บรรณาธิการของ Downcodes ได้เรียนรู้ว่า DeepSeek ซึ่งเป็นบริษัทในเครือของ Magic Square Quantitative ยักษ์ใหญ่ด้านไพรเวทอิควิตี้ของจีน เพิ่งเปิดตัวโมเดลภาษาขนาดใหญ่ที่เน้นการอนุมานล่าสุด R1-Lite-Preview ปัจจุบันโมเดลนี้เปิดให้บุคคลทั่วไปเข้าชมผ่านแพลตฟอร์มแชทบอทเว็บ DeepSeek Chat เท่านั้น และประสิทธิภาพของโมเดลได้รับความสนใจอย่างกว้างขวาง แม้จะเข้าใกล้หรือเกินกว่าโมเดลตัวอย่าง o1 ที่ OpenAI เปิดตัวเมื่อเร็วๆ นี้ก็ตาม DeepSeek มีชื่อเสียงในด้านการมีส่วนร่วมในระบบนิเวศ AI แบบโอเพ่นซอร์ส และการเปิดตัวครั้งนี้ยังคงมุ่งมั่นต่อการเข้าถึงและความโปร่งใส
DeepSeek ซึ่งเป็นบริษัทในเครือของบริษัทไพรเวทอิควิตี้ยักษ์ใหญ่ของจีน Huifang Quantitative เพิ่งเปิดตัวโมเดลภาษาขนาดใหญ่ล่าสุดที่เน้นการอนุมาน R1-Lite-Preview ขณะนี้โมเดลนี้มีให้บริการแก่สาธารณะผ่าน DeepSeek Chat ซึ่งเป็นแพลตฟอร์มแชทบอทบนเว็บเท่านั้น

DeepSeek เป็นที่รู้จักในด้านการมีส่วนร่วมเชิงนวัตกรรมต่อระบบนิเวศ AI แบบโอเพ่นซอร์ส และการเปิดตัวใหม่นี้มีจุดมุ่งหมายเพื่อนำความสามารถในการอนุมานระดับสูงมาสู่สาธารณะ ขณะเดียวกันก็รักษาความมุ่งมั่นในการเข้าถึงและความโปร่งใส แม้ว่าปัจจุบัน R1-Lite-Preview จะใช้งานได้เฉพาะในแอปพลิเคชันแชทเท่านั้น แต่ก็ได้รับความสนใจอย่างกว้างขวางด้วยประสิทธิภาพที่ใกล้เคียงหรือเกินกว่าโมเดล o1-preview ของ OpenAI ที่เพิ่งเปิดตัวเมื่อเร็วๆ นี้
R1-Lite-Preview ใช้การให้เหตุผลแบบ "การคิดแบบลูกโซ่" ซึ่งสามารถแสดงกระบวนการคิดต่างๆ ที่ต้องเผชิญเมื่อตอบคำถามของผู้ใช้
แม้ว่าห่วงโซ่ความคิดบางอย่างอาจดูไร้สาระหรือผิดสำหรับมนุษย์ แต่โดยรวมแล้วคำตอบของ R1-Lite-Preview นั้นแม่นยำมากและยังสามารถแก้ไข "กับดัก" ที่พบในโมเดล AI ที่ทรงพลังแบบดั้งเดิมบางรุ่น เช่น GPT-4o และ Claude series ” คำถาม เช่น คำว่า “สตรอเบอรี่” มีกี่ R’s “อันไหนใหญ่กว่ากัน 9.11 หรือ 9.9?”
จากข้อมูลของ DeepSeek โมเดลดังกล่าวมีความเป็นเลิศในงานที่ต้องใช้เหตุผลเชิงตรรกะ การคิดทางคณิตศาสตร์ และการแก้ปัญหาแบบเรียลไทม์ ประสิทธิภาพเกินระดับ OpenAI o1-preview ในการวัดประสิทธิภาพที่กำหนดไว้ เช่น AIME (American Invitational Mathematics Examination) และ MATH

นอกจากนี้ DeepSeek ยังเผยแพร่ข้อมูลเพิ่มเติมเกี่ยวกับโมเดล ซึ่งแสดงให้เห็นถึงการปรับปรุงความแม่นยำอย่างต่อเนื่องเมื่อโมเดลมีเวลามากขึ้น หรือ "โทเค็นการคิด" เพื่อแก้ไขปัญหา แผนภูมิเน้นว่าเมื่อความลึกของการคิดเพิ่มขึ้น คะแนนของแบบจำลองในเกณฑ์มาตรฐาน เช่น AIME จะดีขึ้น
R1-Lite-Preview รุ่นปัจจุบันทำงานได้ดีในเกณฑ์มาตรฐานหลัก โดยสามารถจัดการงานต่างๆ ได้ตั้งแต่คณิตศาสตร์ที่ซับซ้อนไปจนถึงสถานการณ์ลอจิก โดยมีคะแนนเทียบได้กับโมเดลการอนุมานชั้นนำ เช่น GPQA และ Codeforces กระบวนการให้เหตุผลอย่างโปร่งใสของแบบจำลองทำให้ผู้ใช้สามารถสังเกตขั้นตอนเชิงตรรกะได้แบบเรียลไทม์ ช่วยเพิ่มความรู้สึกรับผิดชอบและความน่าเชื่อถือของระบบ
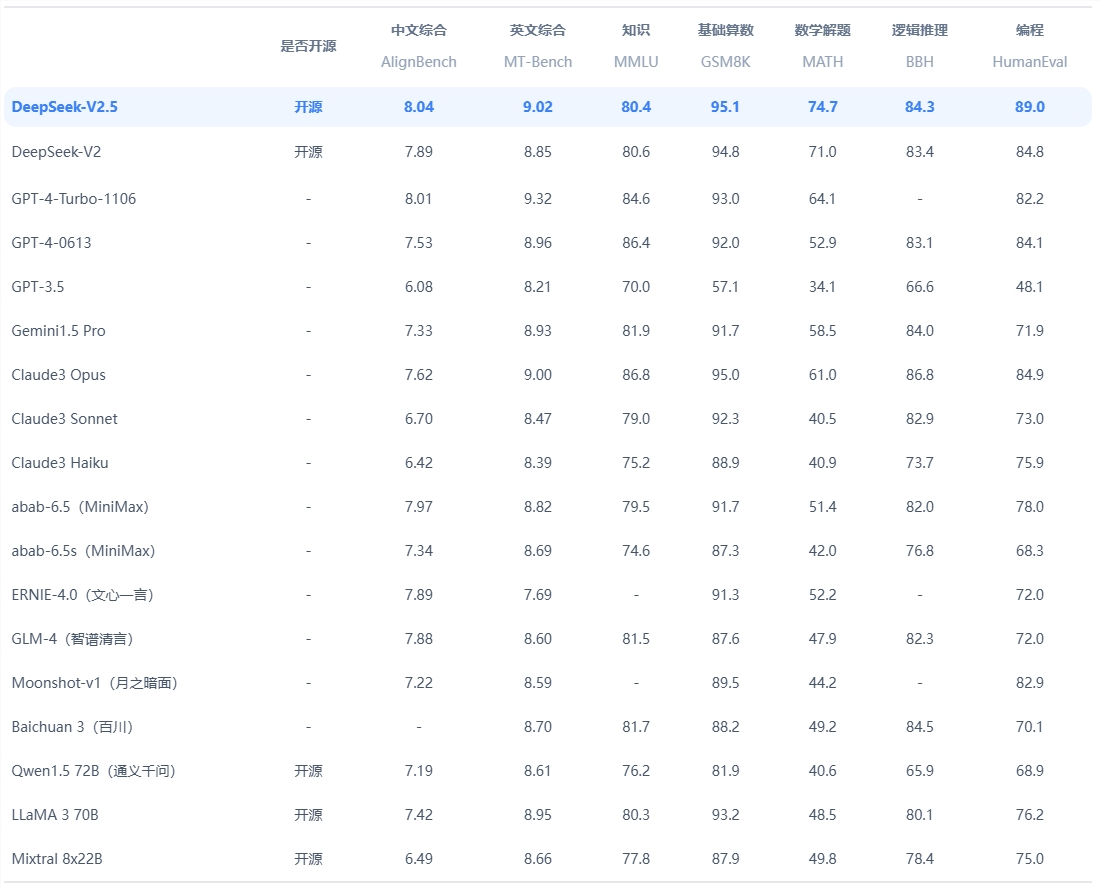
เป็นที่น่าสังเกตว่า DeepSeek ยังไม่ได้เผยแพร่โค้ดที่สมบูรณ์สำหรับการวิเคราะห์หรือการเปรียบเทียบโดยบุคคลที่สาม และไม่ได้จัดเตรียมอินเทอร์เฟซ API สำหรับการทดสอบอิสระ นอกจากนี้ บริษัทยังไม่ได้เผยแพร่บล็อกโพสต์หรือเอกสารทางเทคนิคที่เกี่ยวข้องซึ่งอธิบายการฝึกอบรมหรือการทดสอบ โครงสร้าง R1-Lite-Preview ซึ่งทำให้ต้นกำเนิดเบื้องหลังยังคงเต็มไปด้วยความสงสัย
ขณะนี้ R1-Lite-Preview ให้บริการฟรีผ่าน DeepSeek Chat (chat.deepseek.com) แต่โหมด "คิดลึก" ขั้นสูงนั้นจำกัดอยู่ที่ 50 ข้อความต่อวัน ทำให้ผู้ใช้สามารถสัมผัสประสบการณ์ความสามารถอันทรงพลังของมันได้ DeepSeek วางแผนที่จะเปิดตัวโมเดลซีรีส์ R1 เวอร์ชันโอเพนซอร์สและ API ที่เกี่ยวข้อง เพื่อรองรับการพัฒนาชุมชน AI แบบโอเพ่นซอร์สเพิ่มเติม
DeepSeek ยังคงขับเคลื่อนนวัตกรรมในพื้นที่ AI แบบโอเพนซอร์ส และการเปิดตัว R1-Lite-Preview จะเพิ่มมิติใหม่ให้กับการอนุมานและความสามารถในการปรับขนาด ในขณะที่ธุรกิจและนักวิจัยสำรวจแอปพลิเคชันสำหรับ AI ที่ใช้การอนุมานเข้มข้น ความมุ่งมั่นของ DeepSeek ในด้านการเปิดกว้างจะทำให้มั่นใจได้ว่าแบบจำลองจะกลายเป็นทรัพยากรสำคัญสำหรับการพัฒนาและนวัตกรรม
ทางเข้าอย่างเป็นทางการ: https://www.deepseek.com/
โดยรวมแล้ว R1-Lite-Preview แสดงให้เห็นถึงจุดแข็งอันแข็งแกร่งของ DeepSeek ในด้านโมเดลภาษาขนาดใหญ่ และแผนโอเพ่นซอร์สก็คุ้มค่ากับการรอคอยเช่นกัน อย่างไรก็ตาม การขาดการเปิดเผยรหัสและเอกสารทางเทคนิคยังทำให้เกิดความลึกลับในรายละเอียดทางเทคนิคอีกด้วย บรรณาธิการของ Downcodes จะยังคงให้ความสนใจกับความคืบหน้าของ DeepSeek ต่อไป