ด้วยการพัฒนาอย่างรวดเร็วของเทคโนโลยี AI ความต้องการโมเดลภาษาภาพจึงเพิ่มขึ้นทุกวัน แต่ความต้องการทรัพยากรการประมวลผลที่สูงจะจำกัดการใช้งานบนอุปกรณ์ทั่วไป เครื่องมือแก้ไขของ Downcodes จะแนะนำให้คุณรู้จักกับโมเดลภาษาภาพน้ำหนักเบาที่เรียกว่า SmolVLM ซึ่งสามารถทำงานได้อย่างมีประสิทธิภาพบนอุปกรณ์ที่มีทรัพยากรจำกัด เช่น แล็ปท็อปและ GPU ระดับผู้บริโภค การเกิดขึ้นของ SmolVLM ทำให้ผู้ใช้มีโอกาสสัมผัสกับเทคโนโลยี AI ขั้นสูงมากขึ้น ลดเกณฑ์การใช้งาน และยังช่วยให้นักพัฒนามีเครื่องมือวิจัยที่สะดวกยิ่งขึ้นอีกด้วย
ในช่วงไม่กี่ปีที่ผ่านมา มีความต้องการใช้งานโมเดล Machine Learning ในงานด้านการมองเห็นและภาษาเพิ่มมากขึ้น แต่โมเดลส่วนใหญ่ต้องการทรัพยากรการประมวลผลจำนวนมาก และไม่สามารถทำงานได้อย่างมีประสิทธิภาพบนอุปกรณ์ส่วนบุคคล โดยเฉพาะอย่างยิ่งอุปกรณ์ขนาดเล็ก เช่น แล็ปท็อป GPU สำหรับผู้บริโภค และอุปกรณ์มือถือ เผชิญกับความท้าทายครั้งใหญ่เมื่อประมวลผลงานภาษาภาพ
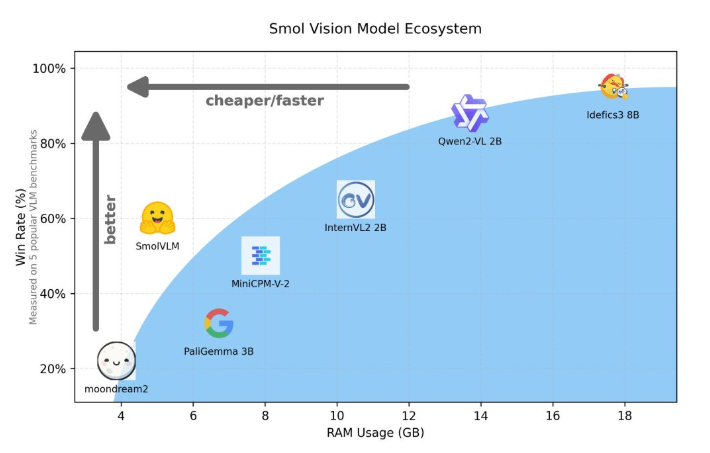
ยกตัวอย่าง Qwen2-VL แม้ว่าจะมีประสิทธิภาพที่ยอดเยี่ยม แต่ก็มีข้อกำหนดด้านฮาร์ดแวร์ที่สูง ซึ่งจำกัดการใช้งานในแอปพลิเคชันแบบเรียลไทม์ ดังนั้นการพัฒนาโมเดลน้ำหนักเบาเพื่อให้ทำงานโดยใช้ทรัพยากรที่น้อยลงจึงกลายเป็นสิ่งจำเป็นที่สำคัญ
Hugging Face เพิ่งเปิดตัว SmolVLM ซึ่งเป็นโมเดลภาษาภาพพารามิเตอร์ 2B ที่ออกแบบมาเป็นพิเศษสำหรับการให้เหตุผลด้านอุปกรณ์ SmolVLM มีประสิทธิภาพเหนือกว่ารุ่นอื่นๆ ที่คล้ายคลึงกันในแง่ของการใช้หน่วยความจำ GPU และความเร็วในการสร้างโทเค็น คุณสมบัติหลักของมันคือความสามารถในการทำงานอย่างมีประสิทธิภาพบนอุปกรณ์ขนาดเล็ก เช่น แล็ปท็อปหรือ GPU ระดับผู้บริโภค โดยไม่ทำให้ประสิทธิภาพลดลง SmolVLM ค้นหาความสมดุลในอุดมคติระหว่างประสิทธิภาพและประสิทธิภาพ โดยแก้ไขปัญหาที่ยากจะเอาชนะในรุ่นที่คล้ายกันก่อนหน้านี้
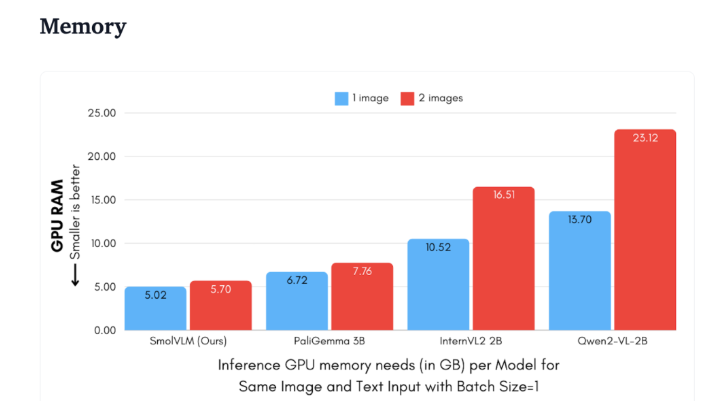
เมื่อเปรียบเทียบกับ Qwen2-VL2B แล้ว SmolVLM จะสร้างโทเค็นได้เร็วขึ้น 7.5 ถึง 16 เท่า ด้วยสถาปัตยกรรมที่ได้รับการปรับให้เหมาะสม ซึ่งทำให้การอนุมานแบบน้ำหนักเบาเป็นไปได้ ประสิทธิภาพนี้ไม่เพียงแต่นำประโยชน์เชิงปฏิบัติมาสู่ผู้ใช้เท่านั้น แต่ยังช่วยเพิ่มประสบการณ์ผู้ใช้อย่างมากอีกด้วย
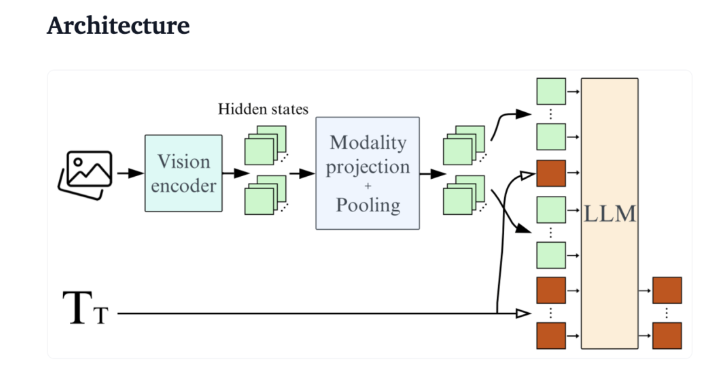
จากมุมมองทางเทคนิค SmolVLM มีสถาปัตยกรรมที่ได้รับการปรับให้เหมาะสมซึ่งรองรับการอนุมานฝั่งอุปกรณ์ที่มีประสิทธิภาพ ผู้ใช้ยังปรับแต่ง Google Colab อย่างละเอียดได้อย่างง่ายดาย ซึ่งช่วยลดเกณฑ์สำหรับการทดลองและพัฒนาได้อย่างมาก
เนื่องจากพื้นที่หน่วยความจำมีขนาดเล็ก SmolVLM จึงสามารถทำงานได้อย่างราบรื่นบนอุปกรณ์ที่ก่อนหน้านี้ไม่สามารถโฮสต์โมเดลที่คล้ายกันได้ เมื่อทดสอบวิดีโอ YouTube แบบ 50 เฟรม SmolVLM ทำงานได้ดี โดยได้คะแนน 27.14% และมีประสิทธิภาพเหนือกว่าโมเดลที่ต้องใช้ทรัพยากรอีกสองโมเดลในแง่ของการใช้ทรัพยากร ซึ่งแสดงให้เห็นถึงความสามารถในการปรับตัวและความยืดหยุ่นที่แข็งแกร่ง
SmolVLM เป็นก้าวสำคัญในด้านโมเดลภาษาภาพ การเปิดตัวดังกล่าวทำให้สามารถรันงานภาษาภาพที่ซับซ้อนบนอุปกรณ์ในชีวิตประจำวันได้ ซึ่งช่วยเติมเต็มช่องว่างที่สำคัญในเครื่องมือ AI ในปัจจุบัน
SmolVLM ไม่เพียงแต่เป็นเลิศในด้านความเร็วและประสิทธิภาพเท่านั้น แต่ยังมอบเครื่องมืออันทรงพลังให้กับนักพัฒนาและนักวิจัยเพื่ออำนวยความสะดวกในการประมวลผลภาษาภาพโดยไม่ต้องเสียค่าใช้จ่ายด้านฮาร์ดแวร์ราคาแพง ในขณะที่เทคโนโลยี AI ยังคงได้รับความนิยมมากขึ้น โมเดลอย่าง SmolVLM จะทำให้ความสามารถในการเรียนรู้ของเครื่องอันทรงพลังเข้าถึงได้ง่ายขึ้น
สาธิต:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
โดยรวมแล้ว SmolVLM ได้สร้างมาตรฐานใหม่สำหรับโมเดลภาษาภาพที่มีน้ำหนักเบา ประสิทธิภาพที่มีประสิทธิภาพและการใช้งานที่สะดวกจะส่งเสริมความนิยมและการพัฒนาเทคโนโลยี AI อย่างมาก เราหวังว่าจะมีนวัตกรรมที่คล้ายกันมากขึ้นในอนาคต ซึ่งจะทำให้เทคโนโลยี AI เป็นประโยชน์ต่อผู้คนมากขึ้น