ในแวดวง AI Yann Lecun ผู้ชนะรางวัล Turing Award ถือเป็นค่าผิดปกติทั่วไป
ในขณะที่ผู้เชี่ยวชาญด้านเทคนิคหลายคนเชื่ออย่างแน่วแน่ว่าตลอดเส้นทางทางเทคนิคในปัจจุบัน การตระหนักถึง AGI เป็นเพียงเรื่องของเวลาเท่านั้น Yann Lecun ก็ได้หยิบยกข้อโต้แย้งซ้ำแล้วซ้ำเล่า
ในการถกเถียงอย่างดุเดือดกับเพื่อนฝูง เขาพูดมากกว่าหนึ่งครั้งว่าเส้นทางเทคโนโลยีกระแสหลักในปัจจุบันไม่สามารถนำเราไปสู่ AGI ได้ และแม้แต่ระดับ AI ในปัจจุบันก็ยังไม่ดีเท่าแมว
ผู้ได้รับรางวัล Turing Award, หัวหน้านักวิทยาศาสตร์ AI ของ Meta, ศาสตราจารย์จากมหาวิทยาลัยนิวยอร์ก ฯลฯ ชื่อที่น่าตื่นตาตื่นใจและประสบการณ์จริงในแนวหน้าอันหนักหน่วงเหล่านี้ ทำให้พวกเราทุกคนไม่สามารถเพิกเฉยต่อข้อมูลเชิงลึกของผู้เชี่ยวชาญ AI คนนี้

Yann LeCun คิดอย่างไรเกี่ยวกับอนาคตของ AI ในการกล่าวสุนทรพจน์ต่อสาธารณะเมื่อเร็วๆ นี้ เขาได้อธิบายมุมมองของเขาอย่างละเอียดอีกครั้งว่า AI ไม่สามารถเข้าถึงสติปัญญาระดับใกล้มนุษย์ได้ โดยอาศัยการฝึกด้วยข้อความเพียงอย่างเดียว
มุมมองบางส่วนมีดังนี้:
1. ในอนาคต โดยทั่วไปผู้คนจะสวมแว่นตาอัจฉริยะหรืออุปกรณ์อัจฉริยะประเภทอื่นๆ อุปกรณ์เหล่านี้จะมีระบบผู้ช่วยในตัวเพื่อจัดตั้งทีมเสมือนจริงอัจฉริยะส่วนบุคคล เพื่อพัฒนาความคิดสร้างสรรค์และประสิทธิภาพส่วนบุคคล
2. จุดประสงค์ของระบบอัจฉริยะไม่ใช่เพื่อแทนที่มนุษย์ แต่เพื่อเพิ่มความฉลาดของมนุษย์เพื่อให้ผู้คนสามารถทำงานได้อย่างมีประสิทธิภาพมากขึ้น
3. แม้แต่แมวเลี้ยงก็มีแบบจำลองในสมองที่ซับซ้อนเกินกว่าที่ระบบ AI จะสร้างได้
4. โดยพื้นฐานแล้ว FAIR ไม่ได้มุ่งเน้นไปที่โมเดลภาษาอีกต่อไป แต่มุ่งสู่เป้าหมายระยะยาวของระบบ AI รุ่นต่อไป
5. ระบบ AI ไม่สามารถบรรลุความฉลาดระดับใกล้มนุษย์โดยการฝึกอบรมเกี่ยวกับข้อมูลข้อความเพียงอย่างเดียว
6. Yann Lecun แนะนำให้ละทิ้งแบบจำลองกำเนิด แบบจำลองความน่าจะเป็น การเรียนรู้แบบเปรียบเทียบและการเรียนรู้แบบเสริมกำลัง และหันมาใช้สถาปัตยกรรม JEPA และแบบจำลองที่ใช้พลังงานแทน โดยเชื่อว่าวิธีการเหล่านี้มีแนวโน้มที่จะส่งเสริมการพัฒนาของ AI มากกว่า
7. แม้ว่าในที่สุดเครื่องจักรจะก้าวข้ามความฉลาดของมนุษย์ไปแล้ว แต่พวกมันก็จะถูกควบคุมเพราะพวกมันขับเคลื่อนด้วยเป้าหมาย
ที่น่าสนใจคือมีตอนหนึ่งก่อนที่สุนทรพจน์จะเริ่มขึ้น
เมื่อพิธีกรแนะนำ LeCun เขาเรียกเขาว่าเป็นหัวหน้านักวิทยาศาสตร์ AI ของ Facebook AI Research Institute (FAIR)
ในเรื่องนี้ LeCun ชี้แจงก่อนสุนทรพจน์ว่า "F" ใน FAIR ไม่ได้เป็นตัวแทนของ Facebook อีกต่อไป แต่หมายถึง " พื้นฐาน "
ข้อความต้นฉบับของสุนทรพจน์ด้านล่างนี้รวบรวมโดย APPSO และได้รับการแก้ไขแล้ว สุดท้ายแนบลิงก์วิดีโอต้นฉบับ: https://www.youtube.com/watch?v=4DsCtgtQlZU
AI ไม่เข้าใจโลกเช่นเดียวกับแมวของคุณ
โอเค ฉันจะพูดถึง AI ระดับมนุษย์ และวิธีที่เราจะไปถึงจุดนั้น และทำไมเราจะไม่ไปถึงจุดนั้น
ประการแรก เราต้องการ AI ระดับมนุษย์จริงๆ
เพราะในอนาคตสิ่งหนึ่งที่พวกเราส่วนใหญ่จะสวมแว่นตาอัจฉริยะหรืออุปกรณ์ประเภทอื่นๆ เรากำลังคุยกับอุปกรณ์เหล่านี้ และระบบเหล่านี้ กำลังจะต้อนรับผู้ช่วย อาจมีมากกว่าหนึ่งคน หรืออาจเป็นทั้งชุดผู้ช่วย
ซึ่งจะส่งผลให้เราแต่ละคนมีทีมเสมือนจริงที่ชาญฉลาดที่ทำงานให้เรา
ดังนั้นทุกคนจะกลายเป็น "เจ้านาย" แต่ "พนักงาน" เหล่านี้ไม่ใช่มนุษย์ที่แท้จริง เราจำเป็นต้องสร้างระบบเช่นนี้ โดยพื้นฐานแล้วเพื่อเพิ่มความฉลาดของมนุษย์ และทำให้ผู้คนมีความคิดสร้างสรรค์และมีประสิทธิภาพมากขึ้น

แต่เพื่อสิ่งนั้น เราต้องการเครื่องจักรที่สามารถเข้าใจโลก จดจำสิ่งต่าง ๆ มีสัญชาตญาณและสามัญสำนึก รวมถึงเหตุผลและการวางแผนในระดับเดียวกับมนุษย์
แม้ว่าคุณอาจเคยได้ยินผู้เสนอบางคนบอกว่าระบบ AI ในปัจจุบันไม่มีความสามารถเหล่านี้ ดังนั้นเราจึงต้องใช้เวลาเพื่อเรียนรู้วิธีสร้างแบบจำลองโลก เพื่อให้มีแบบจำลองทางจิตว่าโลกทำงานอย่างไร
สัตว์แทบทุกตัวมีแบบจำลองเช่นนี้ แมวของคุณต้องมีโมเดลที่ซับซ้อนมากกว่าที่ระบบ AI ใดๆ จะสามารถสร้างหรือออกแบบได้

เราต้องการระบบที่มีหน่วยความจำถาวรซึ่งโมเดลภาษาปัจจุบัน (LLM) ไม่มี ระบบที่สามารถวางแผนลำดับการดำเนินการที่ซับซ้อนซึ่งระบบในปัจจุบันไม่สามารถทำได้ และระบบที่สามารถควบคุมได้และปลอดภัย
ดังนั้น ผมจะเสนอสถาปัตยกรรมที่เรียกว่า AI ที่ขับเคลื่อนตามเป้าหมาย ฉันเขียนรายงานวิสัยทัศน์เกี่ยวกับเรื่องนี้เมื่อประมาณสองปีที่แล้วและตีพิมพ์ หลายคนที่ FAIR กำลังทำงานอย่างหนักเพื่อทำให้แผนนี้เป็นจริง
FAIR เคยทำงานในโครงการแอปพลิเคชันต่างๆ มากขึ้นในอดีต แต่ Meta ได้สร้าง แผนกผลิตภัณฑ์ ที่เรียกว่า Generative AI (Gen AI) เมื่อหนึ่งปีครึ่งที่แล้วเพื่อมุ่งเน้นไปที่ผลิตภัณฑ์ AI
พวกเขาทำการวิจัยและพัฒนาประยุกต์ ดังนั้นตอนนี้ FAIR จึงถูกเปลี่ยนเส้นทางไปสู่เป้าหมายระยะยาวของระบบ AI รุ่นต่อไป โดยพื้นฐานแล้วเราไม่เน้นไปที่โมเดลภาษาอีกต่อไป
ความสำเร็จของ AI รวมถึงโมเดลภาษาขนาดใหญ่ (LLM) และโดยเฉพาะอย่างยิ่งความสำเร็จของระบบอื่นๆ มากมายในช่วง 5 หรือ 6 ปีที่ผ่านมา ขึ้นอยู่กับเทคนิคต่างๆ มากมาย รวมถึงแน่นอนว่าการเรียนรู้แบบมีผู้ดูแลด้วยตนเอง

แกนหลักของการเรียนรู้แบบมีผู้สอนด้วยตนเองคือการฝึกอบรมระบบไม่ใช่สำหรับงานเฉพาะใดๆ แต่เพื่อพยายามแสดงข้อมูลอินพุตในทางที่ดี วิธีหนึ่งในการบรรลุเป้าหมายนี้คือการกู้คืนความเสียหายและสร้างใหม่
ดังนั้นคุณจึงสามารถนำข้อความบางส่วนมาและทำให้เสียหายได้โดยการลบคำบางคำหรือเปลี่ยนคำอื่น กระบวนการนี้สามารถใช้กับข้อความ ลำดับดีเอ็นเอ โปรตีน หรือสิ่งอื่นใด และแม้แต่รูปภาพในระดับหนึ่ง จากนั้นคุณฝึกโครงข่ายประสาทเทียมขนาดใหญ่เพื่อสร้างอินพุตที่สมบูรณ์ขึ้นมาใหม่ ซึ่งเป็นเวอร์ชันที่ไม่เสียหาย
นี่เป็นแบบจำลองเชิงกำเนิดเนื่องจากพยายามสร้างสัญญาณดั้งเดิมขึ้นมาใหม่
กล่องสีแดงก็เหมือนกับฟังก์ชันต้นทุนใช่ไหม? โดยจะคำนวณระยะห่างระหว่างอินพุต Y และเอาต์พุตที่สร้างขึ้นใหม่ y และนี่คือพารามิเตอร์ที่จะย่อให้เล็กสุดในระหว่างกระบวนการเรียนรู้ ในกระบวนการนี้ ระบบจะเรียนรู้การแสดงอินพุตภายใน ซึ่งสามารถนำไปใช้สำหรับงานต่างๆ ตามมาได้
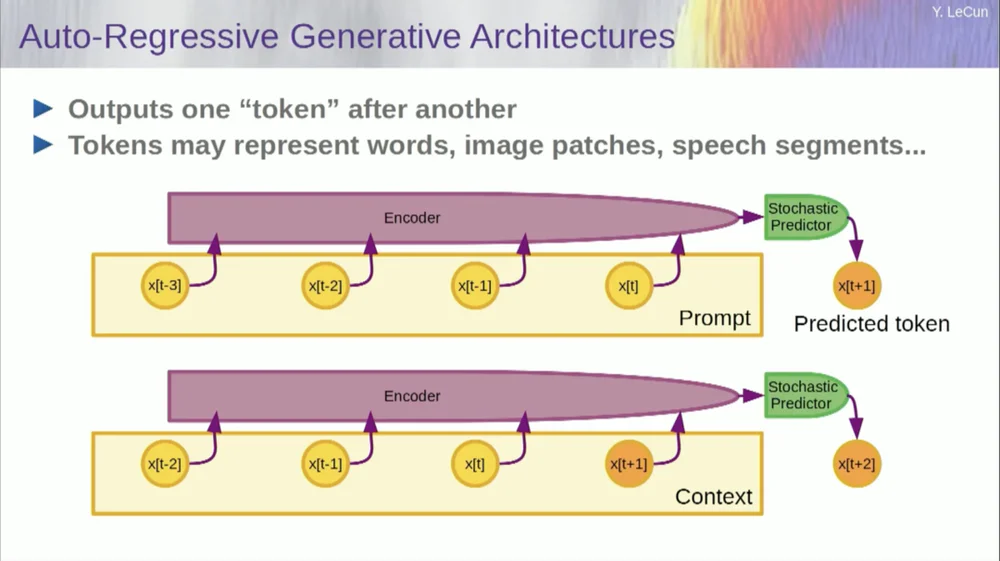
แน่นอนว่าสิ่งนี้สามารถใช้เพื่อทำนายคำในข้อความได้ ซึ่งเป็นสิ่งที่ การทำนายแบบถดถอยอัตโนมัติ ทำ
โมเดลภาษาเป็นกรณีพิเศษในเรื่องนี้ โดยที่สถาปัตยกรรมได้รับการออกแบบในลักษณะที่เมื่อคาดเดารายการ โทเค็น หรือคำ จะสามารถมองไปยังโทเค็นอื่นๆ ทางด้านซ้ายเท่านั้น
มันไม่สามารถมองไปสู่อนาคตได้ หากคุณฝึกระบบอย่างถูกต้อง แสดงข้อความ และขอให้ระบบคาดเดาคำถัดไปหรือโทเค็นถัดไปในข้อความ คุณสามารถใช้ระบบเพื่อคาดเดาคำถัดไปได้ จากนั้นคุณเพิ่มคำถัดไปนั้นในการป้อนข้อมูล ทำนายคำที่สอง และเพิ่มคำนั้นในการป้อนข้อมูล ทำนายคำที่สาม
นี่คือ การทำนายแบบถดถอยอัตโนมัติ
นี่คือสิ่งที่ LLM ทำ ไม่ใช่แนวคิดใหม่ มีมาตั้งแต่สมัย ของแชนนอน ย้อนกลับไปในยุค 50 ซึ่งเป็นเวลานานมาแล้ว แต่การเปลี่ยนแปลงคือตอนนี้เรามีสถาปัตยกรรมโครงข่ายประสาทเทียมขนาดใหญ่เหล่านั้น คุณสามารถฝึกได้ ข้อมูลและฟีเจอร์จำนวนมากจะปรากฏขึ้นมา
แต่การทำนายแบบถดถอยอัตโนมัติประเภทนี้มีข้อจำกัดที่สำคัญบางประการ และไม่มีเหตุผลที่แท้จริงในที่นี้ในแง่ปกติ
ข้อจำกัดอีกประการหนึ่งก็คือ วิธีนี้ใช้ได้กับข้อมูลในรูปแบบของวัตถุ สัญลักษณ์ โทเค็น คำ ฯลฯ ที่แยกจากกันเท่านั้น โดยพื้นฐานแล้วคือสิ่งที่สามารถแยกแยะได้
เรายังขาดสิ่งสำคัญในการบรรลุความฉลาดระดับมนุษย์
ฉันไม่จำเป็นต้องพูดถึงความฉลาดระดับมนุษย์ที่นี่ แต่แม้แต่แมวหรือสุนัขของคุณก็สามารถบรรลุความสำเร็จที่น่าทึ่งซึ่งอยู่นอกเหนือระบบ AI ในปัจจุบันได้

เด็กอายุ 10 ขวบคนไหนก็สามารถเรียนรู้ที่จะเคลียร์โต๊ะและล้างจานในคราวเดียวได้ใช่ไหม? ไม่ต้องฝึกหรืออะไรแบบนั้นใช่ไหม?
เด็กอายุ 17 ปีต้องใช้เวลาฝึกฝนประมาณ 20 ชั่วโมงในการเรียนรู้การขับรถ
เรายังไม่มีรถยนต์ขับเคลื่อนด้วยตนเองระดับ 5 และแน่นอนว่าเราไม่มีหุ่นยนต์ประจำบ้านที่สามารถเคลียร์โต๊ะและเติมเครื่องล้างจานได้
AI จะไม่มีทางเข้าถึงความฉลาดระดับมนุษย์ได้เพียงฝึกฝนผ่านข้อความเพียงอย่างเดียว
ดังนั้นเราจึงขาดสิ่งสำคัญไปมาก มิฉะนั้นเราจะสามารถทำสิ่งเหล่านี้ด้วยระบบ AI ได้
เรามักจะพบกับสิ่งที่เรียกว่า Paradox ของ Moravec ซึ่งก็คือสิ่งที่ดูเหมือนไม่สำคัญสำหรับเราและไม่ถือว่าฉลาดจริงๆ นั้นยากมากที่จะทำกับเครื่องจักร และสิ่งต่างๆ เช่น การยักย้าย การคิดเชิงนามธรรมที่ซับซ้อนระดับสูง เช่น ภาษา ดูเหมือนจะเป็น ง่ายมากสำหรับเครื่องจักร และเช่นเดียวกันกับการเล่นหมากรุกและหมาก
บางทีสาเหตุหนึ่งอาจเป็นเช่นนี้
โดยทั่วไปแล้ว โมเดลภาษาขนาดใหญ่ (LLM) จะได้รับการฝึกบนโทเค็น 20 ล้านล้านโทเค็น
โทเค็นโดยทั่วไปจะมีขนาดสามในสี่ของคำโดยเฉลี่ย จึงมีทั้งหมด 1.5×10^13 คำ แต่ละโทเค็นมีขนาดประมาณ 3B โดยปกติแล้วต้องใช้ขนาด 6×1,013 ไบต์
พวกเราคนใดคนหนึ่งจะใช้เวลาประมาณสองสามแสนปีในการอ่านเรื่องนี้ใช่ไหม? โดยพื้นฐานแล้วนี่คือข้อความสาธารณะทั้งหมดบนอินเทอร์เน็ตรวมกัน

แต่ลองคิดดูสิ เด็กอายุสี่ขวบตื่นมาครบ 16,000 ชั่วโมงแล้ว เรามีเส้นใยประสาทตา 2 ล้านเส้นเข้าสู่สมองของเรา เส้นใยประสาทแต่ละเส้นส่งข้อมูลด้วยความเร็วประมาณ 1B ต่อวินาที หรืออาจจะครึ่งไบต์ต่อวินาที การประมาณการบางอย่างบอกว่านี่อาจเป็น 3B ต่อวินาที
ไม่สำคัญหรอก มันเป็นลำดับความสำคัญอยู่แล้ว
ข้อมูลจำนวนนี้มีค่าประมาณ 10 ถึง 14 ไบต์ของกำลัง ซึ่งเกือบจะเป็นลำดับความสำคัญเดียวกันกับ LLM ดังนั้น ในเวลาสี่ปี เด็กอายุสี่ขวบได้เห็นข้อมูลภาพมากพอๆ กับโมเดลภาษาที่ใหญ่ที่สุดที่ได้รับการฝึกฝนเกี่ยวกับข้อความที่เปิดเผยต่อสาธารณะบนอินเทอร์เน็ตทั้งหมด
การใช้ข้อมูลเป็นจุดเริ่มต้น สิ่งนี้บอกเราหลายอย่าง
ประการแรก สิ่งนี้บอกเราว่า เราไม่สามารถบรรลุความฉลาดระดับมนุษย์ได้เพียงแค่ฝึกฝนข้อความเท่านั้น สิ่งนี้จะไม่เกิดขึ้น
ประการที่สอง ข้อมูลการมองเห็นมีความซ้ำซ้อนมาก เส้นใยประสาทตาแต่ละเส้นส่งข้อมูล 1B ต่อวินาที ซึ่งถูกบีบอัดไว้แล้ว 100 ต่อ 1 เมื่อเปรียบเทียบกับเซลล์รับแสงในเรตินาของคุณ
มีเซลล์รับแสงประมาณ 60 ล้านถึง 100 ล้านตัวในเรตินาของเรา เซลล์รับแสงเหล่านี้ถูกบีบอัดเป็นเส้นใยประสาท 1 ล้านเส้นโดยเซลล์ประสาทที่อยู่ด้านหน้าเรตินา มีการบีบอัด 100 ต่อ 1 อยู่แล้ว จากนั้นเมื่อถึงสมอง ข้อมูลก็จะถูกขยายออกไปประมาณ 50 เท่า
ดังนั้นสิ่งที่ฉันวัดคือข้อมูลที่ถูกบีบอัด แต่ก็ยังซ้ำซ้อนมาก และความซ้ำซ้อนคือสิ่งที่การเรียนรู้แบบมีการดูแลตนเองต้องการจริงๆ การเรียนรู้แบบมีผู้ดูแลด้วยตนเองจะเรียนรู้เฉพาะสิ่งที่มีประโยชน์จากข้อมูลที่ซ้ำซ้อนเท่านั้น หากข้อมูลมีการบีบอัดสูง ซึ่งหมายความว่าข้อมูลกลายเป็นสัญญาณรบกวนแบบสุ่ม คุณจะไม่สามารถเรียนรู้สิ่งใดได้เลย
คุณต้องมีความซ้ำซ้อนเพื่อเรียนรู้อะไรก็ตาม คุณต้องเรียนรู้โครงสร้างพื้นฐานของข้อมูล เราจึงต้องฝึกระบบให้เรียนรู้สามัญสำนึกและฟิสิกส์ด้วยการดูวิดีโอหรือการใช้ชีวิตในโลกแห่งความเป็นจริง
ลำดับคำพูดของฉันอาจทำให้สับสนเล็กน้อย ฉันอยากจะบอกคุณเป็นหลักว่าสถาปัตยกรรมปัญญาประดิษฐ์ที่ขับเคลื่อนด้วยเป้าหมายนี้คืออะไร มันแตกต่างอย่างมากจาก LLM หรือเซลล์ประสาทฟีดฟอร์เวิร์ดตรงที่กระบวนการอนุมานไม่เพียงแค่ผ่านชุดของเลเยอร์ของโครงข่ายประสาทเทียมเท่านั้น แต่จริงๆ แล้วกำลังเรียกใช้อัลกอริธึมการปรับให้เหมาะสมที่สุด
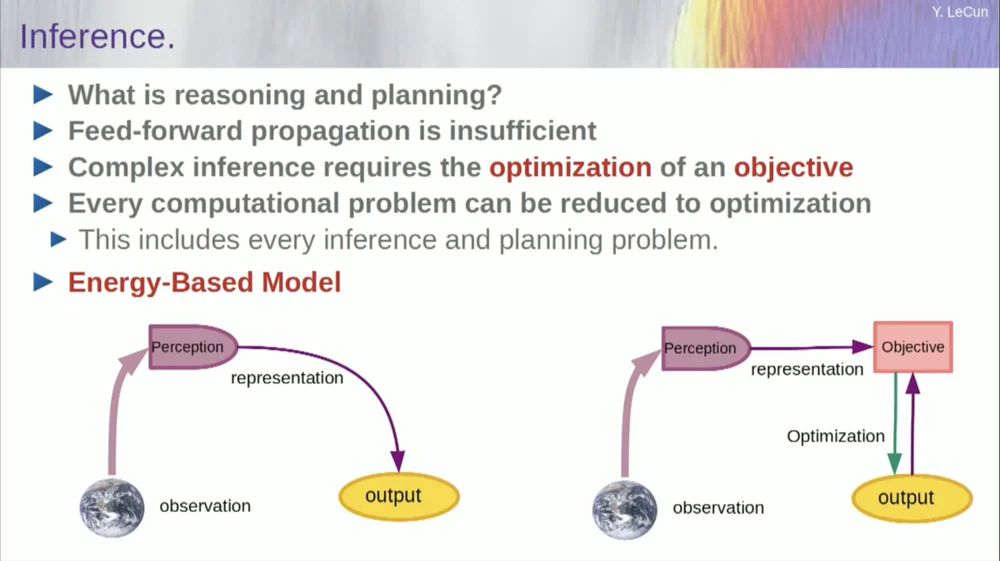
ตามแนวคิดจะมีลักษณะเช่นนี้
กระบวนการป้อนไปข้างหน้าเป็นกระบวนการที่การสังเกตดำเนินผ่านระบบการรับรู้ ตัวอย่างเช่น หากคุณมีเลเยอร์เครือข่ายประสาทเทียมหลายชั้นและสร้างเอาต์พุต ดังนั้นสำหรับอินพุตเดี่ยวใดๆ คุณสามารถมีเอาต์พุตได้เพียงเอาต์พุตเดียว แต่ในหลายกรณี สำหรับการรับรู้ อาจมีการตีความเอาต์พุตที่เป็นไปได้หลายรายการ คุณต้องมีกระบวนการแมปที่ไม่เพียงแต่คำนวณฟังก์ชันการทำงาน แต่ยังให้เอาต์พุตหลายรายการสำหรับอินพุตเดียว วิธีเดียวที่จะบรรลุเป้าหมายนี้คือผ่านฟังก์ชันโดยนัย
โดยพื้นฐานแล้ว กล่องสีแดงทางด้านขวาของกรอบงานเป้าหมายนี้แสดงถึงฟังก์ชันที่วัดความเข้ากันได้ระหว่างอินพุตและเอาต์พุตที่เสนอ จากนั้นจึงคำนวณเอาต์พุตโดยการค้นหาค่าเอาต์พุตที่เข้ากันได้กับอินพุตมากที่สุด คุณสามารถจินตนาการได้ว่าเป้าหมายนี้คือฟังก์ชันพลังงานบางประเภท และคุณกำลังลดพลังงานนี้ให้เหลือน้อยที่สุดโดยให้เอาท์พุตเป็นตัวแปร
คุณอาจมีวิธีแก้ปัญหาหลายอย่าง และคุณอาจมีวิธีจัดการกับวิธีแก้ปัญหาหลายอย่างเหล่านั้น นี่เป็นเรื่องจริงของระบบการรับรู้ของมนุษย์ หากคุณมีการตีความการรับรู้บางอย่างหลายอย่าง สมองของคุณจะหมุนเวียนระหว่างการตีความเหล่านั้นโดยอัตโนมัติ มีหลักฐานบางอย่างที่แสดงว่าเรื่องประเภทนี้เกิดขึ้น
แต่ขอผมกลับไปสู่สถาปัตยกรรมอีกครั้ง ดังนั้นจงใช้ประโยชน์จากหลักการให้เหตุผลนี้โดยการปรับให้เหมาะสม ต่อไปนี้เป็นข้อสันนิษฐานเกี่ยวกับวิธีการทำงานของจิตใจมนุษย์ (ถ้าคุณต้องการ) คุณทำการสังเกตในโลก ระบบการรับรู้ช่วยให้คุณทราบถึงสถานะปัจจุบันของโลก แต่แน่นอนว่ามันจะทำให้คุณเข้าใจถึงสภาวะของโลกที่คุณรับรู้ได้ในปัจจุบันเท่านั้น
คุณอาจมีความคิดบางอย่างที่น่าจดจำเกี่ยวกับสถานะของส่วนอื่นๆ ของโลก ซึ่งอาจรวมกับเนื้อหาในความทรงจำและป้อนเข้าสู่แบบจำลองของโลก
รุ่นคืออะไร? แบบจำลองโลกคือแบบจำลองทางจิตของพฤติกรรมของคุณในโลก ดังนั้นคุณจึงสามารถจินตนาการถึงลำดับของการกระทำที่คุณอาจทำ และแบบจำลองโลกของคุณจะทำให้คุณสามารถทำนายผลกระทบของลำดับของการกระทำเหล่านั้นที่มีต่อโลกได้
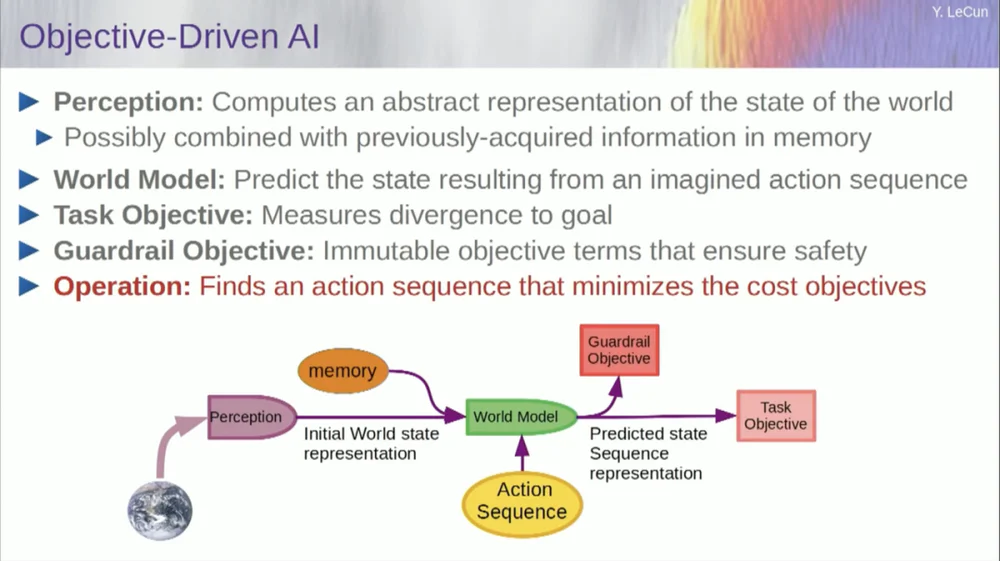
กล่องสีเขียวแสดงถึงแบบจำลองโลก ที่คุณป้อนลำดับการกระทำสมมุติ ที่คาดการณ์ว่าจุดจบของโลกจะเป็นอย่างไร หรือวิถีโคจรทั้งหมดที่คุณคาดการณ์ว่าจะเกิดขึ้นในโลก
คุณรวมมันเข้ากับชุดฟังก์ชันวัตถุประสงค์ เป้าหมายหนึ่งคือการวัดว่าบรรลุเป้าหมายได้ดีเพียงใด ไม่ว่างานจะเสร็จสิ้นหรือไม่ และอาจเป็นชุดของเป้าหมายอื่น ๆ ที่ทำหน้าที่เป็นระยะขอบด้านความปลอดภัย โดยทั่วไปการวัดขอบเขตที่วิถีการเคลื่อนที่ตามมาหรือการกระทำที่เกิดขึ้นไม่ก่อให้เกิดอันตรายต่อหุ่นยนต์ หรือคนรอบข้างเครื่อง ฯลฯ รออยู่
ตอนนี้กระบวนการหาเหตุผล (ฉันยังไม่ได้พูดถึงการเรียนรู้เลย) เป็นเพียงการให้เหตุผลและประกอบด้วยการค้นหาลำดับของการกระทำที่ลดเป้าหมายเหล่านี้ลง การค้นหาลำดับของการกระทำที่ลดเป้าหมายเหล่านี้ นี่คือกระบวนการหาเหตุผล
ดังนั้นจึงไม่ใช่แค่กระบวนการป้อนกลับเท่านั้น คุณสามารถทำได้โดยการค้นหาตัวเลือกแบบแยกส่วน แต่นั่นไม่ได้ผล แนวทางที่ดีกว่าคือทำให้แน่ใจว่ากล่องเหล่านี้ทั้งหมดสามารถสร้างความแตกต่างได้ คุณสามารถเผยแพร่การไล่ระดับสีผ่านกล่องเหล่านั้น จากนั้นอัปเดตลำดับของการดำเนินการผ่านการไล่ระดับสีลงมา

จริงๆ แล้ว แนวคิดนี้ไม่ใช่เรื่องใหม่และมีมานานกว่า 60 ปี หรืออาจจะนานกว่านั้นด้วยซ้ำ ก่อนอื่น ให้ฉันพูดถึงข้อดีของการใช้แบบจำลองโลกสำหรับการให้เหตุผลประเภทนี้ ข้อดีคือคุณสามารถทำงานใหม่ๆ ให้สำเร็จได้โดยไม่จำเป็นต้องเรียนรู้ใดๆ
เราทำสิ่งนี้เป็นครั้งคราว เมื่อเราเผชิญกับสถานการณ์ใหม่ เราคิดถึงมัน จินตนาการถึงผลที่ตามมาของการกระทำของเรา แล้วดำเนินการตามลำดับที่จะบรรลุเป้าหมายของเรา (ไม่ว่าจะเป็นอะไรก็ตาม) เราไม่จำเป็นต้องเรียนรู้ที่จะทำงานนั้นให้สำเร็จ เราก็วางแผนได้ โดยพื้นฐานแล้วนั่นคือการวางแผน
คุณสามารถสรุปการใช้เหตุผลเกือบทุกรูปแบบจนถึงการปรับให้เหมาะสมได้ ดังนั้น กระบวนการอนุมานผ่านการเพิ่มประสิทธิภาพจึงมีประสิทธิภาพมากกว่าการทำงานผ่านโครงข่ายประสาทเทียมหลายชั้น อย่างที่ฉันบอกไป แนวคิดในการใช้เหตุผลผ่านการเพิ่มประสิทธิภาพนี้มีมานานกว่า 60 ปีแล้ว
ในสาขาทฤษฎีการควบคุมที่เหมาะสมที่สุด สิ่งนี้เรียกว่าการควบคุมแบบคาดการณ์ล่วงหน้า
คุณมีโมเดลของระบบที่คุณต้องการควบคุม เช่น จรวด เครื่องบิน หรือหุ่นยนต์ คุณสามารถจินตนาการถึงการใช้แบบจำลองโลกของคุณเพื่อคำนวณผลกระทบของชุดคำสั่งควบคุม
จากนั้นคุณปรับลำดับนี้ให้เหมาะสมเพื่อให้การเคลื่อนไหวบรรลุผลลัพธ์ที่คุณต้องการ การวางแผนการเคลื่อนไหวทั้งหมดในวิทยาการหุ่นยนต์คลาสสิกเสร็จสิ้นในลักษณะนี้ และไม่มีอะไรใหม่ ความแปลกใหม่ที่นี่คือเราจะเรียนรู้แบบจำลองของโลก และระบบการรับรู้จะดึงการนำเสนอนามธรรมที่เหมาะสมออกมา
ตอนนี้ ก่อนที่ฉันจะพูดถึงตัวอย่างวิธีใช้งานระบบนี้ คุณสามารถสร้างระบบ AI โดยรวมที่มีส่วนประกอบทั้งหมดเหล่านี้ได้: โมเดลโลก ฟังก์ชันต้นทุนที่สามารถกำหนดค่าสำหรับงานที่มีอยู่ โมดูลการเพิ่มประสิทธิภาพ (เช่น การเพิ่มประสิทธิภาพอย่างแท้จริง ค้นหาโมดูลที่กำหนดซึ่งกำหนดลำดับการกระทำที่เหมาะสมที่สุดสำหรับแบบจำลองโลก) หน่วยความจำระยะสั้น ระบบการรับรู้ ฯลฯ
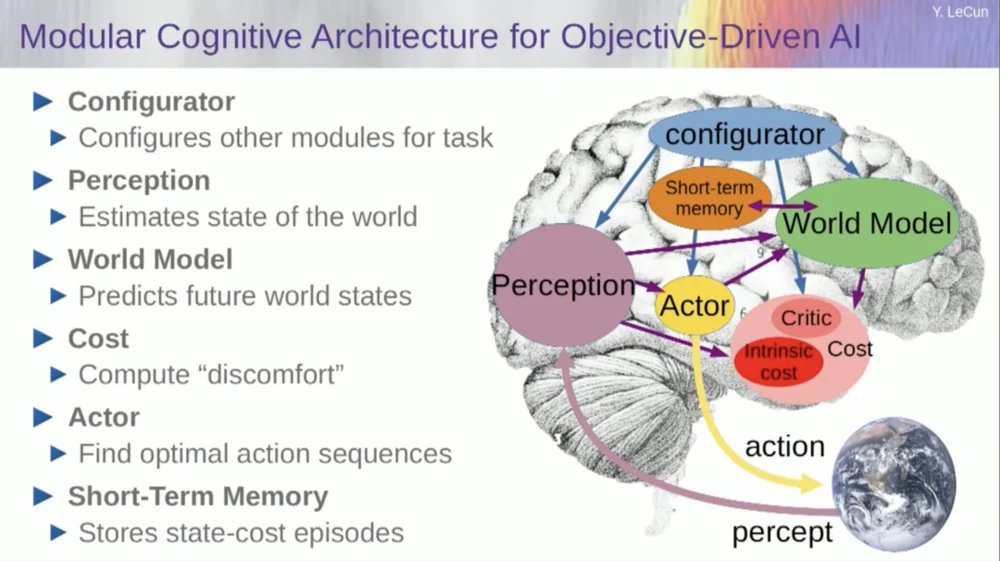
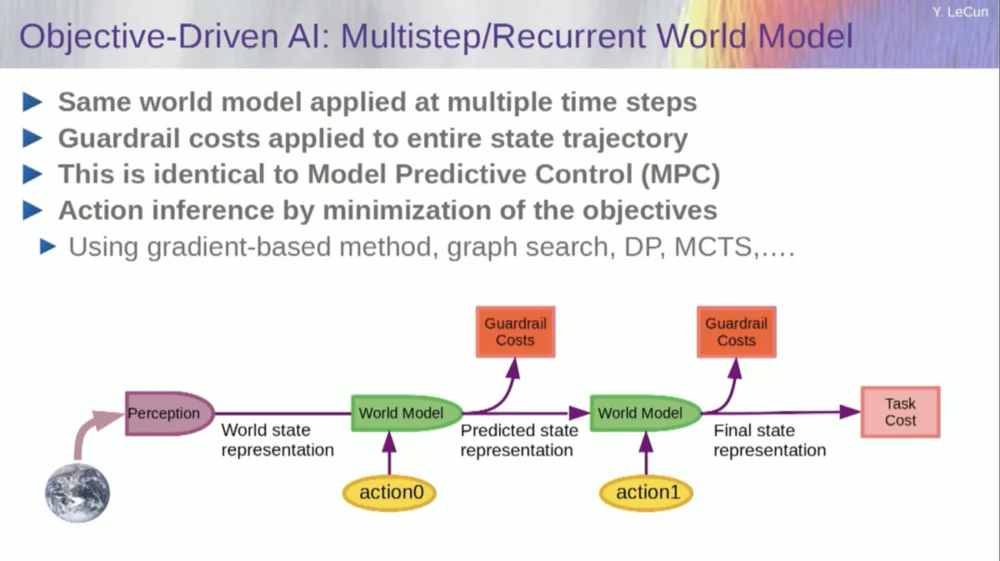
ดังนั้นมันทำงานอย่างไร? หากการกระทำของคุณไม่ใช่การกระทำเดี่ยว แต่เป็นลำดับของการกระทำ และแบบจำลองโลกของคุณคือระบบที่บอกคุณโดยพิจารณาจากสถานะโลก ณ เวลา T และการกระทำที่เป็นไปได้ ให้ทำนายสถานะโลก ณ เวลา T+1
คุณต้องการทำนายว่าลำดับของการกระทำทั้งสองจะมีผลกระทบอย่างไรในสถานการณ์นี้ คุณสามารถรันโมเดลโลกของคุณได้หลายครั้งเพื่อให้บรรลุเป้าหมายนี้
รับการเป็นตัวแทนสถานะโลกเริ่มต้น ป้อนสมมติฐานของศูนย์สำหรับการดำเนินการ ใช้แบบจำลองเพื่อทำนายสถานะถัดไป จากนั้นดำเนินการอย่างใดอย่างหนึ่ง คำนวณสถานะถัดไป คำนวณต้นทุน จากนั้นใช้วิธีการเพิ่มประสิทธิภาพตามการขยายกลับและการไล่ระดับสี ค้นหาว่าอะไรจะลดต้นทุนของการดำเนินการสองครั้งให้เหลือน้อยที่สุด นี่คือการควบคุมแบบจำลองแบบคาดการณ์
ขณะนี้ โลกไม่ได้ถูกกำหนดไว้อย่างสมบูรณ์ ดังนั้นคุณต้องใช้ตัวแปรแฝงเพื่อให้เหมาะกับแบบจำลองของโลกของคุณ ตัวแปรแฝงนั้นเป็นตัวแปรที่สามารถสลับภายในชุดข้อมูลหรือดึงมาจากการแจกแจง และแสดงถึงการสลับแบบจำลองของโลกระหว่างการคาดการณ์หลายอย่างที่เข้ากันได้กับการสังเกต
สิ่งที่น่าสนใจยิ่งกว่านั้นก็คือ ปัจจุบันระบบอัจฉริยะไม่สามารถทำสิ่งที่มนุษย์และแม้แต่สัตว์สามารถทำได้ ซึ่งเป็นการวางแผนแบบลำดับชั้น
ตัวอย่างเช่น หากคุณกำลังวางแผนการเดินทางจากนิวยอร์กไปปารีส คุณสามารถใช้ความเข้าใจเกี่ยวกับโลก ร่างกายของคุณ และบางทีความคิดของคุณเกี่ยวกับการกำหนดค่าทั้งหมดในการเดินทางจากที่นี่ไปปารีสเพื่อวางแผนการเดินทางทั้งหมดกับคุณ การควบคุมกล้ามเนื้อระดับต่ำ
ขวา? หากคุณรวมจำนวนขั้นตอนการควบคุมกล้ามเนื้อต่อสิบมิลลิวินาทีของทุกสิ่งที่คุณต้องทำก่อนไปปารีส มันจะเป็นจำนวนมาก สิ่งที่คุณทำคือวางแผนในแนวทางการวางแผนแบบมีลำดับชั้น โดยเริ่มจากระดับที่สูงมาก แล้วบอกว่า โอเค เพื่อที่จะไปปารีส ฉันต้องไปที่สนามบินก่อน ขึ้นเครื่องบิน
ฉันจะไปสนามบินได้อย่างไร? สมมติว่าฉันอยู่ในนิวยอร์กซิตี้และฉันต้องลงไปชั้นล่างเพื่อเรียกแท็กซี่ ฉันจะลงไปชั้นล่างได้อย่างไร? ต้องลุกจากเก้าอี้ เปิดประตู เดินไปลิฟต์ กดปุ่ม ฯลฯ ฉันจะลุกจากเก้าอี้ได้อย่างไร?
เมื่อถึงจุดหนึ่ง คุณจะต้องแสดงออกถึงการควบคุมกล้ามเนื้อระดับต่ำ แต่เราไม่ได้วางแผนทั้งหมดในระดับต่ำ แต่เรากำลังวางแผนแบบลำดับชั้น

วิธีการทำเช่นนี้โดยใช้ระบบ AI ยังคงไม่ได้รับการแก้ไขอย่างสมบูรณ์และเราไม่ทราบเบาะแส
นี่ดูเหมือนจะเป็นข้อกำหนดที่สำคัญสำหรับพฤติกรรมที่ชาญฉลาด
แล้วเราจะเรียนรู้แบบจำลองโลกที่มีความสามารถในการวางแผนแบบลำดับชั้น สามารถทำงานในระดับนามธรรมที่แตกต่างกันได้อย่างไร ไม่มีใครแสดงอะไรใกล้เคียงนี้ นี่เป็นความท้าทายที่สำคัญ รูปภาพแสดงตัวอย่างที่ฉันเพิ่งพูดถึง
แล้วเราจะฝึกโมเดลโลกนี้ได้อย่างไร? เพราะนี่เป็นปัญหาใหญ่จริงๆ
ฉันพยายามคิดว่าเด็กอายุเท่าไรจึงจะเรียนรู้แนวคิดพื้นฐานเกี่ยวกับโลกได้ พวกเขาเรียนรู้ฟิสิกส์ตามสัญชาตญาณ สัญชาตญาณทางกายภาพ และอะไรพวกนั้นได้อย่างไร? สิ่งนี้เกิดขึ้นนานก่อนที่พวกเขาจะเริ่มเรียนรู้สิ่งต่างๆ เช่น ภาษาและการโต้ตอบ
ดังนั้นความสามารถอย่างการติดตามใบหน้าจึงเกิดขึ้นเร็วมาก การเคลื่อนไหวทางชีวภาพ ความแตกต่างระหว่างวัตถุที่มีชีวิตและไม่มีชีวิตก็ปรากฏขึ้นตั้งแต่เนิ่นๆ เช่นกัน เช่นเดียวกันกับความคงตัวของวัตถุ ซึ่งหมายถึงข้อเท็จจริงที่ว่าวัตถุยังคงอยู่เมื่อถูกวัตถุอื่นบดบัง
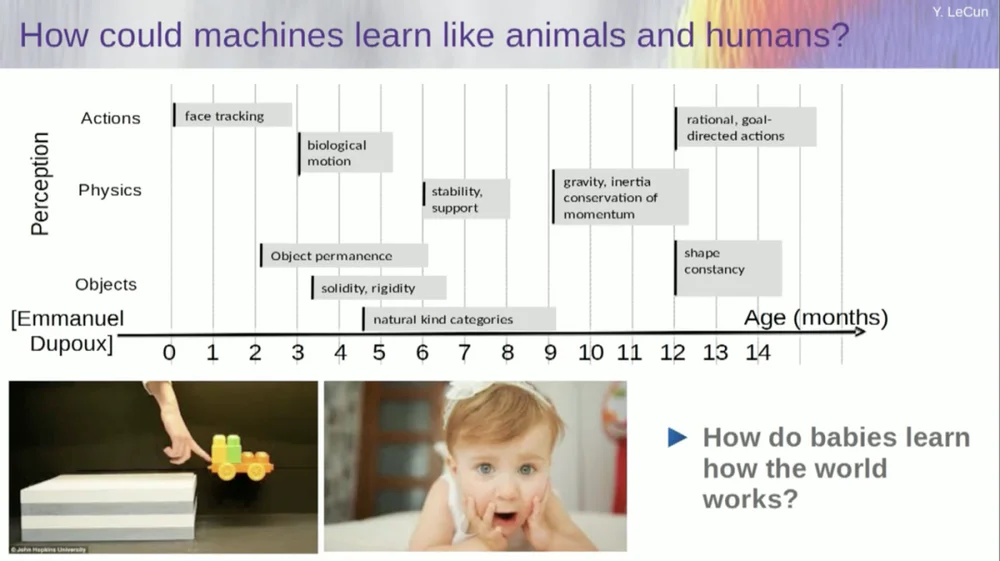
และเด็กทารกเรียนรู้ได้อย่างเป็นธรรมชาติ คุณไม่จำเป็นต้องตั้งชื่อสิ่งต่าง ๆ ให้พวกเขา พวกเขาจะรู้ว่าเก้าอี้ โต๊ะ และแมวนั้นแตกต่างกัน สำหรับแนวคิดต่างๆ เช่น เสถียรภาพและการรองรับ เช่น แรงโน้มถ่วง ความเฉื่อย การอนุรักษ์ และโมเมนตัม จริงๆ แล้วสิ่งเหล่านี้จะไม่ปรากฏจนกว่าจะอายุประมาณเก้าเดือน
การดำเนินการนี้ใช้เวลานาน ดังนั้น หากคุณแสดงสถานการณ์ทางด้านซ้ายให้ทารกอายุ 6 เดือนดู โดยที่รถเข็นอยู่บนชานชาลา และคุณผลักมันออกจากชานชาลา ดูเหมือนว่ารถเข็นจะลอยอยู่ในอากาศ ทารกอายุหกเดือนจะสังเกตเห็นสิ่งนี้ ในขณะที่ทารกอายุสิบเดือนจะรู้สึกว่าสิ่งนี้ไม่ควรเกิดขึ้นและสิ่งของควรจะหล่นลงมา
เมื่อมีสิ่งไม่คาดฝันเกิดขึ้น นั่นหมายความว่า "แบบจำลองของโลก" ของคุณผิดพลาด ดังนั้นคุณต้องใส่ใจเพราะมันอาจฆ่าคุณได้
ดังนั้นประเภทของการเรียนรู้ที่ต้องเกิดขึ้นที่นี่จึงคล้ายกับประเภทของการเรียนรู้ที่เราพูดคุยกันก่อนหน้านี้มาก
รับอินพุต ทำให้เสียหายในทางใดทางหนึ่ง และฝึกโครงข่ายประสาทเทียมขนาดใหญ่เพื่อทำนายส่วนที่ขาดหายไป หากคุณฝึกระบบให้คาดการณ์ว่าจะเกิดอะไรขึ้นในวิดีโอ เช่นเดียวกับที่เราฝึกโครงข่ายประสาทเทียมให้คาดเดาสิ่งที่จะเกิดขึ้นในรูปแบบข้อความ บางทีระบบเหล่านั้นอาจจะสามารถเรียนรู้สามัญสำนึกได้
น่าเสียดาย ที่เราลองทำสิ่งนี้มาสิบปีแล้ว แต่ก็ล้มเหลวโดยสิ้นเชิง เราไม่เคยเข้าใกล้ระบบที่สามารถเรียนรู้ความรู้ทั่วไปใดๆ ได้จริงๆ โดยเพียงแค่พยายามคาดเดาพิกเซลในวิดีโอ
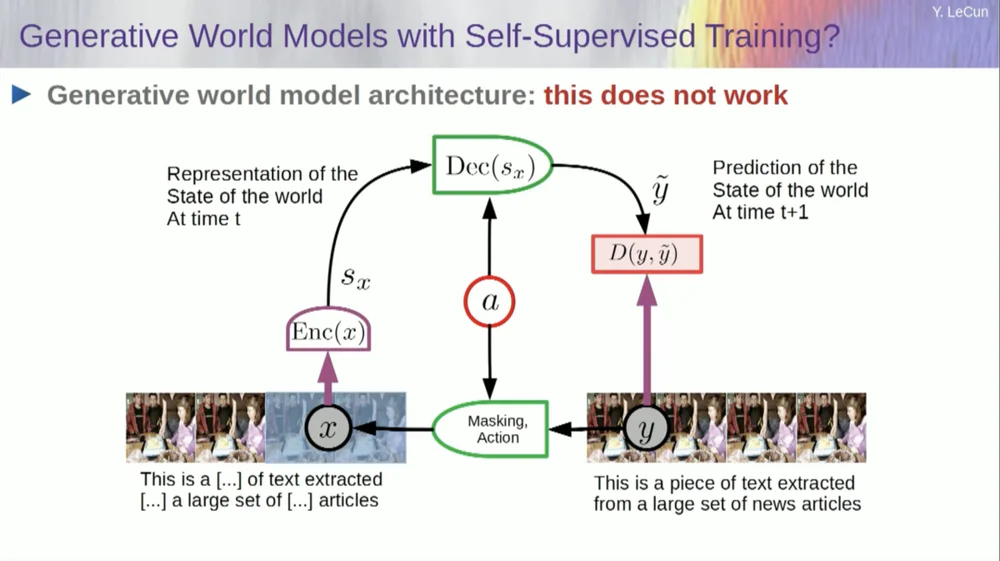
คุณสามารถฝึกระบบให้คาดการณ์วิดีโอที่ดูดีได้ มีตัวอย่างมากมายของระบบการสร้างวิดีโอ แต่ภายในแล้ว ระบบเหล่านี้ไม่ใช่แบบอย่างที่ดีของโลกทางกายภาพ เราไม่สามารถทำเช่นนี้กับพวกเขาได้
โอเค ความคิดที่ว่า เราจะใช้แบบจำลองกำเนิด เพื่อทำนายสิ่งที่จะเกิดขึ้นกับแต่ละบุคคล และระบบจะเข้าใจโครงสร้างของโลกอย่างน่าอัศจรรย์ ถือเป็นความล้มเหลวโดยสิ้นเชิง
ในช่วงทศวรรษที่ผ่านมา เราได้ลองใช้แนวทางต่างๆ มากมาย
มันล้มเหลวเพราะมีอนาคตที่เป็นไปได้มากมาย ในพื้นที่แยก เช่น ข้อความ ซึ่งคุณสามารถคาดเดาได้ว่าคำใดจะตามหลังชุดคำ คุณสามารถสร้างการแจกแจงความน่าจะเป็นเหนือคำที่เป็นไปได้ในพจนานุกรม แต่เมื่อพูดถึงเฟรมวิดีโอ เราไม่มีวิธีที่ดีในการแสดงการกระจายความน่าจะเป็นของเฟรมวิดีโอ ที่จริงแล้วงานนี้เป็นไปไม่ได้เลย

แบบว่าผมถ่ายวีดีโอห้องนี้ไว้ใช่ไหม? ฉันหยิบกล้องขึ้นมาถ่ายส่วนนั้นแล้วหยุดวิดีโอ ฉันถามระบบว่าจะเกิดอะไรขึ้นต่อไป มันอาจทำนายห้องที่เหลือ จะมีกำแพงมีคนนั่งอยู่บนนั้นและความหนาแน่นอาจจะใกล้เคียงกับด้านซ้าย แต่มันเป็นไปไม่ได้เลยที่จะทำนายรายละเอียดทั้งหมดว่าคุณแต่ละคนจะมีลักษณะอย่างไรในระดับพิกเซลอย่างแม่นยำ พื้นผิวของโลก และขนาดที่แน่นอนของห้อง
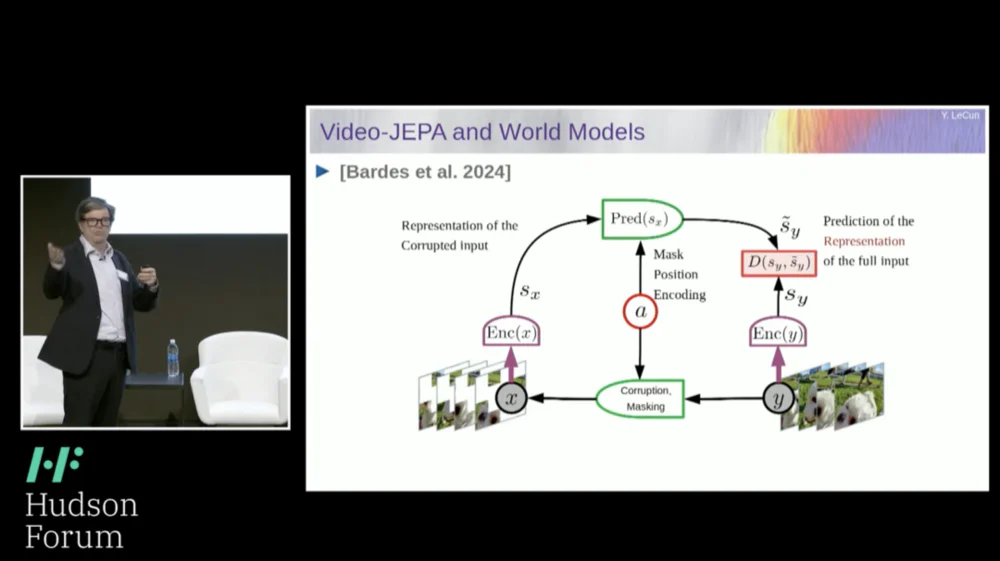
ดังนั้น วิธีแก้ปัญหาที่ฉันเสนอคือ Joint Embedding Prediction Architecture (JEPA)
แนวคิดคือการละทิ้งการทำนายพิกเซลและเรียนรู้การนำเสนอเชิงนามธรรมเกี่ยวกับวิธีการทำงานของโลกแทน จากนั้นจึงทำการคาดการณ์ภายในพื้นที่การเป็นตัวแทนนี้ นั่นคือสถาปัตยกรรม ซึ่งเป็นสถาปัตยกรรมการทำนายที่ฝังร่วมกัน การฝังทั้งสองนี้ใช้ X (เวอร์ชันที่เสียหาย) และ Y ตามลำดับ ได้รับการประมวลผลโดยตัวเข้ารหัส จากนั้นระบบจะได้รับการฝึกอบรมให้คาดการณ์การแทนค่าของ Y ตามการแทนค่าของ X
ตอนนี้ปัญหาก็คือว่า ถ้าคุณฝึกระบบดังกล่าวโดยใช้การไล่ระดับสีแบบไล่ระดับ การขยายพันธุ์แบบย้อนกลับเพื่อลดข้อผิดพลาดในการทำนาย ระบบก็จะพังทลายลง อาจเรียนรู้การนำเสนออย่างต่อเนื่องเพื่อให้การคาดการณ์กลายเป็นเรื่องง่าย แต่ไม่มีข้อมูล
ดังนั้นสิ่งที่ฉันต้องการให้คุณจำคือความแตกต่างระหว่างตัวเข้ารหัสอัตโนมัติ สถาปัตยกรรมแบบกำเนิด ตัวเข้ารหัสอัตโนมัติแบบมาสก์ ฯลฯ ซึ่งพยายามสร้างการทำนายขึ้นใหม่ เทียบกับสถาปัตยกรรมแบบฝังร่วมที่ทำการคาดการณ์ในพื้นที่การเป็นตัวแทน
ฉันคิดว่าอนาคตอยู่ที่สถาปัตยกรรมการฝังร่วมกันเหล่านี้ และเรามีหลักฐานเชิงประจักษ์มากมายว่าวิธีที่ดีที่สุดในการเรียนรู้การนำเสนอภาพที่ดีคือการใช้สถาปัตยกรรมการแก้ไขร่วมกัน
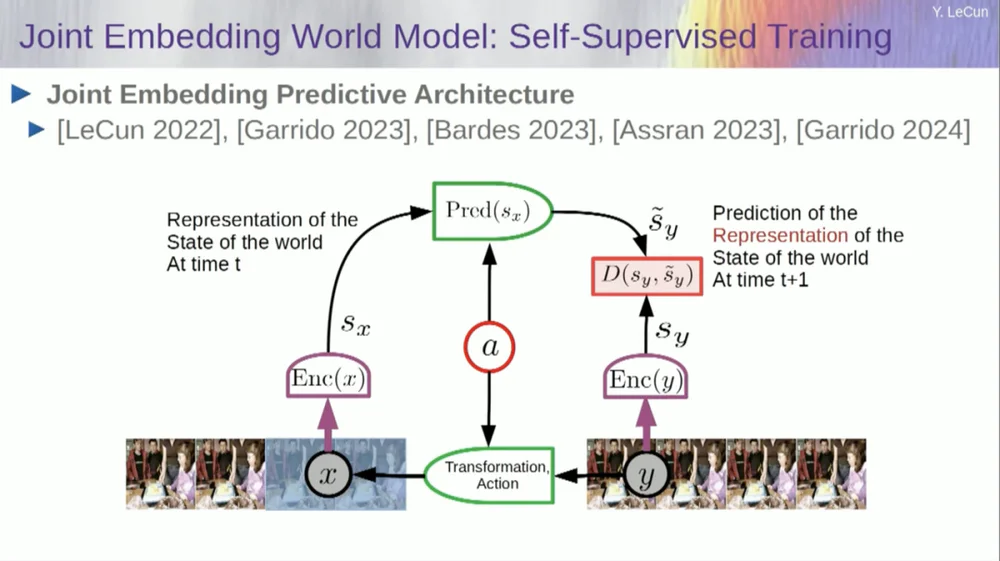
ความพยายามทั้งหมดในการเรียนรู้การนำเสนอภาพผ่านการสร้างใหม่นั้นทำได้ไม่ดีนักและทำงานได้ไม่ดีนัก และแม้ว่าจะมีโครงการขนาดใหญ่หลายโครงการที่อ้างว่าได้ผล แต่ก็ไม่ได้ผล และสถาปัตยกรรมทางด้านขวาจะมีประสิทธิภาพดีที่สุด
ทีนี้ ถ้าคุณลองคิดดู นี่คือความฉลาดของเราจริงๆ การค้นหาการนำเสนอปรากฏการณ์ที่ดี เพื่อที่เราจะสามารถคาดการณ์ได้ นั่นคือสิ่งที่วิทยาศาสตร์เป็นจริงๆ
จริง. ลองคิดดูว่า หากคุณต้องการทำนายวิถีโคจรของดาวเคราะห์ ดาวเคราะห์เป็นวัตถุที่ซับซ้อนมาก มันใหญ่มาก และมีลักษณะเฉพาะทุกประเภท เช่น สภาพอากาศ อุณหภูมิ และความหนาแน่น
แม้ว่ามันจะเป็นวัตถุที่ซับซ้อน แต่ในการทำนายวิถีโคจรของดาวเคราะห์ คุณเพียงแค่ต้องรู้ตัวเลข 6 ตัวเท่านั้น: พิกัดตำแหน่ง 3 ตัว และเวกเตอร์ความเร็ว 3 ตัว แค่นั้นเอง คุณไม่จำเป็นต้องทำอะไรอีก นี่เป็นตัวอย่างที่สำคัญมากซึ่งแสดงให้เห็นจริงๆ ว่าแก่นแท้ของอำนาจการทำนายอยู่ที่การค้นหาการเป็นตัวแทนที่ดีของสิ่งที่เราสังเกตเห็น

แล้วเราจะฝึกระบบดังกล่าวได้อย่างไร?
ดังนั้นคุณต้องการป้องกันไม่ให้ระบบล่ม วิธีหนึ่งในการทำเช่นนี้คือการใช้ฟังก์ชันต้นทุนบางประเภทที่จะวัดเนื้อหาข้อมูลของเอาต์พุตการเป็นตัวแทนโดยตัวเข้ารหัส และพยายามเพิ่มเนื้อหาข้อมูลให้สูงสุดและลดข้อมูลเชิงลบให้เหลือน้อยที่สุด ระบบการฝึกอบรมของคุณควรดึงข้อมูลออกจากอินพุตให้มากที่สุดเท่าที่จะเป็นไปได้พร้อมๆ กัน ในขณะเดียวกันก็ลดข้อผิดพลาดในการทำนายในพื้นที่การแสดงนั้นให้เหลือน้อยที่สุด
ระบบจะค้นหาข้อดีข้อเสียระหว่างการดึงข้อมูลให้ได้มากที่สุด กับการไม่ดึงข้อมูลที่คาดเดาไม่ได้ คุณจะได้รับพื้นที่การนำเสนอที่ดีซึ่งสามารถคาดการณ์ได้
แล้วคุณจะวัดข้อมูลได้อย่างไร? นี่คือสิ่งที่แปลกเล็กน้อย ฉันจะข้ามสิ่งนี้
เครื่องจักรจะก้าวข้ามความฉลาดของมนุษย์และปลอดภัยและควบคุมได้
จริงๆ แล้วมีวิธีทำความเข้าใจเรื่องนี้ทางคณิตศาสตร์ผ่านการฝึก แบบจำลองพลังงาน และฟังก์ชันพลังงาน แต่ฉันไม่มีเวลาพูดถึงมัน
โดยพื้นฐานแล้ว ฉันกำลังบอกคุณถึงสิ่งที่แตกต่างกันสองสามอย่างที่นี่ ละทิ้งแบบจำลองการกำเนิด เพื่อสนับสนุนสถาปัตยกรรม JEPA เหล่านั้น ละทิ้งแบบจำลองความน่าจะเป็น หันไปสนับสนุนแบบจำลองที่ใช้พลังงาน ละทิ้งวิธีการเรียนรู้แบบเปรียบเทียบ และการเรียนรู้แบบเสริมกำลัง ฉันพูดคำนี้มา 10 ปีแล้ว
และ นี่คือเสาหลักสี่ประการของการเรียนรู้ของเครื่องที่ได้รับความนิยมมากที่สุดในปัจจุบัน ตอนนี้ฉันคงไม่เป็นที่นิยมมากนัก
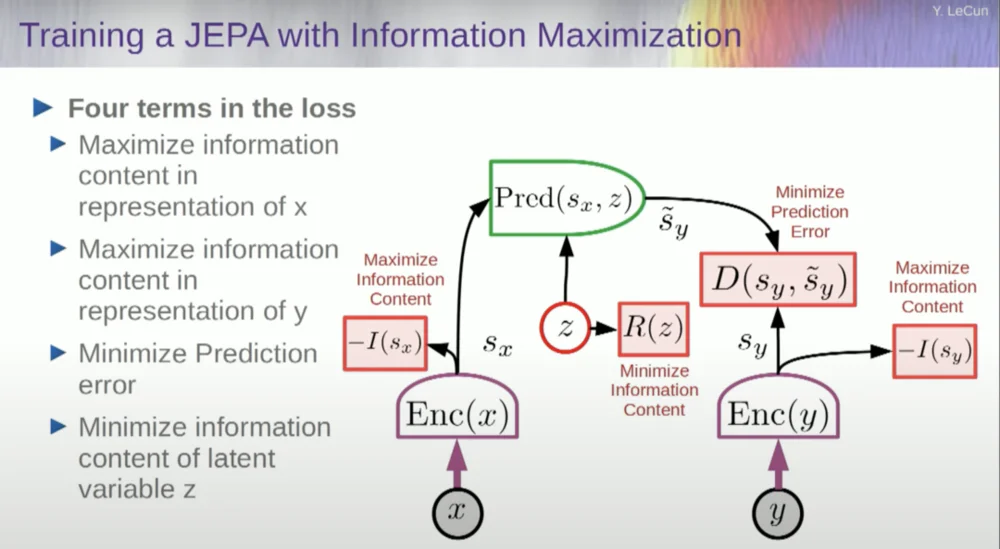
แนวทางหนึ่งคือการประมาณเนื้อหาข้อมูล โดยการวัดเนื้อหาข้อมูลที่มาจากตัวเข้ารหัส
ขณะนี้มีหกวิธีที่แตกต่างกันในการบรรลุเป้าหมายนี้ จริงๆ แล้ว มีวิธีที่เรียกว่า MCR จากเพื่อนร่วมงานของฉันที่ NYU ซึ่งก็คือป้องกันไม่ให้ระบบหยุดทำงานและสร้างค่าคงที่
นำตัวแปรจากตัวเข้ารหัสและตรวจสอบให้แน่ใจว่าตัวแปรเหล่านี้มีค่าเบี่ยงเบนมาตรฐานที่ไม่เป็นศูนย์ คุณสามารถใส่สิ่งนี้ลงในฟังก์ชันต้นทุนและตรวจสอบให้แน่ใจว่าได้ค้นหาน้ำหนักแล้ว และตัวแปรจะไม่ยุบและกลายเป็นค่าคงที่ นี่ค่อนข้างง่าย
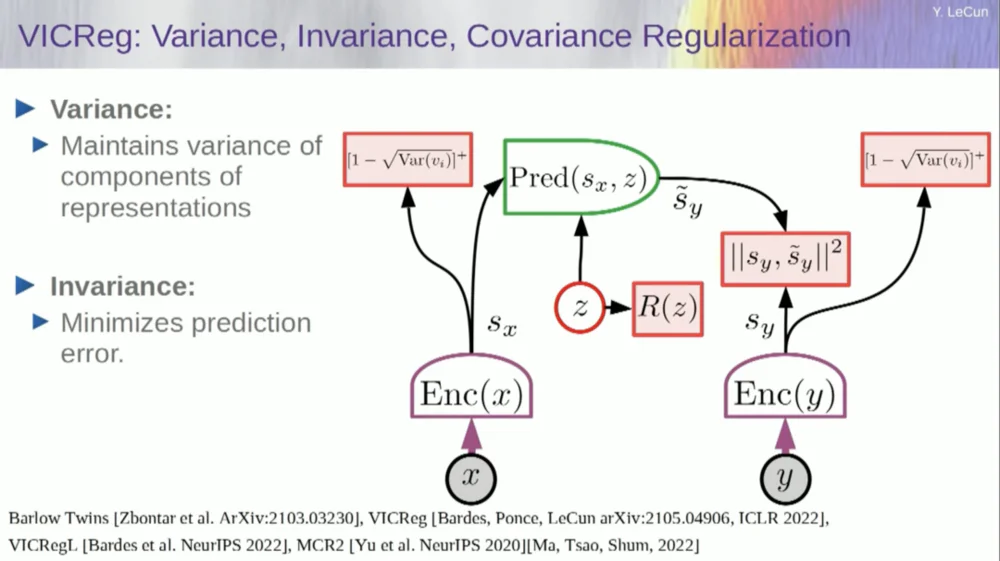
ปัญหาตอนนี้คือระบบสามารถ "โกง" และทำให้ตัวแปรทั้งหมดเท่ากันหรือมีความสัมพันธ์กันสูง ดังนั้น คุณต้องเพิ่มเทอมอีกเทอมหนึ่ง ซึ่งเป็นเทอมนอกแนวทแยงที่จำเป็นในการลดเมทริกซ์ความแปรปรวนร่วมของตัวแปรเหล่านี้ให้เหลือน้อยที่สุด เพื่อให้แน่ใจว่าพวกมันเกี่ยวข้องกัน
แน่นอนว่านี่ยังไม่เพียงพอ เนื่องจากตัวแปรอาจยังคงขึ้นอยู่กับตัวแปรแต่ไม่เกี่ยวข้องกัน ดังนั้นเราจึงนำวิธีอื่นมาใช้เพื่อขยายขนาดของ SX ไปยังพื้นที่มิติที่สูงกว่า VX และใช้การทำให้ความแปรปรวนร่วม-ความแปรปรวนร่วมสม่ำเสมอในพื้นที่นี้เพื่อให้แน่ใจว่าเป็นไปตามข้อกำหนด
มีเคล็ดลับอีกอย่างหนึ่งที่นี่ เพราะสิ่งที่ฉันเพิ่มให้สูงสุดคือขีดจำกัดบนของเนื้อหาข้อมูล ฉันต้องการให้เนื้อหาข้อมูลจริงเป็นไปตามขีดจำกัดสูงสุดของฉัน สิ่งที่ฉันต้องการคือขีดจำกัดล่างเพื่อที่จะดันขีดจำกัดล่างและข้อมูลจะเพิ่มขึ้น ขออภัย เราไม่มีข้อมูลเกี่ยวกับขอบเขตล่าง หรืออย่างน้อย เราก็ไม่ทราบวิธีคำนวณ
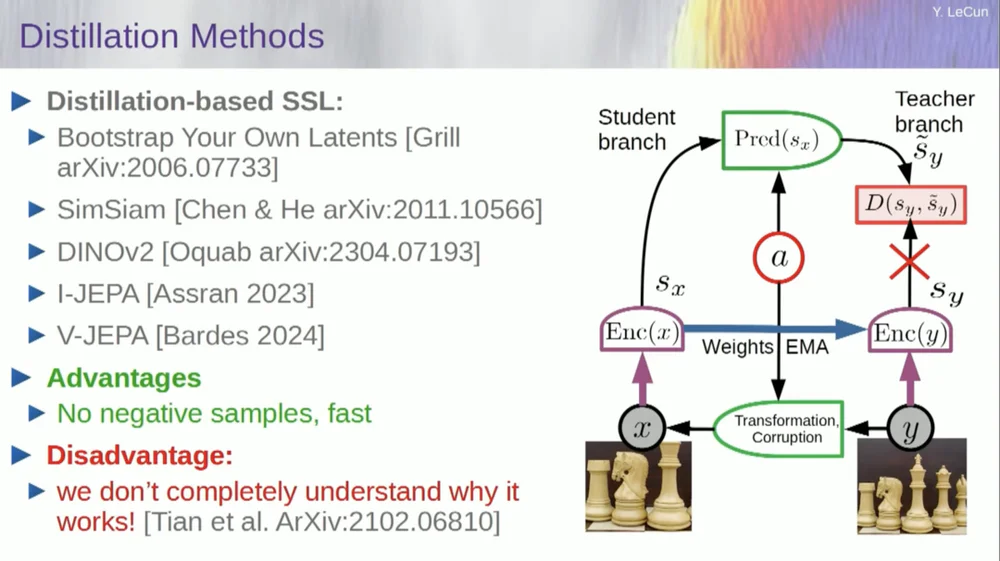
มีวิธีการชุดที่สองที่เรียกว่า "วิธีรูปแบบการกลั่น"
วิธีนี้ใช้ได้ผลในลักษณะลึกลับ ถ้าอยากรู้ว่าใครกำลังทำอะไรอยู่ ก็ไปถามผู้ชายที่นั่งอยู่ที่เดอะกริลล์ได้เลย
เขามีเรียงความส่วนตัวเกี่ยวกับเรื่องนี้ที่กำหนดได้ดีมาก แนวคิดหลักคือการอัปเดตเพียงส่วนหนึ่งของโมเดลโดยไม่ต้องเผยแพร่การไล่ระดับสีในส่วนอื่น และแบ่งปันน้ำหนักด้วยวิธีที่น่าสนใจ นอกจากนี้ยังมีเอกสารหลายฉบับเกี่ยวกับเรื่องนี้
แนวทางนี้ใช้ได้ผลดีหากคุณต้องการฝึกระบบที่มีการดูแลตนเองอย่างเต็มรูปแบบเพื่อสร้างการแสดงภาพที่ดี การทำลายภาพทำได้โดยการมาสก์ และงานล่าสุดบางอย่างที่เราได้ทำกับวิดีโอทำให้เราสามารถฝึกอบรมระบบเพื่อแยกการนำเสนอวิดีโอที่ดีเพื่อใช้ในงานดาวน์สตรีม เช่น วิดีโอการจดจำการกระทำ ฯลฯ คุณจะเห็นว่าการปกปิดวิดีโอจำนวนมากและการคาดการณ์ผ่านกระบวนการนี้ใช้เคล็ดลับการกลั่นนี้ในพื้นที่การนำเสนอเพื่อป้องกันการล่มสลาย มันใช้งานได้ดี
ดังนั้นหากเราประสบความสำเร็จในโครงการนี้ และจบลงด้วยระบบที่สามารถให้เหตุผล วางแผน และเข้าใจโลกทางกายภาพได้ ปฏิสัมพันธ์ทั้งหมดของเราจะมีลักษณะเช่นนี้ในอนาคต
จะต้องใช้เวลาหลายปีหรือถึงสิบปีกว่าจะทำให้ทุกอย่างทำงานได้อย่างถูกต้อง Mark Zuckerberg คอยถามฉันว่าจะใช้เวลานานแค่ไหน ถ้าเราประสบความสำเร็จในการทำเช่นนั้น โอเค เราจะมีระบบที่เป็นสื่อกลางในการโต้ตอบทั้งหมดของเรากับโลกดิจิทัล พวกเขาจะตอบทุกคำถามของเรา
พวกเขาจะอยู่กับเราเป็นเวลานานและจะเป็นแหล่งความรู้ของมนุษย์ทั้งหมด สิ่งนี้ให้ความรู้สึกเหมือนเป็นโครงสร้างพื้นฐาน เช่น อินเทอร์เน็ต นี่เป็นผลิตภัณฑ์น้อยกว่าและมีโครงสร้างพื้นฐานมากกว่า
แพลตฟอร์ม AI เหล่านี้ต้องเป็นโอเพ่นซอร์ส IBM และ Meta เข้าร่วมในกลุ่มที่เรียกว่า Artificial Intelligence Alliance ซึ่งส่งเสริมแพลตฟอร์มปัญญาประดิษฐ์แบบโอเพ่นซอร์ส เราต้องการให้แพลตฟอร์มเหล่านี้เป็นโอเพ่นซอร์สเพราะเราต้องการความหลากหลายในระบบ AI เหล่านี้

เราต้องการให้พวกเขาเข้าใจทุกภาษา ทุกวัฒนธรรม ทุกระบบคุณค่าในโลก และคุณจะไม่ได้รับสิ่งนั้นจากระบบเดียวที่ผลิตโดยบริษัทในชายฝั่งตะวันตกหรือชายฝั่งตะวันออกของสหรัฐ รัฐ. นี่จะต้องเป็นผลงานจากทั่วทุกมุมโลก
แน่นอนว่าการฝึกอบรมโมเดลทางการเงินมีราคาแพงมาก จึงมีเพียงไม่กี่บริษัทเท่านั้นที่สามารถทำได้ หากบริษัทอย่าง Meta สามารถจัดหาโมเดลพื้นฐานเป็นโอเพ่นซอร์สได้ โลกก็จะสามารถปรับแต่งโมเดลดังกล่าวตามวัตถุประสงค์ของตนเองได้ นี่คือปรัชญาที่ Meta และ IBM นำมาใช้

ดังนั้น AI แบบโอเพ่นซอร์สจึงไม่ใช่แค่ความคิดที่ดีเท่านั้น แต่ยังจำเป็นสำหรับความหลากหลายทางวัฒนธรรม และอาจถึงขั้นรักษาประชาธิปไตยด้วยซ้ำ
การฝึกอบรมและการปรับแต่งจะดำเนินการผ่านการระดมทุนจากมวลชนหรือโดยระบบนิเวศของสตาร์ทอัพและบริษัทอื่นๆ
นั่นเป็นหนึ่งในสิ่งที่ขับเคลื่อนการเติบโตของระบบนิเวศสตาร์ทอัพ AI ก็คือความพร้อมใช้งานของโมเดล AI แบบโอเพ่นซอร์สเหล่านี้ จะใช้เวลานานแค่ไหนในการเข้าถึงปัญญาประดิษฐ์ทั่วไป? ไม่รู้สิ อาจจะต้องใช้เวลาหลายปีถึงหลายสิบปี

มีการเปลี่ยนแปลงมากมายระหว่างทางและยังคงมีปัญหามากมายที่ต้องแก้ไข นี่เกือบจะยากกว่าที่เราคิดอย่างแน่นอน สิ่งนี้ไม่ได้เกิดขึ้นในวันเดียว แต่เป็นวิวัฒนาการที่ค่อยเป็นค่อยไป
ดังนั้นไม่ใช่ว่าสักวันหนึ่งเราจะค้นพบความลับของปัญญาประดิษฐ์ทั่วไป เปิดเครื่องและมีปัญญาขั้นสูงทันที และเราทุกคนจะถูกกำจัดโดยปัญญาประดิษฐ์ขั้นสูง ไม่ นั่นไม่ใช่กรณีนี้
เครื่องจักรจะเหนือกว่าสติปัญญาของมนุษย์ แต่พวกมันจะอยู่ภายใต้การควบคุมเพราะพวกมันขับเคลื่อนด้วยเป้าหมาย เราตั้งเป้าหมายให้พวกเขาและพวกเขาก็บรรลุเป้าหมาย เช่นเดียวกับพวกเราหลายคนที่นี่เป็นผู้นำในอุตสาหกรรมหรือด้านวิชาการ
เราทำงานร่วมกับคนที่ฉลาดกว่าเรา และฉันก็ทำเช่นกัน เพียงเพราะมีคนที่ฉลาดกว่าฉันจำนวนมากไม่ได้หมายความว่าพวกเขาต้องการครองหรือเข้ายึดครอง นั่นเป็นเพียงความจริงของเรื่องนี้ แน่นอนว่ามีความเสี่ยงอยู่เบื้องหลัง แต่ฉันจะทิ้งไว้เพื่อหารือในภายหลัง ขอบคุณมาก