การพัฒนาอย่างรวดเร็วของโมเดลภาษาขนาดใหญ่ (LLM) เป็นสิ่งที่น่าประทับใจ แต่การขยายขนาดของแบบจำลองนั้นไม่เพียงพอที่จะบรรลุความฉลาดของ AI ที่แท้จริง บรรณาธิการของ Downcodes เชื่อว่าการให้โมเดลมีความสามารถในการพัฒนาตนเองเพื่อให้สามารถเรียนรู้และปรับปรุงต่อไปในระหว่างขั้นตอนการอนุมานนั้นมีความสำคัญต่อการพัฒนา AI ในอนาคต บทความนี้จะสำรวจปัจจัยสำคัญในการพัฒนาตนเองของ AI - หน่วยความจำระยะยาว (LTM) และวิธีบรรลุความก้าวหน้าอย่างต่อเนื่องใน AI ผ่าน LTM
โมเดลภาษาขนาดใหญ่ (LLM) เช่น ซีรีส์ GPT ได้แสดงให้เห็นถึงความสามารถอันน่าทึ่งในการทำความเข้าใจภาษา การใช้เหตุผล และการวางแผนด้วยชุดข้อมูลขนาดใหญ่ และได้ไปถึงระดับที่เทียบได้กับมนุษย์ในงานที่ท้าทายต่างๆ การวิจัยส่วนใหญ่มุ่งเน้นไปที่การปรับปรุงโมเดลเหล่านี้เพิ่มเติมโดยการฝึกโมเดลเหล่านี้กับชุดข้อมูลขนาดใหญ่ โดยมีเป้าหมายเพื่อพัฒนาโมเดลพื้นฐานที่มีประสิทธิภาพมากขึ้น
อย่างไรก็ตาม แม้ว่าการฝึกอบรมโมเดลพื้นฐานที่มีประสิทธิภาพยิ่งขึ้นจะเป็นสิ่งสำคัญ แต่นักวิจัยเชื่อว่าการให้โมเดลมีความสามารถในการพัฒนาต่อไปในระหว่างขั้นตอนการอนุมาน ซึ่งก็คือการพัฒนาตนเองของ AI ก็มีความสำคัญต่อการพัฒนา AI เช่นกัน เมื่อเปรียบเทียบกับการใช้ข้อมูลขนาดใหญ่เพื่อฝึกโมเดล การพัฒนาตนเองอาจต้องการเพียงข้อมูลหรือการโต้ตอบที่จำกัดเท่านั้น
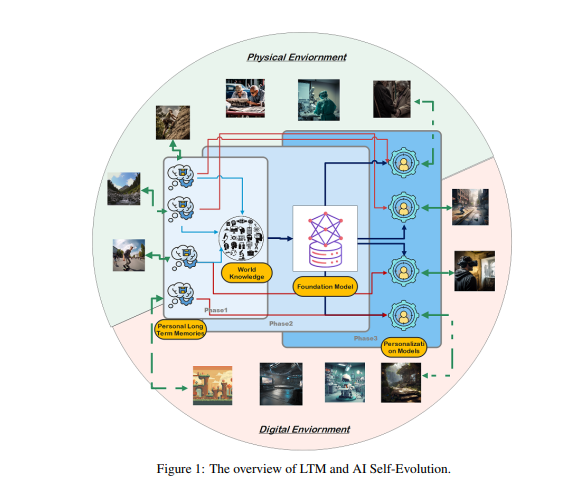
นักวิจัยตั้งสมมติฐานว่าแบบจำลอง AI สามารถพัฒนาความสามารถทางปัญญาที่เกิดขึ้นใหม่ได้ และสร้างแบบจำลองการเป็นตัวแทนภายในผ่านการโต้ตอบซ้ำกับสภาพแวดล้อมโดยได้รับแรงบันดาลใจจากโครงสร้างเรียงเป็นแนวของเปลือกสมองของมนุษย์
เพื่อให้บรรลุเป้าหมายนี้ นักวิจัยเสนอว่าแบบจำลองจะต้องมีหน่วยความจำระยะยาว (LTM) สำหรับจัดเก็บและจัดการข้อมูลปฏิสัมพันธ์ในโลกแห่งความเป็นจริงที่ประมวลผลแล้ว LTM ไม่เพียงแต่สามารถแสดงข้อมูลส่วนบุคคลแบบหางยาวในแบบจำลองทางสถิติเท่านั้น แต่ยังส่งเสริมการพัฒนาตนเองด้วยการสนับสนุนประสบการณ์ที่หลากหลายในสภาพแวดล้อมและตัวแทนต่างๆ
LTM เป็นกุญแจสำคัญในการตระหนักถึงการพัฒนาตนเองของ AI เช่นเดียวกับวิธีที่มนุษย์เรียนรู้และปรับปรุงอย่างต่อเนื่องผ่านประสบการณ์ส่วนตัวและการโต้ตอบกับสิ่งแวดล้อม การพัฒนาตนเองของโมเดล AI ยังอาศัยข้อมูล LTM ที่สะสมระหว่างการโต้ตอบอีกด้วย แตกต่างจากวิวัฒนาการของมนุษย์ วิวัฒนาการของแบบจำลองที่ขับเคลื่อนด้วย LTM ไม่ได้จำกัดอยู่เพียงการโต้ตอบในโลกแห่งความเป็นจริง โมเดลสามารถโต้ตอบกับสภาพแวดล้อมทางกายภาพเช่นเดียวกับมนุษย์ และรับผลตอบรับโดยตรง ซึ่งได้รับการประมวลผลเพื่อเพิ่มขีดความสามารถของพวกเขา นี่ยังเป็นพื้นที่การวิจัยที่สำคัญใน AI ที่เป็นตัวเป็นตน
ในทางกลับกัน โมเดลยังสามารถโต้ตอบในสภาพแวดล้อมเสมือนจริงและสะสมข้อมูล LTM ซึ่งมีต้นทุนที่ต่ำกว่าและมีประสิทธิภาพมากกว่าการโต้ตอบในโลกแห่งความเป็นจริง จึงช่วยเพิ่มขีดความสามารถได้อย่างมีประสิทธิภาพมากขึ้น
การสร้าง LTM จำเป็นต้องมีการปรับปรุงและจัดโครงสร้างข้อมูลดิบ ข้อมูลดิบหมายถึงการรวบรวมข้อมูลที่ยังไม่ได้ประมวลผลทั้งหมดที่โมเดลได้รับผ่านการโต้ตอบกับสภาพแวดล้อมภายนอกหรือระหว่างกระบวนการฝึกอบรม ข้อมูลเหล่านี้ประกอบด้วยข้อสังเกตและบันทึกที่หลากหลาย ซึ่งอาจประกอบด้วยรูปแบบที่มีคุณค่าและข้อมูลซ้ำซ้อนหรือไม่เกี่ยวข้องจำนวนมาก
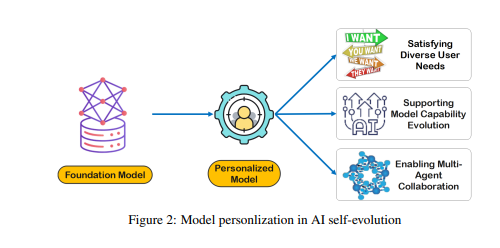
แม้ว่าข้อมูลดิบจะเป็นพื้นฐานของหน่วยความจำโมเดลและการรับรู้ แต่จำเป็นต้องมีการประมวลผลเพิ่มเติมก่อนจึงจะสามารถนำมาใช้เพื่อการปรับแต่งส่วนบุคคลหรือการดำเนินงานที่มีประสิทธิภาพได้อย่างมีประสิทธิภาพ LTM ปรับแต่งและจัดโครงสร้างข้อมูลดิบเหล่านี้เพื่อให้โมเดลสามารถใช้งานได้ กระบวนการนี้ช่วยเพิ่มความสามารถของแบบจำลองในการให้คำตอบและคำแนะนำเฉพาะบุคคล
การสร้าง LTM เผชิญกับความท้าทาย เช่น ความกระจัดกระจายของข้อมูลและความหลากหลายของผู้ใช้ ในระบบ LTM ที่อัปเดตอย่างต่อเนื่อง ความกระจัดกระจายของข้อมูลเป็นปัญหาที่พบบ่อย โดยเฉพาะอย่างยิ่งสำหรับผู้ใช้ที่มีประวัติการโต้ตอบที่จำกัดหรือมีกิจกรรมกระจัดกระจาย ซึ่งทำให้การฝึกโมเดลทำได้ยาก นอกจากนี้ ความหลากหลายของผู้ใช้ยังเพิ่มความซับซ้อน โดยกำหนดให้โมเดลต้องปรับให้เข้ากับรูปแบบของแต่ละบุคคลและสรุปอย่างมีประสิทธิภาพในกลุ่มผู้ใช้ที่แตกต่างกัน
นักวิจัยได้พัฒนากรอบการทำงานร่วมกันหลายตัวแทนที่เรียกว่า Omne ซึ่งใช้การพัฒนาตนเองของ AI บน LTM ในเฟรมเวิร์กนี้ เอเจนต์แต่ละตัวมีโครงสร้างระบบที่เป็นอิสระ และสามารถเรียนรู้และจัดเก็บแบบจำลองสภาพแวดล้อมที่สมบูรณ์ได้โดยอัตโนมัติ เพื่อสร้างความเข้าใจที่เป็นอิสระเกี่ยวกับสภาพแวดล้อม ด้วยการพัฒนาความร่วมมือโดยใช้ LTM นี้ ระบบ AI สามารถปรับให้เข้ากับการเปลี่ยนแปลงพฤติกรรมของแต่ละบุคคลแบบเรียลไทม์ เพิ่มประสิทธิภาพการวางแผนงานและการดำเนินการ และส่งเสริมการพัฒนาตนเองของ AI ส่วนบุคคลและมีประสิทธิภาพต่อไป
กรอบงาน Omne คว้าอันดับหนึ่งในการทดสอบเกณฑ์มาตรฐาน GAIA ซึ่งพิสูจน์ศักยภาพมหาศาลของการใช้ประโยชน์จาก LTM เพื่อการพัฒนาตนเองของ AI และการแก้ปัญหาในโลกแห่งความเป็นจริง นักวิจัยเชื่อว่าการวิจัย LTM ที่ก้าวหน้ามีความสำคัญต่อการพัฒนาอย่างต่อเนื่องและการใช้เทคโนโลยี AI ในทางปฏิบัติ โดยเฉพาะอย่างยิ่งในแง่ของการพัฒนาตนเอง
โดยรวมแล้ว ความจำระยะยาวเป็นกุญแจสำคัญในการพัฒนาตนเองของ AI ซึ่งช่วยให้โมเดล AI สามารถเรียนรู้และปรับปรุงจากประสบการณ์เช่นเดียวกับมนุษย์ การสร้างและใช้ประโยชน์จาก LTM จำเป็นต้องเอาชนะความท้าทายต่างๆ เช่น ความกระจัดกระจายของข้อมูล และความหลากหลายของผู้ใช้ เฟรมเวิร์ก Omne มอบโซลูชันที่เป็นไปได้สำหรับการพัฒนาตนเองของ AI ที่ใช้ LTM และความสำเร็จในการทดสอบเกณฑ์มาตรฐาน GAIA แสดงให้เห็นถึงศักยภาพมหาศาลในสาขานี้
บทความ: https://arxiv.org/pdf/2410.15665
ด้วยการวิจัยเกี่ยวกับความจำระยะยาว (LTM) การพัฒนาตนเองของ AI จึงไม่ใช่ความฝันที่ห่างไกลอีกต่อไป ในอนาคต โมเดล AI ที่ใช้ LTM คาดว่าจะแสดงให้เห็นถึงความสามารถที่ทรงพลังมากขึ้นในสาขาต่างๆ ที่กว้างขึ้น และนำประโยชน์มาสู่สังคมมนุษย์มากขึ้น รอคอยที่จะได้ผลลัพธ์ที่เป็นนวัตกรรมมากขึ้น!