ในยุคแห่งการแพร่กระจายของข้อมูล การประมวลผลข้อมูลข้อความในภาพอย่างมีประสิทธิภาพถือเป็นสิ่งสำคัญ บรรณาธิการของ Downcodes จะแนะนำโมเดล OCR ที่ปฏิวัติวงการในวันนี้ - GOT (ทฤษฎีการรู้จำอักขระด้วยแสงทั่วไป) ซึ่งถือเป็นการเข้าสู่เทคโนโลยี OCR ในยุค 2.0 โมเดล GOT ผสมผสานข้อดีของ OCR แบบดั้งเดิมและโมเดลภาษาขนาดใหญ่ และนำความก้าวหน้าครั้งใหม่มาสู่ด้านการจดจำข้อความด้วยประสิทธิภาพอันทรงพลังและความคล่องตัว ไม่เพียงแต่จดจำเอกสารและข้อความฉากภาษาอังกฤษและจีนเท่านั้น แต่ยังจัดการข้อมูลที่ซับซ้อน เช่น สูตรทางคณิตศาสตร์และเคมี สัญลักษณ์เพลง แผนภูมิ ฯลฯ เรียกได้ว่าเป็น "ผู้เล่นรอบด้าน" ในด้าน OCR
ในยุคดิจิทัล การแปลงเนื้อหาข้อความในรูปภาพให้เป็นข้อความที่แก้ไขได้อย่างรวดเร็วถือเป็นข้อกำหนดทั่วไปและสำคัญ ขณะนี้ การมาถึงของโมเดลการรู้จำอักขระด้วยแสง (OCR) ใหม่ที่เรียกว่า GOT (ทฤษฎีการรู้จำอักขระด้วยแสงทั่วไป) ถือเป็นการเข้าสู่เทคโนโลยี OCR เข้าสู่ยุค 2.0 โมเดลที่เป็นนวัตกรรมนี้ผสมผสานข้อดีของระบบ OCR แบบดั้งเดิมและโมเดลภาษาขนาดใหญ่เพื่อสร้างเครื่องมือการรู้จำข้อความที่มีประสิทธิภาพและชาญฉลาดยิ่งขึ้น
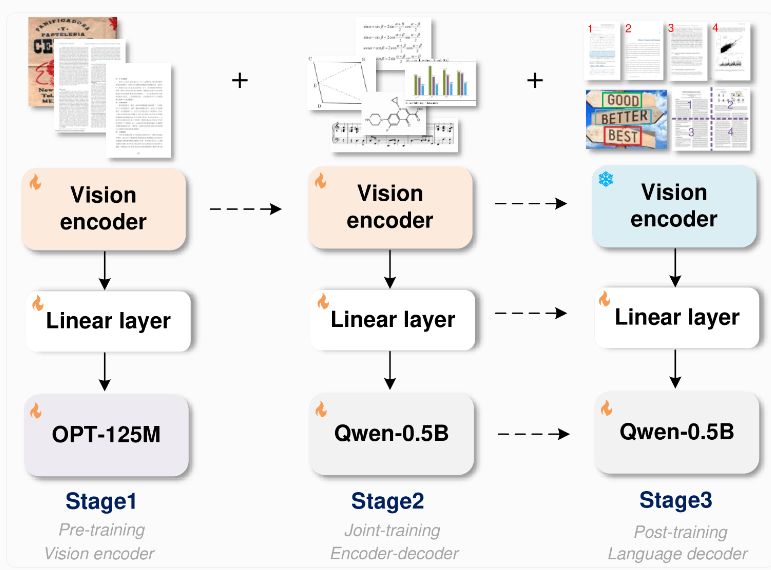
โมเดล GOT ใช้สถาปัตยกรรมแบบ end-to-end ที่เป็นนวัตกรรม การออกแบบนี้ไม่เพียงแต่ช่วยประหยัดทรัพยากร แต่ยังขยายความสามารถในการจดจำมากกว่าการจดจำข้อความอีกด้วย แบบจำลองประกอบด้วยตัวเข้ารหัสรูปภาพที่มีประมาณ 80 ล้านพารามิเตอร์ และตัวถอดรหัสที่มีประมาณ 5 ล้านพารามิเตอร์ ตัวเข้ารหัสรูปภาพสามารถบีบอัดรูปภาพที่มีขนาดสูงสุด 1024x1024 พิกเซลลงในหน่วยข้อมูล ในขณะที่ตัวถอดรหัสจะแปลงข้อมูลนี้เป็นข้อความที่มีความยาวสูงสุด 8000 อักขระ
พลังของ GOT อยู่ที่ความสามารถรอบด้าน ไม่เพียงแต่สามารถจดจำและแปลงเอกสารและข้อความฉากภาษาอังกฤษและจีนเท่านั้น แต่ยังประมวลผลสูตรทางคณิตศาสตร์และเคมี สัญลักษณ์เพลง รูปทรงเรขาคณิตอย่างง่าย และแผนภูมิต่างๆ สิ่งนี้ทำให้ GOT เป็นผู้รอบรู้ที่แท้จริง
เพื่อฝึกโมเดลนี้ ทีมวิจัยมุ่งเน้นไปที่งานการจดจำข้อความก่อน จากนั้นจึงใช้ Qwen-0.5B ของอาลีบาบาเป็นตัวถอดรหัส และปรับแต่งอย่างละเอียดด้วยข้อมูลสังเคราะห์ที่หลากหลาย พวกเขาใช้เครื่องมือเรนเดอร์ระดับมืออาชีพ เช่น LaTeX, Mathpix-markdown-it และ Matplotlib เพื่อสร้างคู่ข้อความรูปภาพหลายล้านคู่สำหรับการฝึกโมเดล

จุดเด่นอีกประการหนึ่งของเทคโนโลยี OCR2.0 คือความสามารถในการแยกข้อความที่จัดรูปแบบ ชื่อเรื่อง และแม้กระทั่งรูปภาพหลายหน้า แล้วแปลงเป็นรูปแบบดิจิทัลที่มีโครงสร้าง สิ่งนี้เปิดโอกาสใหม่ๆ สำหรับการประมวลผลและการวิเคราะห์อัตโนมัติในสาขาต่างๆ เช่น วิทยาศาสตร์ ดนตรี และการวิเคราะห์ข้อมูล
ในการทดสอบงาน OCR ต่างๆ GOT ได้แสดงให้เห็นถึงประสิทธิภาพที่ยอดเยี่ยม โดยบรรลุผลลัพธ์ระดับแนวหน้าของอุตสาหกรรมในการจดจำข้อความในเอกสารและฉาก และยังเหนือกว่าโมเดลมืออาชีพจำนวนมากและโมเดลภาษาขนาดใหญ่ในการจดจำแผนภูมิอีกด้วย ไม่ว่าจะเป็นสูตรโครงสร้างทางเคมีที่ซับซ้อน หรือโน้ตดนตรีและการแสดงข้อมูล OCR2.0 สามารถบันทึกและแปลงเป็นรูปแบบที่เครื่องอ่านได้อย่างแม่นยำ
เพื่อให้ผู้ใช้ได้สัมผัสและใช้เทคโนโลยีนี้มากขึ้น ทีมวิจัยจึงได้เผยแพร่การสาธิตและโค้ดฟรีบนแพลตฟอร์ม Hugging Face การมาถึงของ OCR2.0 ได้นำมาซึ่งการปฏิวัติด้านการประมวลผลข้อมูลอย่างไม่ต้องสงสัย ไม่เพียงปรับปรุงประสิทธิภาพ แต่ยังเพิ่มความยืดหยุ่น ทำให้เราสามารถประมวลผลข้อมูลข้อความในภาพได้ง่ายขึ้น
การเกิดขึ้นของโมเดล GOT ได้เพิ่มพลังใหม่ๆ ให้กับเทคโนโลยี OCR อย่างไม่ต้องสงสัย เราหวังว่าจะปรับปรุงโมเดล GOT ต่อไปในอนาคตและทำให้เราประหลาดใจมากขึ้น!