บรรณาธิการของ Downcodes จะพาคุณไปเรียนรู้เกี่ยวกับความก้าวหน้าครั้งสำคัญในด้านเทคโนโลยี OCR! เมื่อเร็วๆ นี้ นักวิจัยได้พัฒนาแบบจำลอง OCR ที่เรียกว่า GOT (ทฤษฎี OCR ทั่วไป) ซึ่งรู้จักกันในชื่อ "OCR2.0" โดยผสมผสานข้อดีของระบบ OCR แบบดั้งเดิมและแบบจำลองภาษาขนาดใหญ่เข้าด้วยกันอย่างชาญฉลาด และได้ผลลัพธ์ที่สำคัญในด้านความสามารถในการจดจำข้อความ . โมเดล GOT มีสถาปัตยกรรมที่ซับซ้อน ตัวเข้ารหัสและตัวถอดรหัสรูปภาพที่ทรงพลัง และสามารถประมวลผลข้อมูลภาพได้หลายประเภท
เมื่อเร็วๆ นี้ นักวิจัยได้พัฒนาโมเดลการรู้จำอักขระด้วยแสงสากล (OCR) ใหม่ที่เรียกว่า GOT (ทฤษฎี OCR ทั่วไป) ในรายงานของพวกเขา แนวคิดของ "OCR2.0" ได้รับการเสนอเป็นครั้งแรก โมเดลใหม่นี้มีจุดมุ่งหมายเพื่อรวมข้อดีของระบบ OCR แบบดั้งเดิมเข้ากับพลังของโมเดลภาษาขนาดใหญ่
สถาปัตยกรรมของ GOT ค่อนข้างล้ำหน้า รวมถึงตัวเข้ารหัสรูปภาพที่มีพารามิเตอร์ประมาณ 80 ล้านพารามิเตอร์ และตัวถอดรหัสที่มีพารามิเตอร์ 5 ล้านพารามิเตอร์ ตัวเข้ารหัสรูปภาพจะบีบอัดรูปภาพขนาด 1024x1024 พิกเซลให้เป็นโทเค็น และผู้ถอดรหัสมีหน้าที่ในการแปลงโทเค็นเหล่านี้เป็นข้อความที่มีความยาวสูงสุด 8000 อักขระ ด้วยวิธีนี้ โมเดล OCR2.0 จึงสามารถจัดการได้มากกว่าข้อความธรรมดา
ความงดงามของเทคโนโลยีใหม่นี้อยู่ที่ ความสามารถในการจดจำและแปลงข้อมูลภาพหลายประเภท รวมถึง ข้อความในฉากและข้อความในเอกสารเป็นภาษาอังกฤษและจีน สูตรทางคณิตศาสตร์และเคมี สัญลักษณ์ดนตรี รูปทรงเรขาคณิตอย่างง่าย และไดอะแกรมที่มีส่วนประกอบต่างๆ ฟังก์ชันการทำงานดังกล่าวนำมาซึ่งความเป็นไปได้ใหม่ๆ สำหรับการประมวลผลอัตโนมัติในสาขาต่างๆ เช่น วิทยาศาสตร์ ดนตรี และการวิเคราะห์ข้อมูลอย่างไม่ต้องสงสัย
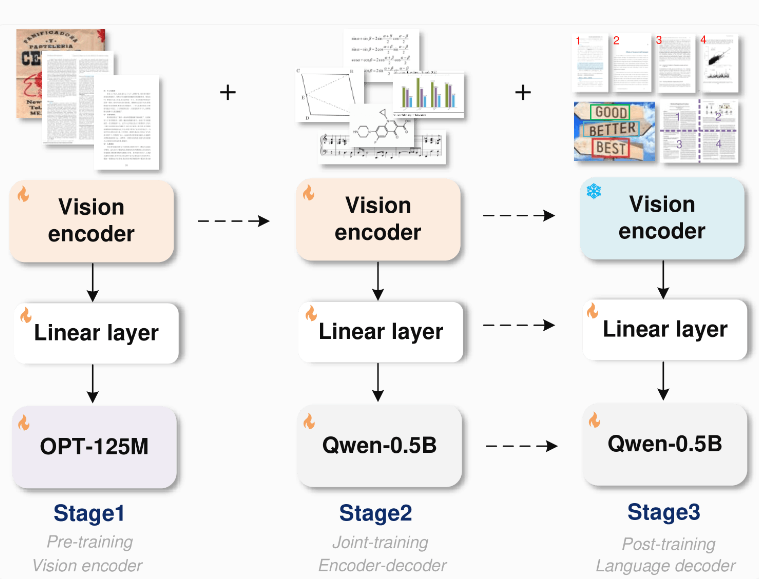
เพื่อเพิ่มประสิทธิภาพกระบวนการฝึกอบรม ขั้นแรกทีมวิจัยได้ฝึกอบรมตัวเข้ารหัสสำหรับงานการจดจำข้อความเท่านั้น จากนั้นจึงแนะนำ Qwen-0.5B ของอาลีบาบาเป็นตัวถอดรหัส และปรับแต่งแบบจำลองโดยใช้ข้อมูลสังเคราะห์ที่หลากหลาย พวกเขาสร้างข้อมูลการฝึกคู่รูปภาพและข้อความหลายล้านคู่โดยใช้เครื่องมือเรนเดอร์ เช่น LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib และ Pyecharts

การออกแบบแบบโมดูลาร์ของ GOT ช่วยให้สามารถขยายฟังก์ชันใหม่ๆ ได้อย่างยืดหยุ่นในอนาคต โดยไม่ต้องฝึกอบรมโมเดลทั้งหมดใหม่ การออกแบบนี้ช่วยปรับปรุงประสิทธิภาพการอัพเดตของระบบอย่างมาก นอกจากนี้ นักวิจัยกล่าวว่า GOT ทำงานได้ดีในงาน OCR ต่างๆ โดยเฉพาะอย่างยิ่งในการจดจำข้อความในเอกสารและฉาก และยังเหนือกว่าโมเดลวัตถุประสงค์พิเศษและโมเดลภาษาขนาดใหญ่บางรุ่นในการจดจำแผนภูมิอีกด้วย

เป็นที่น่าสังเกตว่าทีมวิจัยได้เปิดตัวเดโมและโค้ดของ GOT บน Hugging Face ฟรีให้ผู้อื่นได้นำไปใช้และพัฒนาต่อยอดแล้ว โมเดลใหม่นี้จะส่งเสริมการพัฒนาเทคโนโลยี OCR และเปิดโอกาสการใช้งานที่กว้างขึ้นอย่างไม่ต้องสงสัย
ทางเข้าสาธิต: https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo
ไฮไลท์:
? GOT (ทฤษฎี OCR ทั่วไป) คือโมเดล OCR ใหม่ที่ผสมผสานระบบ OCR แบบดั้งเดิมเข้ากับโมเดลภาษาขนาดใหญ่ที่เรียกว่า OCR2.0
? โมเดลนี้สามารถจดจำและแปลงข้อมูลภาพได้หลากหลาย รวมถึงข้อความ สูตร สัญลักษณ์เพลง และแผนภูมิ และสามารถใช้ได้กับหลากหลายสาขา
การออกแบบโมดูลาร์และการฝึกอบรมข้อมูลสังเคราะห์ทำให้ GOT มีความสามารถในการขยายที่ยืดหยุ่นและประสิทธิภาพที่ยอดเยี่ยมในงาน OCR หลายงาน
การเปิดตัวโมเดล GOT แบบโอเพ่นซอร์สจะช่วยเร่งนวัตกรรมของเทคโนโลยี OCR อย่างไม่ต้องสงสัย และนำโซลูชันการรู้จำข้อความที่ชาญฉลาดและมีประสิทธิภาพมากขึ้นมาสู่ทุกสาขาอาชีพ เราหวังว่าจะได้แสดงศักยภาพที่มากขึ้นในการใช้งานในอนาคต!