บรรณาธิการของ Downcodes ได้เรียนรู้ว่าการศึกษาที่ก้าวหน้าของมหาวิทยาลัยเยลเปิดเผยความลับของการฝึกอบรมโมเดล AI: ความซับซ้อนของข้อมูลไม่ได้สูงเท่าไหร่ก็ยิ่งดีเท่านั้น แต่มีสถานะ "ขอบแห่งความโกลาหล" ที่เหมาะสมที่สุด ทีมวิจัยใช้แบบจำลองหุ่นยนต์เซลลูล่าร์เพื่อทำการทดลองอย่างชาญฉลาด สำรวจผลกระทบของข้อมูลที่มีความซับซ้อนต่างกันต่อผลการเรียนรู้ของแบบจำลอง AI และได้ข้อสรุปที่สะดุดตา
ทีมวิจัยของมหาวิทยาลัยเยลเพิ่งเปิดเผยผลการวิจัยที่ก้าวล้ำ โดยเผยให้เห็นข้อค้นพบที่สำคัญในการฝึกอบรมโมเดล AI: ข้อมูลที่มีผลการเรียนรู้ AI ที่ดีที่สุดนั้นไม่ได้ง่ายกว่าหรือซับซ้อนกว่านี้ แต่มีระดับความซับซ้อนที่เหมาะสม - —สถานะที่เรียกว่า ขอบของความสับสนวุ่นวาย
ทีมวิจัยได้ทำการทดลองโดยใช้ออโตมาตะเซลลูลาร์ระดับประถมศึกษา (ECA) ซึ่งเป็นระบบง่ายๆ ซึ่งสถานะในอนาคตของแต่ละหน่วยจะขึ้นอยู่กับตัวมันเองและสถานะของสองหน่วยที่อยู่ติดกันเท่านั้น แม้จะมีความเรียบง่ายของกฎ แต่ระบบดังกล่าวสามารถสร้างรูปแบบที่หลากหลายตั้งแต่แบบง่ายไปจนถึงซับซ้อนสูง จากนั้นนักวิจัยได้ประเมินประสิทธิภาพของแบบจำลองภาษาเหล่านี้ในการให้เหตุผลและการทำนายการเคลื่อนที่ของหมากรุก
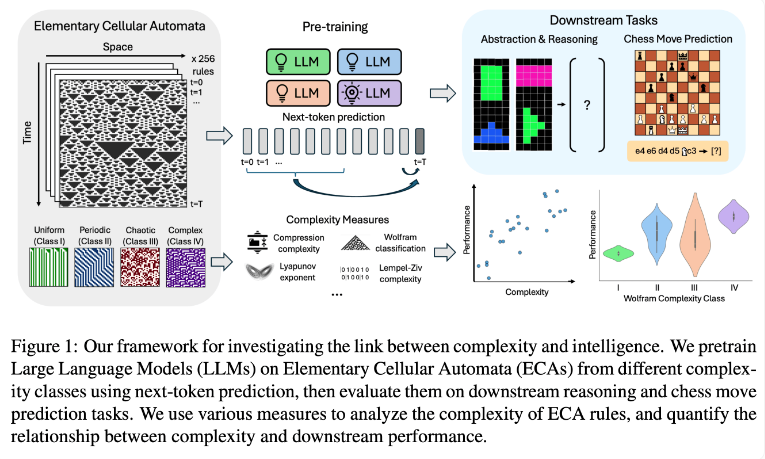
ผลการวิจัยแสดงให้เห็นว่าโมเดล AI ที่ได้รับการฝึกอบรมเกี่ยวกับกฎ ECA ที่ซับซ้อนยิ่งขึ้นจะทำงานได้ดีขึ้นในงานต่อๆ ไป โดยเฉพาะอย่างยิ่ง โมเดลที่ได้รับการฝึกอบรมเกี่ยวกับ Class IV ECAs ใน Wolfram Classification แสดงให้เห็นประสิทธิภาพที่ดีที่สุด รูปแบบที่สร้างโดยกฎดังกล่าวไม่ได้เรียงลำดับอย่างสมบูรณ์หรือวุ่นวายโดยสิ้นเชิง แต่แสดงให้เห็นถึงความซับซ้อนเชิงโครงสร้าง
นักวิจัยพบว่าเมื่อแบบจำลองสัมผัสกับรูปแบบที่เรียบง่ายเกินไป พวกเขามักจะเรียนรู้เพียงวิธีแก้ปัญหาง่ายๆ เท่านั้น ในทางตรงกันข้าม โมเดลที่ได้รับการฝึกในรูปแบบที่ซับซ้อนมากขึ้นจะพัฒนาความสามารถในการประมวลผลที่ซับซ้อนมากขึ้น แม้ว่าจะมีโซลูชันง่ายๆ ก็ตาม ทีมวิจัยคาดการณ์ว่าความซับซ้อนของการนำเสนอการเรียนรู้นี้เป็นปัจจัยสำคัญในความสามารถของแบบจำลองในการถ่ายทอดความรู้ไปยังงานอื่นๆ
การค้นพบนี้อาจอธิบายได้ว่าทำไมโมเดลภาษาขนาดใหญ่ เช่น GPT-3 และ GPT-4 จึงมีประสิทธิภาพมาก นักวิจัยเชื่อว่าข้อมูลจำนวนมากและหลากหลายที่ใช้ในการฝึกอบรมแบบจำลองเหล่านี้อาจสร้างผลกระทบที่คล้ายคลึงกับรูปแบบ ECA ที่ซับซ้อนในการศึกษาของพวกเขา
งานวิจัยนี้ให้แนวคิดใหม่ๆ สำหรับการฝึกฝนโมเดล AI และมุมมองใหม่ในการทำความเข้าใจความสามารถอันทรงพลังของโมเดลภาษาขนาดใหญ่ ในอนาคต บางทีเราอาจสามารถปรับปรุงประสิทธิภาพและความสามารถทั่วไปของโมเดล AI ได้อีกโดยการควบคุมความซับซ้อนของข้อมูลการฝึกอบรมได้แม่นยำยิ่งขึ้น บรรณาธิการของ Downcodes เชื่อว่าผลการวิจัยนี้จะมีผลกระทบอย่างมากต่อสาขาปัญญาประดิษฐ์