的问题;
2.了解那种算法挑一种介绍下:我说了LR,刚说到交叉熵这儿,面试官打断:那你说说LR为什么用交叉熵作为loss函数。我:因为lr从概率密度函数推导出来的对数极大似然函数就是交叉熵函数。面试官说:不全对,其实mse是万能的loss函数,每个模型都可以用mse作为loss函数的,那为什么lr不用mse呢?我:不几道。面试完了才想明白,mse的导数里面有sigmoid函数的导数,而交叉熵导数里面没有sigmoid函数的导数,sigmoid的导数的最大值为0.25,更新数据时太慢了;
3.说说XGB:在上次顺丰面完后,我仔细学习了一遍xgb,这一次大致回答上了面试官的问题,我说了GBDT,再从XGB是如何改进GBDT的角度引入了XGB的一些概念,比如预排序什么的,引入正则项和二阶泰勒展开什么的;
4.介绍比赛,介绍如何分工的,如何构建特征的,如何选择这些特征的;
5.说下常见的处理过拟合手段有哪些?我说了l1,l2,神经网络里的dropout,增加数据量等等,面试官问还有吗?我:不知道了。其实后来才知道bagging和boosting也是降低过拟合的手段,以前还以为仅仅是种特殊的模型。
同样向面试官问了我的表现情况以及如何改进,面试官也热心的提出了建议。
1.自我介绍,大致介绍项目。
2.聊比赛,聊人生。 - - - -大概聊了30多分钟。
3.问你会不会什么操作系统,数据库啥的,c++会不会。答:都不会
二面很自然的就挂了,从滴滴的面试可以看出,其实国内的很多公司都挺看中开发能力的,只会python和跑跑模型应该达不到绝大多数公司的要求。
20.快手牛客sp专场(二面挂)
1.基础问题都是老生常谈,问题和回答略了
2.算法题:求最长回文子串,leetcode原题,动态规划求解最好,但我当时不会,用的是中心展开法,勉强做了出来。
1.上来一道leetcode上的hard算法题:求最小编辑距离。不会,直接gg
2.其他闲聊,聊人生
大概等了10多天,官网上给我挂了
21.依图(一面挂)
是我最惨的一次面试,面试官笑眯眯的,也没让我自我介绍,上来四到算法题,一道一道来的那种,题目都忘了,只记得每道都把我摁在地上摩擦,差不多情况就是这样:
面试官:出道算法题吧,第一道:XXXX。
我思索10分钟:不会;
面试官:那我们做第二道吧:XXXX。
我又思索10分钟:不会……;
面试官:那再来一道:XXXX。
我寻思我都这么惨了放过我让我走吧求你了,于是思索了两分钟说:还是不会……;
面试官:那再来一道:XXXX。
我:gun!
后来视频面试结束的时候,我专门去查了这几道题目,他们都有一个统一的解法,那就是动态规划,抱歉我之前真没听过动态规划啊啊啊啊啊,我从此下定决心,进行dp的专项练习。
22.腾讯(一面挂,好后悔没有抓住唯一一次进鹅厂的机会)
其实面试官问的问题都很简单,但是当时比赛刚做完,非常疲惫,不想学习,没有学习新的东西,也没复习旧的东西,就这样躺尸了两天,然后腾讯的技术面试官晚上打来电话面试:
1.自我介绍,介绍比赛
2.看你用到了朴素贝叶斯,说下原理吧。我心想这还不简单,刚要张嘴,才发现坏了,啥叫朴素贝叶斯来着?我给忘了!我就支支吾吾的说:用了贝叶斯公式,然后加上了观测独立假设,面试官无语……
3.说下xgb,lgb和gbdt吧。这个我会,由于前面问了很多了,不用复习也能张口就来。
4.我看你的另一个比赛用了bert和CRF,说说CRF的原理吧。我:……不会(后悔没看)
5.那说下bert的原理吧。我:……还是不会(好后悔啊,太懒了,还是没看)
后面balabala的问了一堆,我都回答上了,但是前面这几个没回答上的太伤了,一面挂
23.远景(四面挂,boss面挂的,真是挂的莫名其妙……)
都是随便介绍项目,问一些基础的问题,没啥难的,印象深刻的是二面面试官问到最后突然让我用英文介绍下比赛里面是如何选择特征的,我用我的工地散装英语一顿乱说,结束时面试官说嗯很不错,我内心:靠,你压根就没听吧!
四面是boss面,现场面的,聊人生,跟我聊了一个半小时,全程也穿插问些问题,我都回答上了,跟boss聊得非常好,然后就给我莫名其妙的挂了……,我想原因应该是boss临走前给我说了一句:你需要多注重工程能力。他可能嫌我工程项目很少吧。
24.百度(一面挂)
百度的笔试就令人印象深刻:
选择题啥都考,很杂,操作系统,数据库,c++,python,机器学习,深度学习啥都考
两道问答题,其中有一问印象深刻:说说针对中文,BERT有什么可以改进的地方。我心想:你丫不就是想吹自己的ERNIE嘛,我就写了ERNIE针对BERT做出的改进,基于知识的mask训练方式,基于知识图谱的改进等等
一道设计题,让你设计一个系统:可以写出春联,必须满足他的要求,平仄音节都要对上,我直接BERT+CRF+GPT一顿乱写。
编程题:RGB括号,我猜应该是道dp题吧,链接:https://www.nowcoder.com/discuss/254095
想看的童鞋可以看一看,无视我的答案就好,我到现在都不知道我的答案对不对。
1.红黑树的几个特点。只答上两个,其实我根本不会
2.python的装饰器@的用法。 จะไม่
3.编程,写一个函数,实现python的继承,数据的交换,类中的全局变量等等。写上了一半。
4.快排(不能用简单粗暴的那种,要空间复杂度最低的)和堆排序(必须用最小堆实现)。 Instead of asking you to write code, I give you an array and let you directly use the ideas of quick sort and stack sort to demonstrate it element by element to him. I answered this question. Fortunately, I have implemented it before and understood it .
5.算法题dp两道:最长公共子串,最长公共子列,都是dp题,幸好专门看了九章算法,专项学习了dp,简单或者中等的dp题还是可以一战的,这两道也是lintcode上的原题,有兴趣的童鞋可以查查。
6.介绍xgb,我说到“xgb的预排序是相对于暴力求解的加速”这儿,面试官打断了我,反问我:那具体是为什么加速了呢?一个特征下的数据,没有预排序和预排序了,不都得遍历一遍才能求解出最优分裂点吗?
这个问题给我干蒙了,其实这个问题我之前思考过,但是太懒了,心里不断麻醉自己面试官不会问得这么细,就直接忽略了,没再去想。百度面试完以后我看了原论文的伪代码才明白为什么。所以再次建议尽量能读一读原paper。
7.介绍下xgb是如何调参的,哪一个先调,哪一个后调,为什么?哪几个单独调,哪几个放在一组调,为什么?哪些是处理过拟合的,哪些是增加模型复杂程度的,为什么?我寻思你十万个为什么呢?总之就是被为什么问的头昏脑涨,出了门我就知道肯定挂了。
25.搜狗(面试流程结束)
1.lr为什么用sigmoid函数作为概率函数。我:lr是基于伯努利分布为假设的,伯努利分布的指数形式就是sigmoid函数,而且sigmoid函数可以将数据压缩到0-1内,以便表示概率。
2.介绍下word2vec,说说word2vec和fasttext的区别。我:balabalabala,说的貌似还行,面试官点头
3.印象深刻的推导:
推导下word2vec里面的一个模型CBOW吧。后悔没看,哭了,我说不会。
那推导下SVM吧。这个我会,推出来了,但是到对偶条件这里,面试官问为什么能用对偶条件,我没答上来,还是太菜。
那再推下lr吧。这次顺利的推了出来,面试官问的问题也回答了上来。顺利通过了。
4.算法题:求最长回文子串,没错,和前面快手一面问的笔试题一样,答上了。
5.概率题,严格来说,这道题不是我遇见的,是我同学面搜狗的时候被问到的,我觉得很有意思,而且我们都不知道答案,请大佬解答:
一共54张扑克牌,我抽了几张牌(大于2张),有两种场景: 1.我说我有小王; 2.我说我有大王; 这两种情况,哪种有双王的概率更高?
这题我是一脸懵逼的,求各位大佬解答!
2.搜狗二面:
1.xgb的loss函数的推导(mse以及非mse形式),以及求解推导。
推出来了;
2.求最大连续子列和,要求时间空间复杂度最小。
很简单;
3.xgb是如何实现并行的。
保存预排序的block,用进程间的通信并行寻找最优分裂点。
4.lgb的直方图优化算法说说。
随便说了说,面试官也没深问。
5.讲比赛,讲项目。
balabalabal总之二面持续了差不多一小时
没啥好讲的,聊人生,聊转行,hr说需要综合各地的信息来筛选,让我回去等消息。
26.OPPO(offer)
我整个秋招所经历的所有面试官里面,一共面了三个非常有水平的面试官(我个人觉得):一个是远景的那个boss,微软亚研院呆了四年,百度呆了六年,google呆了六年。和我聊现在的行业形势以及各种模型的应用,很多问题都会直击要害,一语中的。和我的聊天中看出了我工程能力不足,跟我聊了一个半小时,为我未来提出了一些建议和规划,我很感谢那位大叔;第二个是百度的一面面试官,他好像就是住在我肚子里的蛔虫一样,总能在我的回答中揪出我不会的致命知识点,给我痛击,真的是怕啥他考啥,他的基础非常扎实,而且反应和判断非常迅速;第三个就是这个oppo的一面面试官,根本不问固定知识点,就问一些模型、手段、措施背后的本质并且举例说明,在你运用的实际场景中有没有见过。
刚开始都没让我自我介绍,直接让我说比赛。我:balabala,我介绍到CRF的时候,面试官打断我说:“你说CRF说了一大堆,那他它本质是个啥东西,我不要听那些定义,你给我说本质”。我:……支支吾吾……,说它应该是个函数,balabalaba一顿编。
然后他也没说对错,继续问:说下attention吧,我:又是一顿balabala,讲到注意力那儿的时候他问:你能举个case吗,用了attention和没用attention时候的对应的隐状态在哪些地方有区别你有去观察过吗?我:又是一顿瞎bala,他又没说对还是错。
又问我看你这里用到bilstm它和lstm的区别在哪?举例说明,用了和没用的效果。我心想:哎呦终于有个会的了,结果回答完他还是那副样子,又是啥也没说,我心想对还是错你倒是给个准信啊。
又问到了ELMo,让我说明ELMo是如何做到动态词向量的。我:把每个词输入模型,得到的隐状态相加就能得到不同的词向量;
面试官:那说下ELMo的缺点。我说:第一就是多层bilstm天生的缺点:“自己看到自己”的现象,然后举了个例子,balabala……。第二就是无法并行训练,以上两个毛病都可以用bert去改进它;
他又问其实我们可以用加入位置嵌入的方式来改进这个无法并行的问题那为什么非得用bert呢?我一想确实facebook貌似在之前就提出了位置嵌入+textcnn的方式来并行训练。完了,给自己挖坑了。于是乎我就扯了一堆bert里面self-attention的优点,哈哈哈我真是机智。
然后他依旧啥也没说,又让我介绍bert,并且问了multi-head的好处,又问我它的实际物理意义是什么? ทำไมคุณถึงคิดอย่างนั้น?举个case说明下。我用尽了我毕生瞎编的本事,凭借着我自己的一点理解硬是说了10分钟,然后结束了是对是错他还是啥也没说……………………
又让我写LSTM的公式,勉强写上了
又问了我一个实际场景问题:用一个模型去分类一堆数据,在training阶段就无法收敛,反复震荡,有可能是什么原因,你有没有在实际场景中遇见过?
我:可能数据是标注错误的或者是随机数据,面试官补刀:假设数据没问题,那是什么原因?
我:那就是模型无法拟合这个数据或者不适合做这类数据的分类,面试官再补刀:假设模型也没问题,足够复杂。
我:那有可能是优化过程陷入了局部最优,而且一直无法跳出,面试官再次补刀:假如优化过程没问题。
我:那就是正负样本极其不均,网络没法学习到东西?面试官:我没说一定是神经网络模型,而且那再假如样本正负分布是均匀的……
我:……那我真没遇见过这样的……
面试官当时貌似不太满意,跟我聊完居然把我的简历给对折了起来!我第一次见这种场面……,心想:哎呦我去凉了,可能一出门面试官就会把我的简历扔垃圾桶里了吧……。面试官让我回去等,晚上如果收到消息就是过了,没收到就是挂了。晚上感觉想哭,毕竟OPPO是我蛮喜欢的一个公司,结果快睡着了突然来了一个短信提醒,说我OPPO面试过了……,得,这下倒好,睡不着了……
1.聊项目比赛,一路下来没问啥知识点,没啥大问题
2.画出ESIM这个模型的结构,并作介绍
3.面试官看我航天二院的项目跟导弹拦截有关系,是用GRNN预报弹道的,就让我介绍下GRNN的网络结构以及原理,还问预报精度怎么样。我说这个题目现在是我的毕设,还没做完呢……
面试官:哦……那你给我说说你要拦截的这个HTV-2是个啥?
我说:是一种美国的临近空间高超声速飞行器,可用于导弹上,对我国国防安全造成威胁,balabalabala……
面试官好像突然来了兴趣,一直问我导弹的事,跟个好奇宝宝一样:这个HTV-2很厉害吗?
我:点头,嗯嗯嗯
面试官:这个HTV-2有啥特点?你们用经典的方法一般是咋拦截的?balabala……
我:额……这些都是保密的……
面试官:哦,那没事了。
4.聊到后面问我有没有了解过一些其他的搜索排序算法,比如list-wise的,pair-wise的,然后给你一堆非常大的大数据,如何实现全数据的搜索排序,我凭借我的理解大致回答了一些,面试官说还不错,让我等下一面
我拿起我的oppo find x给hr一顿瞎BB,意向书成功到手,虽然是白菜价,但是OPPO是我很想去的一家公司,尤其是近几年开始搞些奇奇怪怪的手机出来以后越想去了- . -。
我原以为一面二面回答的不太好的情况下OPPO也愿意要我,而且hr说今年OPPO机器学习投递的简历,光筛选后的985计算机科班硕士的就多的吓人,所以我感觉OPPO今年应该在机器学习这个岗位上招人需求有很多。没想到签约会时候问hr才得知整个哈尔滨加吉林地区,机器学习的offer只有两个……,瞬间脊背发凉……
27.58同城(口头意向,拒了)
其实能面试58我是非常意外的,因为58的笔试编程题我一道都没做出来,选择题差不多一半都是瞎猜的,甚至面试的时候,面试官还把我做错的选择题拿出来又问了我一遍,并且我还是答错了……囧,而且三个面试官都问了我:为什么编程题一道都没做? ………好尴尬,太奇怪了! - 58怎么会给我面试呢?不过面试时我表现的还不错,最后也拿到了口头意向,但已经签了OPPO就给拒了。
1.还是各种介绍,自我介绍,比赛,项目,为什么转行啥的。
2.我看你用了ESIM这个模型,把模型结构画一下,并且告诉我为什么有用。很简单。
3.算法题:一个数组中和为k的所有二元组,要求时间复杂度为O(n)。这个也很简单。
4.介绍下BERT以及CRF。老生常谈了,他也没深问。
5.算法题:最小编辑距离,没错又一次被问到了,dp常规思路,只不过需要多考虑边界条件。 โซลูชั่นที่สมบูรณ์แบบ
6.算法题:一块钱一瓶水,三个瓶盖能换一瓶水,问20块最多能买多少瓶水?(用编程方法解决。)面试官午饭没吃,饿的等不及了,我刚想了一分钟还没写出来,面试官说一面就到这儿吧,我以为他要把我挂了,赶快急急地说了思路,面试官说没事你一面过了,走去吃饭吧,噗.......
2.58二面:
二面大多数时候都是我在问面试官,一时间搞不清楚谁才是真面试官……问了些58的业务,以及业务中需要的模型,算法等等的。聊得很开心,当然也有些坑,面试官会穿插着问些技术问题,比如在谈到58的软件内搜索业务的时候,面试官问如何在少量数据的情况下对用户的输入进行快速的意图识别。我说了几条:可以用信息熵来确定用户输入主体,用聚类来做些简单的意图识别等等。
3.58hr面:
一个很漂亮的大姐,很亲和,又是聊人生,结束后告诉我回去等通知。
28.华为(offer,拒了)
我申请的是华为消费者bg软件部的人工智能工程师,自然语言处理/语音处理方向。我听说今年很难进华为,想进消费者更是难上加难,但是我仍然没感觉到有多难进……可能华为比较看重课业成绩和学历吧,因为我感觉我只有这个优势……
上来两到算法题,不过都是很简单的leetcode原题,题目我给忘了,但是都答上了。但是我感觉面试难度看脸,有同学就被甩了两道dp题没答上来一面就挂了。
问的问题都很基础,知识点都是前面的那些,没有什么印象深刻的问题。
算法题:求一个数组中和为k的最长连续数组,暴力法解决的,面试官说没有复杂度要求。
问了槽位的概念,这个我之前真没听过,哎,还是太菜了。
问了些其他的基础问题
聊人生,聊规划,圆满结束,offer到手,签约会的时候,hr说给我安排到北京了,我不太想去北京,而且薪资也不高(我听到的消费者的同学都一个均价,什么硬件研究院、智能车、无线的均价都比消费者高),而且最重要的是,他把我安排到了消费者软件部下的智慧城市这个三级部门,大概率是语音方向的,我不是特别喜欢,就给拒了。
约定电面晚上8点半(阿里是加班到9、10点的节奏?)
主要是商汤无人车实习的项目,问我比baseline提升15个点,怎么来的。
从数据迭代、backbone、模型修改几个层面上说了下。
挑一两个有意思的优化说说,说了cascade、hdcnn的结构,为什么用这种结构。
项目中出现什么情况,怎么解决的?主要就是说小目标检测的解决方案。
对caffe源码熟悉程度。(我扯了扯源码的底层设计模式,数据流怎么流的,如何添加新层、cuda代码的细节)
คำถามเปิด
给了一个情景,如何训练模型、调优。(题目很空,主要考察你对深度学习的理解)
根据需求(前向传播时间、模型大小),确定模型和基础网络,跑第一版模型。(举了个栗子) 判断模型是否出现过拟合的情况,来决定下一步的优化方向。 结果分析(confusionMatrix等),分析问题,将论文中的方法套上去,如果没有自己创造。(又举了个栗子)
softmax、多个logistic的各自的优势?1、类别数爆炸,2、推了下softmax反向传播的公式,来对比两者的优劣。
算法(走流程题) 字符串判断是否是ipv4,c++。(可能是时间不多了,大佬想下班了)
全程大多都是我在说,没有太多互动。后来经过源神@邢源建议,还是要故意给面试官漏点马脚让他们来怼我们,然后再怼回去,并说明不这么做的原因,不然不好拿高评分。(卧槽,真的是套路深啊~)
大佬貌似涉猎很广泛,对每一个领域都很熟悉,基本上简历中的很多细节,他都能找到点怼我。(聊了很久)
项目是从头怼到尾,主要考察对项目、深度学习的理解。
大佬对我的trickList很感兴趣,我猜想他现在做的工作和我的很相似。
Anchor大小、长宽比选取?我说了业界常用的方法(YOLO9000中的方法),并提了一个更优的方法。
为什么要深层、浅层featureMap concat?提了点细节和我踩的坑,需要数量级上的调整,不然深层的feature可能会被压制。
Cascade的思想? 说了下我的摸索的一个过程。改变样本分布,困难样本挖掘,能达到比较好的效果。
文字识别使用ctc loss的一些细节。
设计一个情景,倾斜字体检测,问我有什么好的想法?(我觉得应该是他现在遇到的问题)
数据增强,加入形变扰动。
非end-to-end版本:分别训练检测和分类,举了之前做过的一个文字识别的项目的实现。
end-to-end版本:加入仿射变换学习因子,学习字体倾斜的角度和形变。
在商汤发论文了吗?
没有,正在攒,项目比较重,但有一些work和insight,讲了下思路。(大佬听的很认真,貌似被我的故事打动了[捂脸])
为啥要换实习?日常吹水。
评价:大佬主动评价我对模型理解挺好的,工作做的挺深的,说等下一面吧。
体会:二面面试官说话很快,思维比较敏捷,觉得和这种人讨论问题很欢畅,如果一起工作会很赞。
以后面试说话语速应该快一些,让人觉得思维比较敏捷,这个可能会有加分项吧。
大佬应该是搞backbone模型优化的,问了我怎么迭代基础网络的版本的,日常扯论文,自己的实验结果和理解。
前两个卷积层通道数不用很多,主要是提取边缘、颜色信息,少量的卷积核足矣。
skip connection有什么好处?推了下反向传播公式,根据链式法则,梯度可以直接作用于浅层网络。
初始学习率怎么设?这个我真的没有总结过,只是说一般使用0.01~0.1。
mobileNet、shufflenet的原理?说了下原理。
为什么mobileNet在理论上速度很快,工程上并没有特别大的提升?先说了卷积源码上的实现,两个超大矩阵相乘,可能是group操作,是一些零散的卷积操作,速度会慢。
大佬觉得不满意,说应该从内存上去考虑。申请空间?确实不太清楚。
问我看过哪些前沿的论文?说了说最近两个月的优质的论文。
扯到了tripleLoss,大佬问样本怎么选择?随机,然后就被大佬嫌弃了。装逼失败,这块确实没怎么深入研究。
为什么用multiLoss?多loss权重如何选?训练普通的模型使其收敛,打印反向传播梯度的大小,这表示该task的难度,以此作为loss的权重,然后我补充说了下可以搞一个动态的loss权重,根据一段时间窗口来决定loss的权重。
凸优化了解吗?牛顿法、SGD、最小二乘法,各自的优势。
凸优化其他东西呢?我说只有一些零散的知识点的记忆,纯数学,没有很系统的研究。(面试官貌似数学功底很好,只能认怂)。
感觉有点虚,我尝试着往我会的地方引[捂脸]。 工程上如何对卷积操作进行优化?答:傅立叶模拟卷积。大佬不满意,说那是cudnn早就实现的,还有什么优化吗?(确实不知道,甩锅给工程组)
样本不均衡怎么处理?一个batch类别均等采样,修改loss对不同样本的权重。
三面面试官懂得不少,不过最后还是过了,有时间凸优化还是要系统整理下。
大佬应该不是做深度学习的,应该是机器学习那块的。交流中能感觉出来对这块不是很熟。挑他不会的玩命说,至少让他看到我的工作量。
SVM的KTT条件?说了说,说到SMO实在说不下去了。
GBDT和randomForest区别?原理角度,方差、偏差角度,过拟合角度,谈了谈之前打阿里天池的一些经验吧。
GBDT和xgboost区别?算法上工程上的优化,面试前专门看了,总结的不错,知乎,更多细节可以看看陈天奇的论文,我没看过[捂脸],做机器学习的小伙伴最好看看。
求和接近于target的连续子数组。(lintcode上有类似的题)
最后说让后面应该还有个hr面。


