ทีมวิจัย AI ของ Apple เปิดตัวตระกูลโมเดลภาษาขนาดใหญ่หลายรูปแบบรุ่นใหม่ MM1.5 ซึ่งสามารถผสานรวมข้อมูลหลายประเภท เช่น ข้อความและรูปภาพ และได้แสดงให้เห็นถึงประสิทธิภาพอันทรงพลังในงานต่างๆ เช่น การตอบคำถามด้วยภาพ การสร้างภาพ และมัลติ- ความสามารถในการตีความข้อมูลแบบกิริยา MM1.5 เอาชนะความยากลำบากของโมเดลหลายรูปแบบก่อนหน้านี้ในการประมวลผลรูปภาพที่มีข้อความมากมายและงานภาพที่ละเอียด ด้วยแนวทางที่เน้นข้อมูลเป็นศูนย์กลางที่เป็นนวัตกรรมใหม่ จะใช้ข้อมูล OCR ความละเอียดสูงและคำอธิบายรูปภาพสังเคราะห์เพื่อปรับปรุงประสิทธิภาพของโมเดลอย่างมีนัยสำคัญ . ความเข้าใจ เครื่องมือแก้ไข Downcodes จะทำให้คุณมีความเข้าใจเชิงลึกเกี่ยวกับนวัตกรรมของ MM1.5 และประสิทธิภาพที่ยอดเยี่ยมในการทดสอบเกณฑ์มาตรฐานหลายรายการ
เมื่อเร็วๆ นี้ ทีมวิจัย AI ของ Apple ได้เปิดตัวตระกูลโมเดลภาษาขนาดใหญ่ (MLLM) หลากหลายรูปแบบรุ่นใหม่ - MM1.5 โมเดลชุดนี้สามารถรวมข้อมูลได้หลายประเภท เช่น ข้อความและรูปภาพ แสดงให้เราเห็นความสามารถใหม่ของ AI ในการทำความเข้าใจงานที่ซับซ้อน งานต่างๆ เช่น การตอบคำถามด้วยภาพ การสร้างภาพ และการตีความข้อมูลหลายรูปแบบ ทั้งหมดนี้สามารถแก้ไขได้ดีขึ้นด้วยความช่วยเหลือของแบบจำลองเหล่านี้
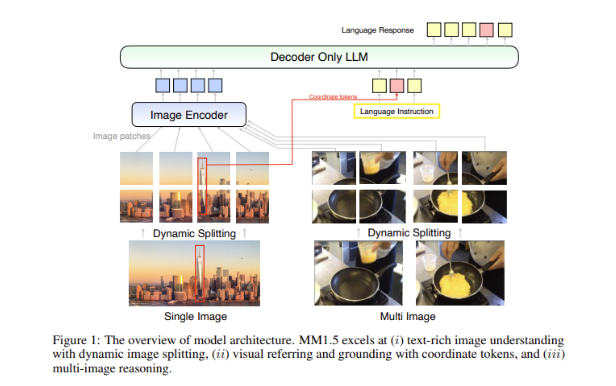
ความท้าทายที่ยิ่งใหญ่ในแบบจำลองหลายรูปแบบคือการบรรลุปฏิสัมพันธ์ที่มีประสิทธิภาพระหว่างข้อมูลประเภทต่างๆ โมเดลในอดีตมักประสบปัญหากับรูปภาพที่มีข้อความมากมายหรืองานการมองเห็นที่มีความละเอียด ดังนั้น ทีมวิจัยของ Apple จึงได้แนะนำวิธีการที่เน้นข้อมูลเป็นศูนย์กลางที่เป็นนวัตกรรมในโมเดล MM1.5 โดยใช้ข้อมูล OCR ความละเอียดสูงและคำอธิบายรูปภาพสังเคราะห์เพื่อเสริมสร้างความสามารถในการทำความเข้าใจของโมเดล
วิธีการนี้ไม่เพียงแต่ช่วยให้ MM1.5 เหนือกว่ารุ่นก่อนหน้าในการทำความเข้าใจด้วยภาพและการวางตำแหน่ง แต่ยังเปิดตัวรุ่นพิเศษสองเวอร์ชัน: MM1.5-Video และ MM1.5-UI ซึ่งใช้สำหรับการทำความเข้าใจและการวางตำแหน่งวิดีโอตามลำดับ . การวิเคราะห์อินเทอร์เฟซมือถือ
การฝึกรุ่น MM1.5 แบ่งออกเป็น 3 ระยะหลัก
ขั้นแรกคือการฝึกอบรมล่วงหน้าขนาดใหญ่ โดยใช้ข้อมูลรูปภาพและข้อความ 2 พันล้านคู่ เอกสารข้อความรูปภาพที่แทรก 600 ล้านรายการ และโทเค็นเฉพาะข้อความ 2 ล้านล้านรายการ
ขั้นตอนที่สองคือการปรับปรุงประสิทธิภาพของงานรูปภาพที่เต็มไปด้วยข้อความผ่านการฝึกอบรมล่วงหน้าอย่างต่อเนื่องสำหรับข้อมูล OCR คุณภาพสูง 45 ล้านรายการ และคำอธิบายสังเคราะห์ 7 ล้านรายการ
สุดท้าย ในขั้นตอนการปรับแต่งแบบละเอียดภายใต้การดูแล แบบจำลองจะได้รับการปรับให้เหมาะสมโดยใช้ข้อมูลภาพเดียว หลายภาพ และข้อความเท่านั้นที่เลือกสรรมาอย่างดี เพื่อปรับปรุงการอ้างอิงด้วยภาพโดยละเอียดและการใช้เหตุผลหลายภาพ
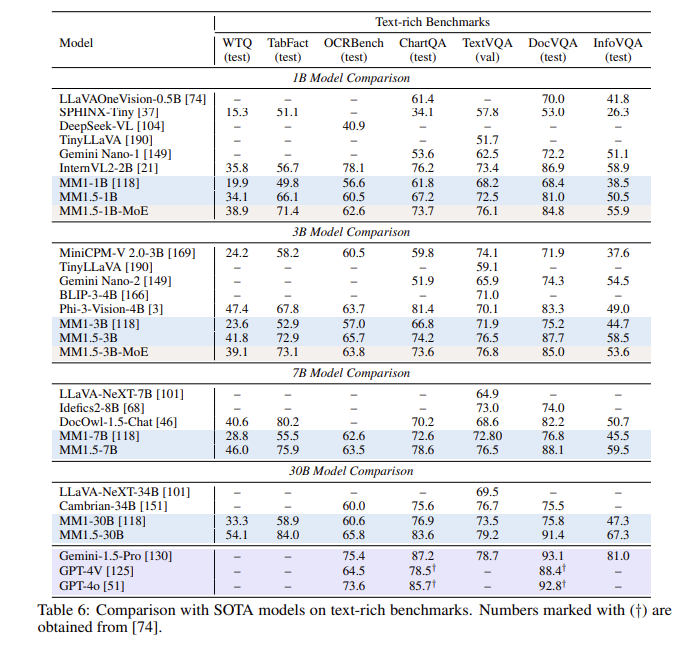
หลังจากการประเมินหลายครั้ง โมเดล MM1.5 ทำงานได้ดีในการทดสอบเกณฑ์มาตรฐานหลายรายการ โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับความเข้าใจรูปภาพที่มีข้อความมากมาย โดยมีการปรับปรุง 1.4 จุดจากรุ่นก่อนหน้า นอกจากนี้ แม้แต่ MM1.5-Video ซึ่งได้รับการออกแบบมาโดยเฉพาะสำหรับการทำความเข้าใจวิดีโอ ยังก้าวไปสู่ระดับชั้นนำในงานที่เกี่ยวข้องด้วยความสามารถหลายรูปแบบอันทรงพลัง
กลุ่มผลิตภัณฑ์รุ่น MM1.5 ไม่เพียงแต่สร้างมาตรฐานใหม่สำหรับโมเดลภาษาขนาดใหญ่แบบหลายรูปแบบเท่านั้น แต่ยังแสดงให้เห็นถึงศักยภาพในการใช้งานที่หลากหลาย ตั้งแต่การทำความเข้าใจข้อความรูปภาพทั่วไป ไปจนถึงการวิเคราะห์วิดีโอและอินเทอร์เฟซผู้ใช้ ทั้งหมดนี้ล้วนแต่มีประสิทธิภาพที่โดดเด่น
ไฮไลท์:
**รุ่นต่างๆ**: รวมรุ่นหนาแน่นและรุ่น MoE ที่มีพารามิเตอร์ตั้งแต่ 1 พันล้านถึง 30 พันล้าน ทำให้มั่นใจได้ถึงความสามารถในการปรับขนาดและการปรับใช้ที่ยืดหยุ่น
**ข้อมูลการฝึกอบรม**: ใช้คู่ข้อความรูปภาพ 2 พันล้านคู่ เอกสารข้อความรูปภาพแบบแทรก 600 ล้านรายการ และโทเค็นเฉพาะข้อความ 2 ล้านล้านรายการ
**การปรับปรุงประสิทธิภาพ**: ในการทดสอบเกณฑ์มาตรฐานที่เน้นการทำความเข้าใจรูปภาพที่มีข้อความมากมาย ได้รับการปรับปรุง 1.4 จุดเมื่อเทียบกับรุ่นก่อนหน้า
โดยรวมแล้วตระกูลโมเดล MM1.5 ของ Apple มีความก้าวหน้าอย่างมากในด้านโมเดลภาษาขนาดใหญ่แบบหลายโมดอล และวิธีการที่เป็นนวัตกรรมใหม่และประสิทธิภาพที่ยอดเยี่ยมจะมอบทิศทางใหม่สำหรับการพัฒนา AI ในอนาคต เราหวังเป็นอย่างยิ่งว่า MM1.5 จะแสดงศักยภาพในสถานการณ์การใช้งานอื่นๆ มากขึ้น